
TinyChatEngine: 让大语言模型在边缘设备上高效运行
在人工智能快速发展的今天,大语言模型(Large Language Models, LLMs)已经展现出了惊人的能力。然而,这些模型通常需要强大的计算资源,难以在边缘设备上运行。为了解决这个问题,MIT HAN实验室开发了TinyChatEngine,这是一个专为边缘设备设计的高效LLM推理库。本文将深入介绍TinyChatEngine的特点、技术创新以及应用前景。
TinyChatEngine的诞生背景
随着人工智能技术的普及,人们越来越希望在日常使用的设备上直接运行大语言模型,比如在笔记本电脑上实现代码自动补全,在汽车上提供智能语音助手,或是在机器人上实现视觉语言交互等。这些应用场景都要求模型能够在边缘设备上高效运行,以提供即时响应并保护用户隐私。
然而,边缘设备通常面临着计算能力有限、内存受限等挑战。以NVIDIA Jetson Orin Nano为例,其8GB内存甚至无法完整加载最小的LLaMA-2模型。此外,边缘设备的功耗限制也使得直接运行大型语言模型变得困难。
正是在这样的背景下,TinyChatEngine应运而生。它旨在通过创新的模型压缩和优化技术,让大语言模型能够在边缘设备上高效运行,为用户带来更好的体验。
TinyChatEngine的核心特性
- 高效推理
TinyChatEngine采用了多项优化技术,大大提高了模型的推理效率。例如,在NVIDIA Jetson Orin上,它能够以每秒30个token的速度运行Meta最新的LLaMA-2模型,这对于边缘设备来说是相当impressive的性能。
- 多平台支持
TinyChatEngine支持多种硬件平台,包括:
- x86架构(Intel/AMD CPU)
- ARM架构(Apple M1/M2, Raspberry Pi)
- NVIDIA GPU (包括服务器级和边缘级GPU)
这种广泛的平台支持使得开发者可以轻松地将TinyChatEngine部署到各种边缘设备上。
- 多种量化方法
TinyChatEngine支持多种模型量化方法,包括:
- FP32全精度
- W4A16 (4位权重, 16位激活)
- W4A32 (4位权重, 32位激活)
- W4A8 (4位权重, 8位激活)
- W8A8 (8位权重, 8位激活)
这些灵活的量化选项让开发者可以根据具体的硬件条件和性能需求选择最合适的方案。
- 丰富的模型支持
TinyChatEngine支持多种流行的大语言模型,包括:
- LLaMA系列(LLaMA-3, LLaMA-2等)
- CodeLLaMA系列
- Mistral-7B
- VILA-7B (视觉语言模型)
- LLaVA系列
- StarCoder
- OPT系列
这种广泛的模型支持使得TinyChatEngine可以应用于各种不同的场景。
- 易于使用
TinyChatEngine提供了简单直观的API,开发者可以轻松地将其集成到自己的项目中。同时,项目还提供了详细的文档和示例,帮助用户快速上手。

TinyChatEngine的技术创新
TinyChatEngine的高效性能背后是多项技术创新的结晶。以下是几个关键的技术亮点:
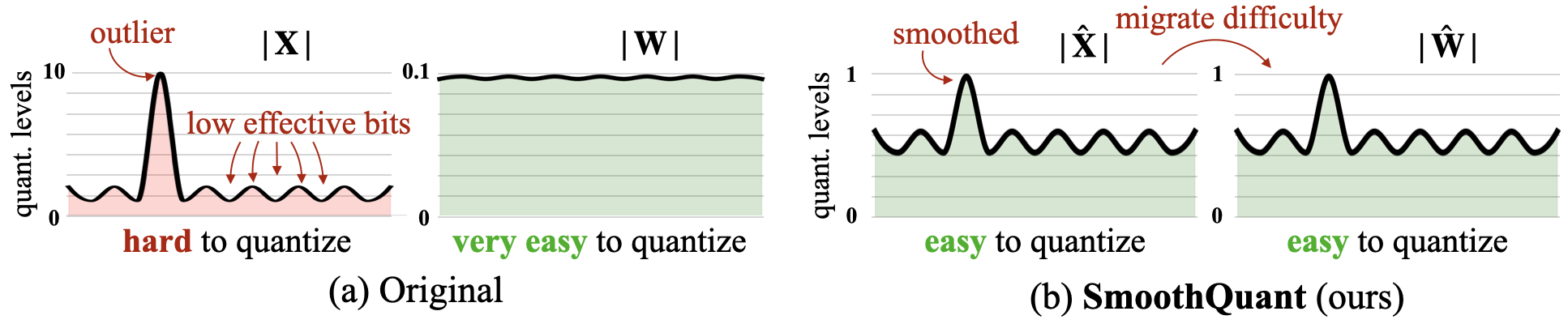
- SmoothQuant量化技术
SmoothQuant是一种创新的量化方法,它通过平滑激活值中的离群值,将量化难度从激活值转移到权重上。这种方法使得权重和激活值的量化都变得更加可行和高效。
- AWQ (Activation-aware Weight Quantization)
AWQ是另一项重要的量化技术,它通过分析激活值的幅度来识别关键的模型权重,而不是直接分析权重本身。这种方法能更好地保护重要的权重,有效降低量化误差。
- 设备特定的int4权重重排
为了减少运行时的权重重排开销,TinyChatEngine在模型转换阶段就进行了离线的权重重排。针对不同的硬件平台(如ARM和x86 CPU),TinyChatEngine采用了不同的权重布局,以优化SIMD操作的性能。
- 高效的CUDA实现
对于NVIDIA GPU,TinyChatEngine提供了高度优化的CUDA实现。例如,将MHA/GQA/MQA的所有操作融合到一个kernel中,将位置嵌入kernel融合到注意力kernel中,这些优化大大提高了GPU上的推理效率。
TinyChatEngine的应用示例
TinyChatEngine的灵活性和高效性使其可以应用于多种边缘AI场景。以下是几个典型的应用示例:
- 代码智能补全
在NVIDIA GeForce RTX 4070笔记本GPU上,TinyChatEngine可以流畅运行CodeLLaMA模型,为开发者提供实时的代码补全和建议。
- 视觉语言交互
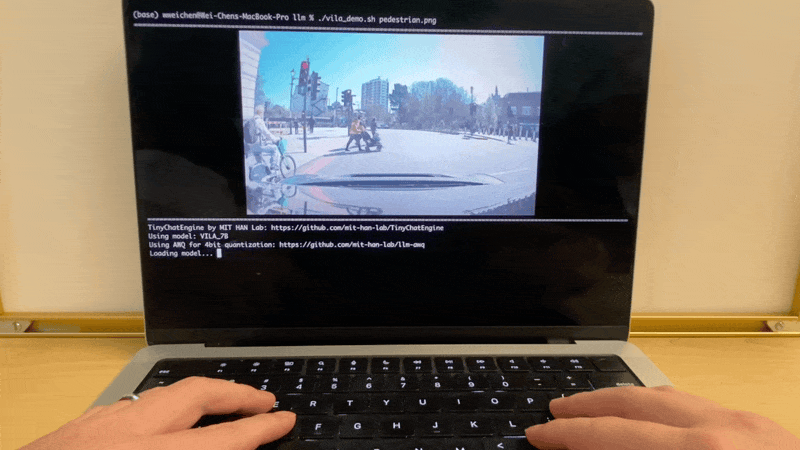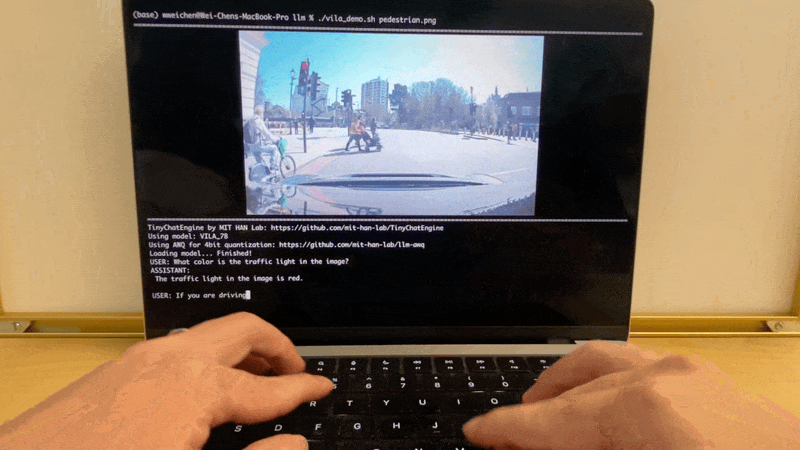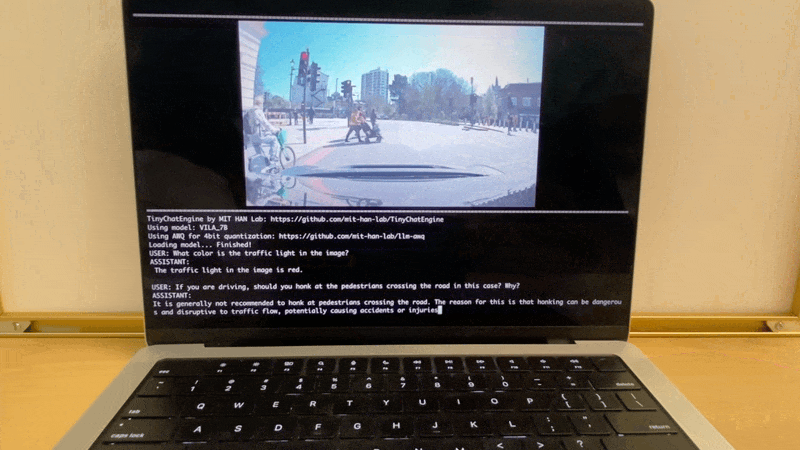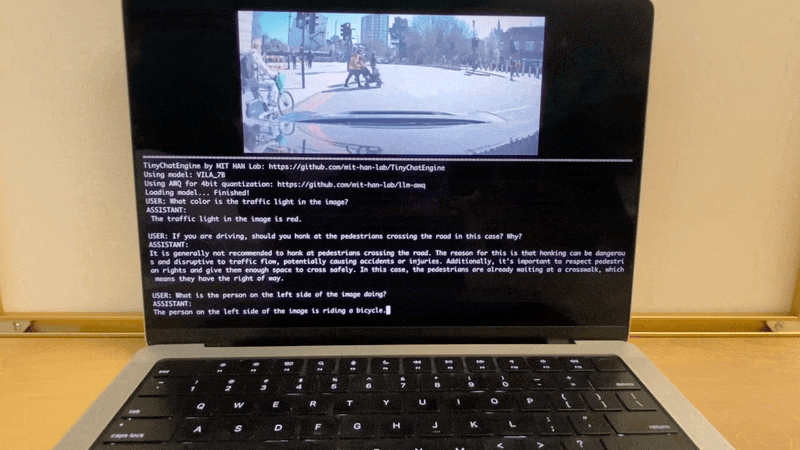
在Apple MacBook M1 Pro上,TinyChatEngine可以运行VILA (Visual Language) 模型,实现图像理解和自然语言交互。
- 智能对话助手
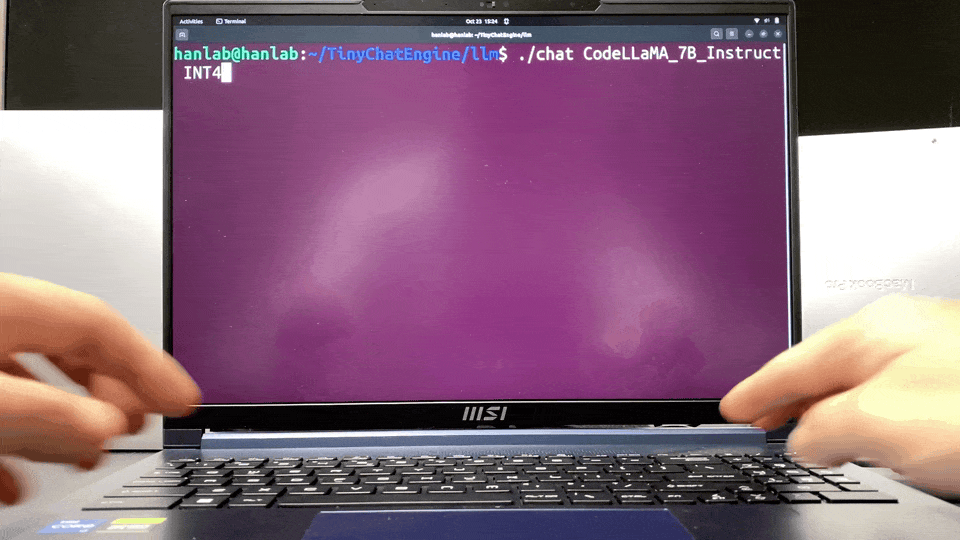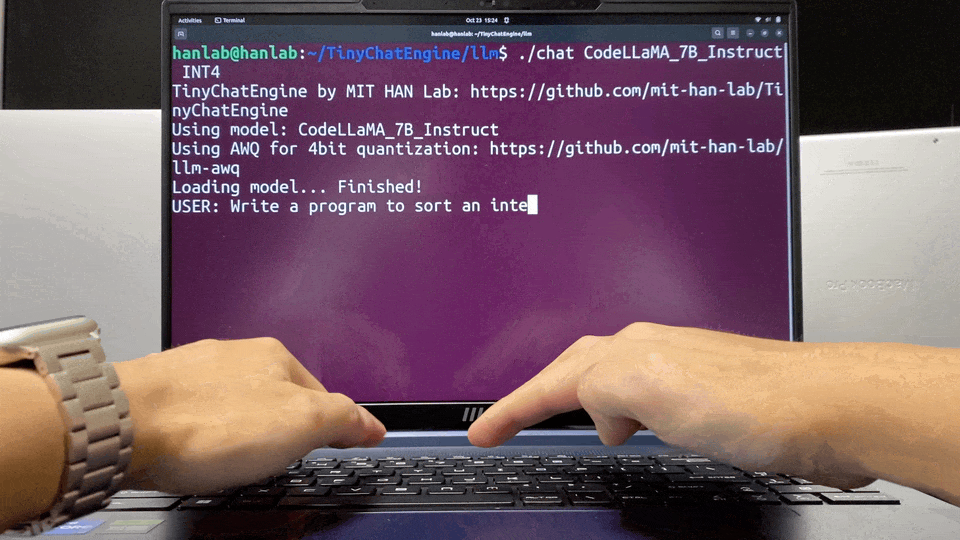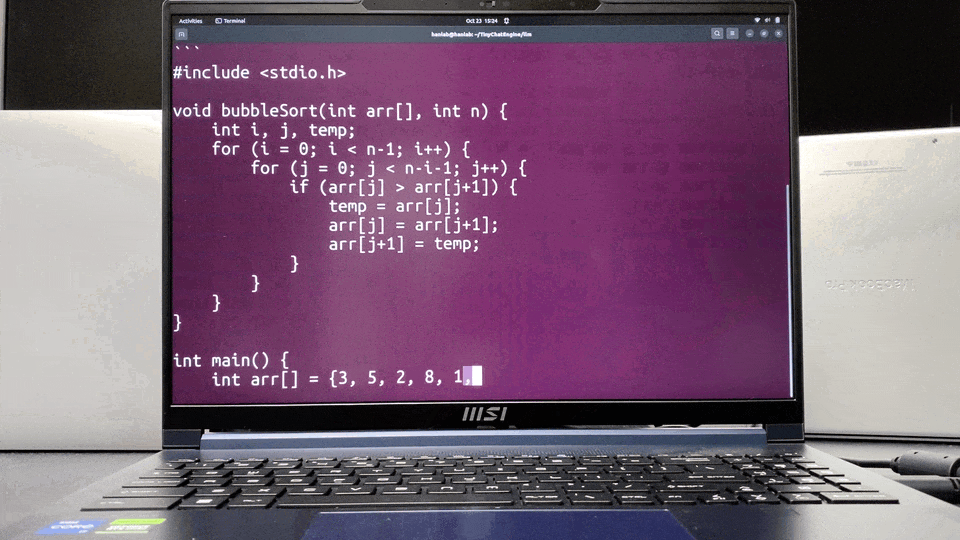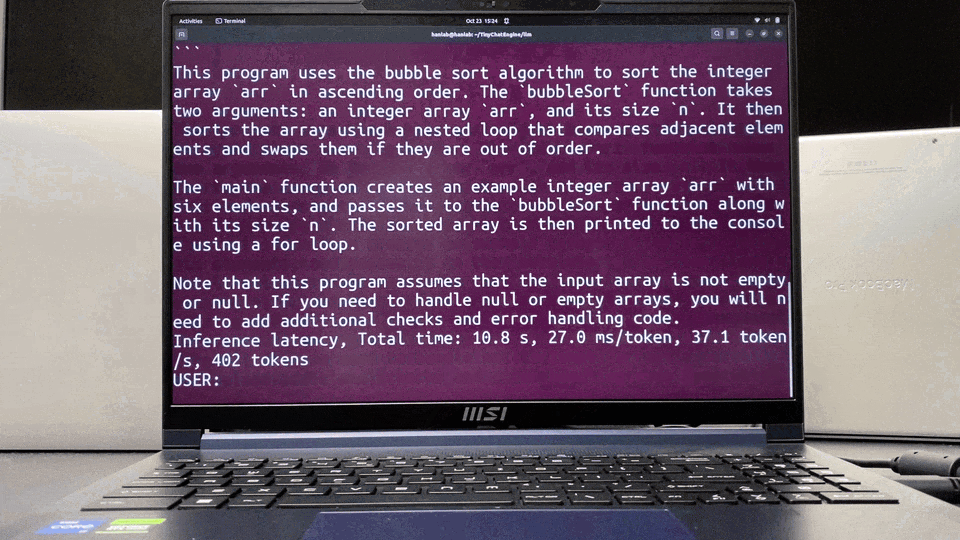
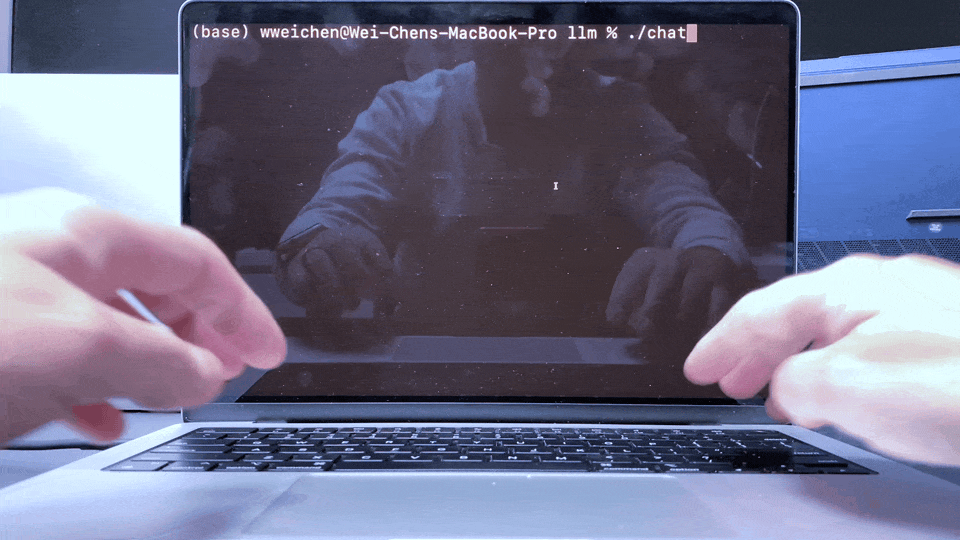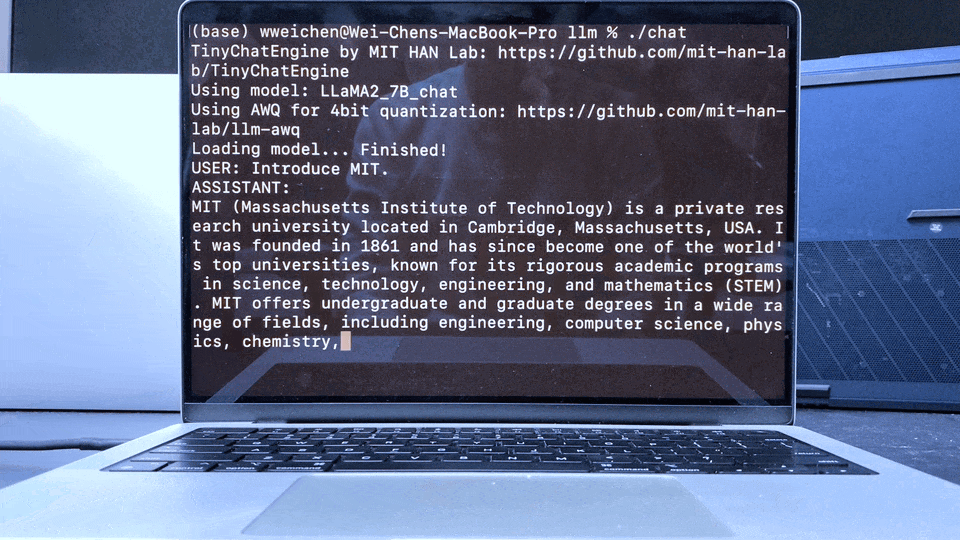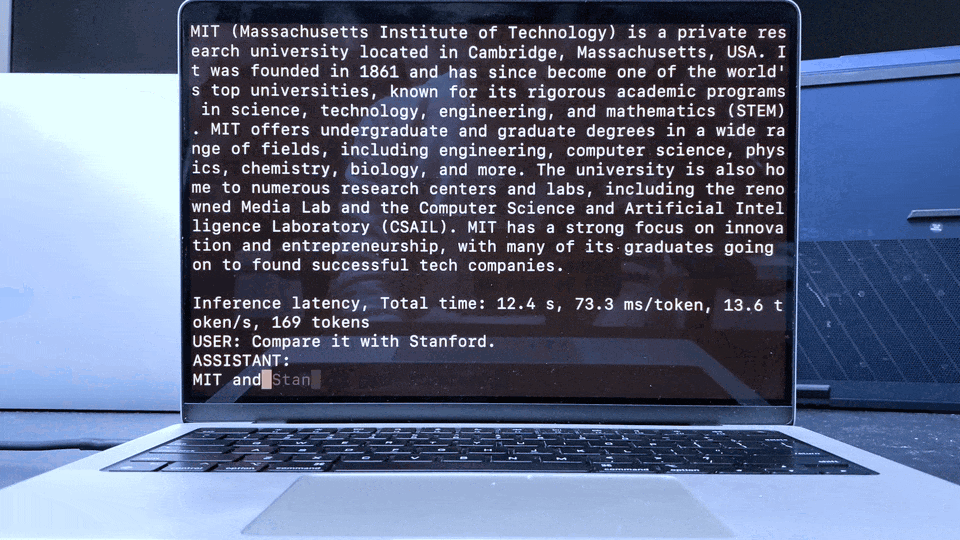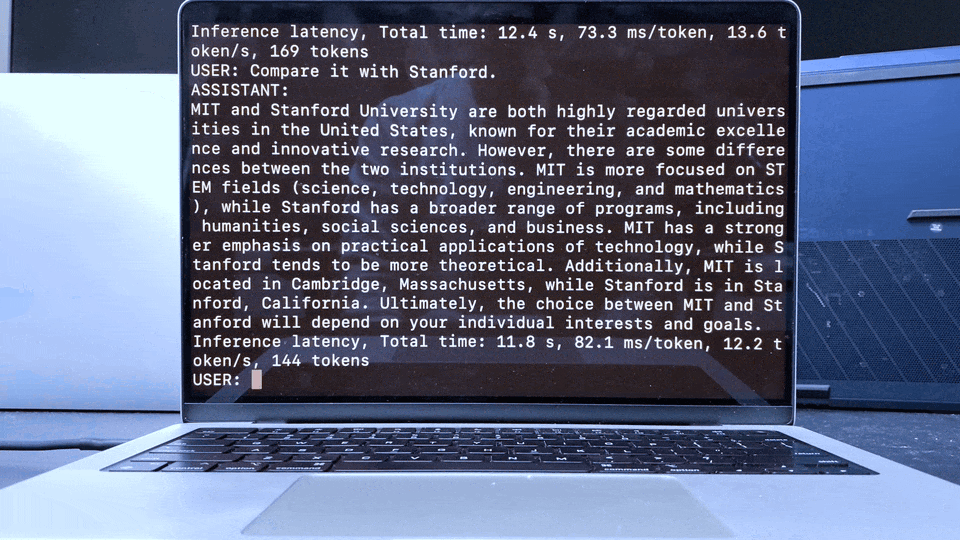
同样在Apple MacBook M1 Pro上,TinyChatEngine可以运行LLaMA Chat模型,提供流畅的对话体验。
TinyChatEngine的未来展望
随着边缘AI的不断发展,TinyChatEngine也在持续进化。未来,我们可以期待以下几个方面的发展:
- 支持更多模型和任务
除了目前支持的语言模型和视觉语言模型,TinyChatEngine有望扩展到更多类型的模型,如多模态模型、音频处理模型等。
- 进一步的性能优化
研究团队正在探索更先进的量化技术和推理优化方法,以在保持模型精度的同时进一步提高推理速度和降低资源消耗。
- 更广泛的硬件支持
除了目前支持的x86、ARM和NVIDIA GPU平台,TinyChatEngine有望扩展到更多的硬件平台,如专用的AI加速器等。
- 开发者工具的完善
为了让更多开发者能够轻松使用TinyChatEngine,项目团队可能会开发更多的工具和SDK,简化模型部署和应用开发的流程。
结语
TinyChatEngine为将大语言模型带到边缘设备开辟了一条创新之路。通过高效的推理引擎和先进的量化技术,它使得在资源受限的环境中运行复杂的AI模型成为可能。这不仅提升了用户体验,也为隐私保护和实时响应提供了新的解决方案。
随着TinyChatEngine的持续发展和完善,我们可以期待看到更多创新的边缘AI应用出现,从智能家居到工业物联网,从可穿戴设备到自动驾驶汽车,大语言模型的力量将无处不在。TinyChatEngine正在为AI的下一个前沿——边缘智能——铺平道路。
对于开发者和研究者来说,TinyChatEngine提供了一个绝佳的平台,用于探索和实现边缘AI的无限可能。无论您是想在自己的产品中集成AI功能,还是对边缘计算领域的最新进展感兴趣,TinyChatEngine都值得您深入了解和尝试。
让我们共同期待TinyChatEngine带来的更多惊喜,见证边缘AI的美好未来! 🚀🤖💡









