
TriForce: 革新长序列生成的无损加速技术
在人工智能和自然语言处理领域,大规模语言模型的出现带来了翻天覆地的变革。然而,这些模型在处理长序列时往往面临严重的效率瓶颈。为解决这一问题,研究人员开发出了名为TriForce的创新技术,通过层次化推测解码实现了长序列生成的无损加速。
TriForce的核心理念
TriForce的核心在于其独特的层次化推测解码框架。该框架巧妙地将长序列生成任务分解为多个层次,通过在不同层次上进行并行推测,大幅提高了解码效率。这种方法不仅保证了生成质量,还显著提升了处理速度。
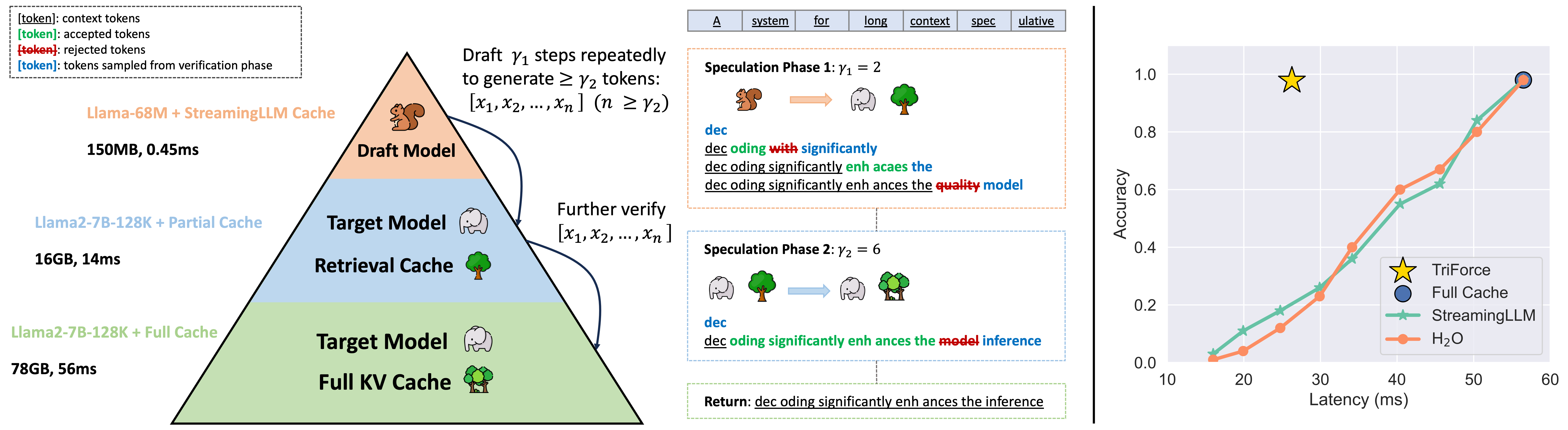
如上图所示,TriForce框架包含了多个关键组件,它们协同工作以实现高效的长序列生成:
- 检索缓存:存储并快速访问已生成的token信息。
- 层次化推测:在不同抽象层次上并行进行token预测。
- 验证机制:确保推测结果的准确性和一致性。
显著的性能提升
TriForce在各种硬件配置下都展现出了卓越的性能。在单个A100 GPU上,TriForce能够实现2.2倍的加速比。更令人印象深刻的是,在使用2个RTX 4090 GPU进行卸载(offloading)时,TriForce可以处理长达127K的上下文,这在以往是难以想象的。
# TriForce在2个RTX 4090 GPU上的示例配置
CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=48 torchrun --nproc_per_node=2
test/offloading_TP.py --budget 12288 --prefill 130048 --dataset gs
--target llama-7B-128K --on_chip 9 --gamma 16
这种性能提升不仅体现在纯粹的速度上,更重要的是它扩展了模型处理超长上下文的能力,为诸如长文档理解、复杂对话系统等应用场景开辟了新的可能性。
广泛的兼容性
TriForce目前支持多种长上下文Llama模型,包括:
这种广泛的兼容性使得TriForce可以在多种场景下发挥其加速效果,为研究人员和开发者提供了灵活的选择。
实际应用演示
为了直观展示TriForce的强大性能,研究团队提供了一个令人印象深刻的演示:
在这个演示中,TriForce成功地在2个RTX 4090 GPU上运行了LWM-Text-Chat-128K模型,处理了长达127K的上下文。这不仅展示了TriForce的技术实力,也为未来大规模语言模型在实际应用中的部署提供了可能性。
技术细节与实现
TriForce的实现涉及多个技术细节,包括:
- 张量并行化:支持多GPU协同工作,提高处理能力。
- 灵活的卸载策略:根据硬件配置调整on-chip层数。
- CUDA Graph优化:在支持的硬件上进一步提升性能。
研究团队还提供了详细的环境配置和运行指南,确保其他研究者可以轻松复现和扩展这项工作。
未来展望
TriForce的出现无疑为大规模语言模型的应用开辟了新的可能性。随着这项技术的进一步发展和优化,我们可以期待:
- 更高效的长文本处理:从文学分析到法律文件审阅,TriForce可能彻底改变我们处理长文本的方式。
- 增强型对话系统:能够理解和保持超长上下文的对话AI将变得可能。
- 大规模知识整合:处理和综合海量信息的能力将大幅提升。
结语
TriForce代表了长序列生成技术的一个重要里程碑。它不仅解决了现有模型的效率瓶颈,还为未来更强大、更智能的AI系统铺平了道路。随着这项技术的不断完善和应用,我们有理由相信,人工智能在处理复杂、长序列任务方面的能力将迎来质的飞跃。
对于研究人员和开发者而言,TriForce提供了一个强大的工具,使得探索和实现前所未有的AI应用成为可能。我们期待看到更多基于TriForce的创新应用,进一步推动人工智能技术的边界。










