
UniRef++:跨模态统一的物体分割模型
在计算机视觉领域,物体分割是一项基础且重要的任务。随着深度学习的发展,针对不同场景的物体分割模型层出不穷,如指代图像分割(RIS)、少样本分割(FSS)、指代视频目标分割(RVOS)和视频目标分割(VOS)等。然而,这些模型往往针对特定任务进行设计,难以在不同任务间迁移和复用。为了解决这一问题,来自香港大学和阿里巴巴达摩院的研究团队提出了UniRef++,一个统一的跨模态物体分割框架。
UniRef++的核心亮点
UniRef++是在ICCV 2023论文UniRef的基础上进行扩展和改进的模型。它的核心亮点包括:
-
统一的多任务框架:UniRef++能够同时处理RIS、FSS、RVOS和VOS四种物体分割任务,实现了模型的通用性和灵活性。
-
创新的UniFusion模块:该模块是UniRef++的核心组件,能够高效融合不同模态的参考信息,如语言描述、图像模板等。UniFusion采用了flash attention技术,大幅提升了计算效率。
-
插件式设计:UniFusion模块可以作为插件组件,轻松集成到SAM等现有的基础视觉模型中,进一步增强其性能。
-
优异的性能表现:在多个基准数据集上,UniRef++都取得了state-of-the-art的结果,证明了其强大的分割能力。
UniRef++的模型架构
UniRef++的整体架构如下图所示:
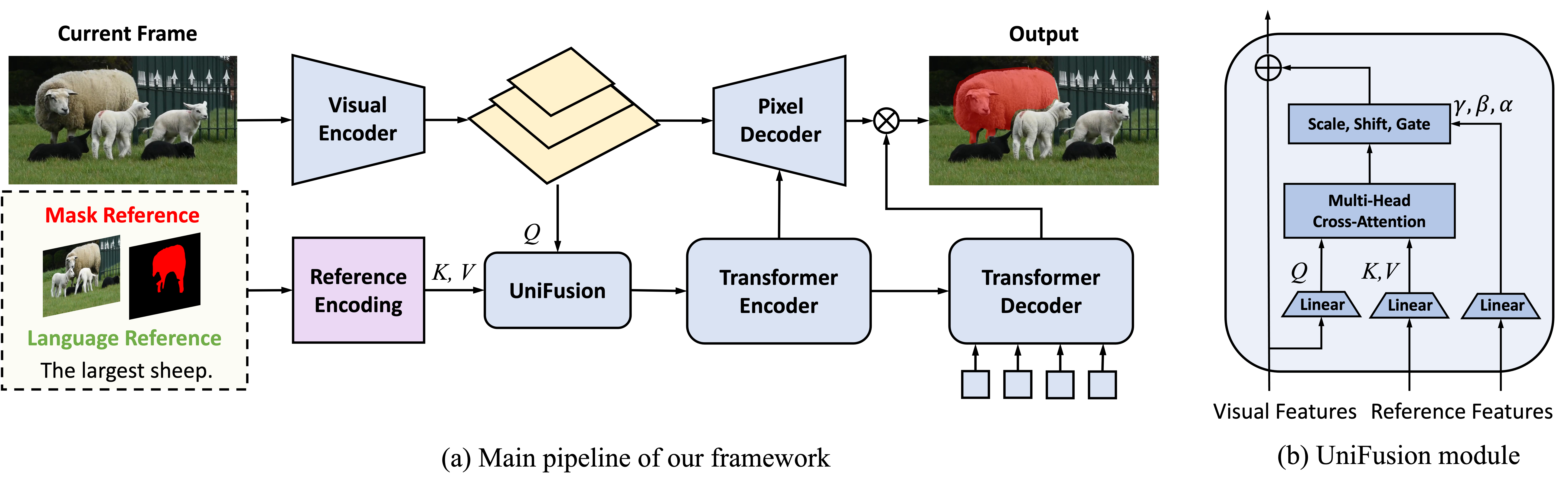
模型主要由以下几个部分组成:
-
主干网络:采用Swin Transformer作为特征提取器,提取多尺度的图像特征。
-
UniFusion模块:该模块负责融合不同模态的参考信息,如语言查询、图像模板等。它采用cross-attention机制,将参考信息与图像特征进行交互。
-
解码器:采用多尺度特征融合的解码器,生成最终的分割掩码。
-
辅助任务:引入了目标检测等辅助任务,进一步提升模型的性能。
UniRef++的应用效果
UniRef++在多个物体分割任务上都展现出了优异的性能。以下是一些典型的应用示例:
- 指代图像分割(RIS)
如图所示,UniRef++能够准确地根据自然语言描述定位并分割出目标物体。
- 指代视频目标分割(RVOS)
UniRef++可以根据语言查询,在视频序列中持续追踪并分割目标物体。
- 视频目标分割(VOS)
在传统的VOS任务中,UniRef++同样表现出色,能够稳定地追踪和分割多个目标物体。
- 零样本视频分割和少样本图像分割
UniRef++还展示了强大的泛化能力,能够进行零样本的视频分割和少样本的图像分割。
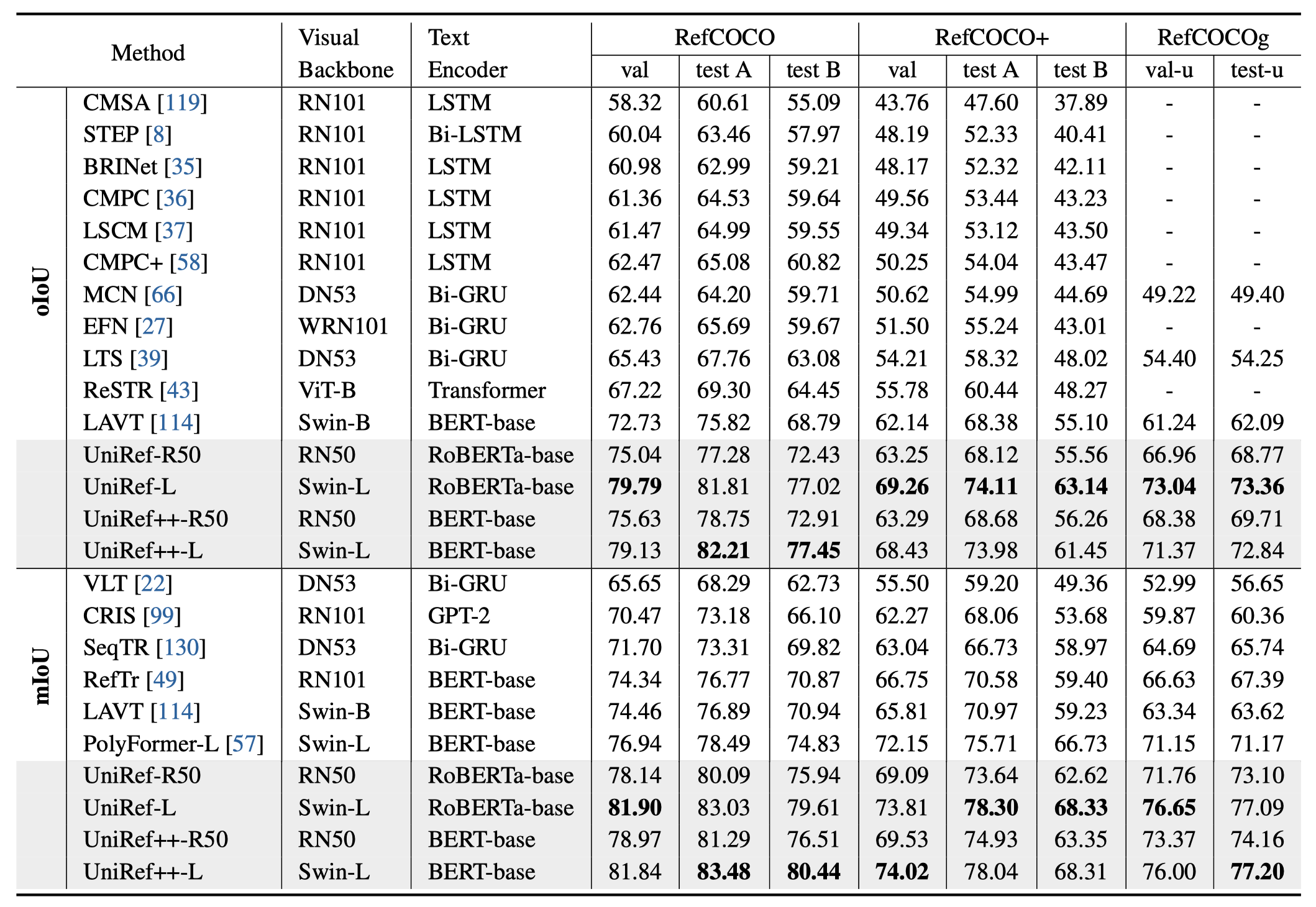
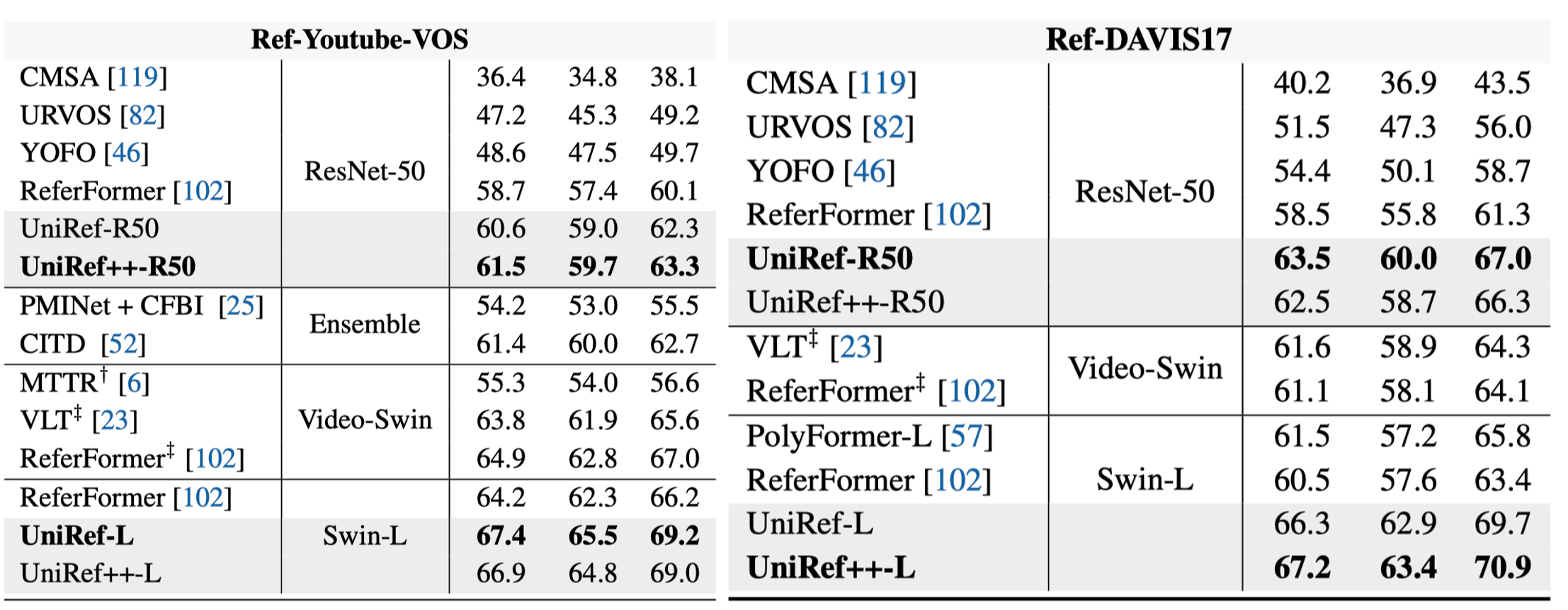
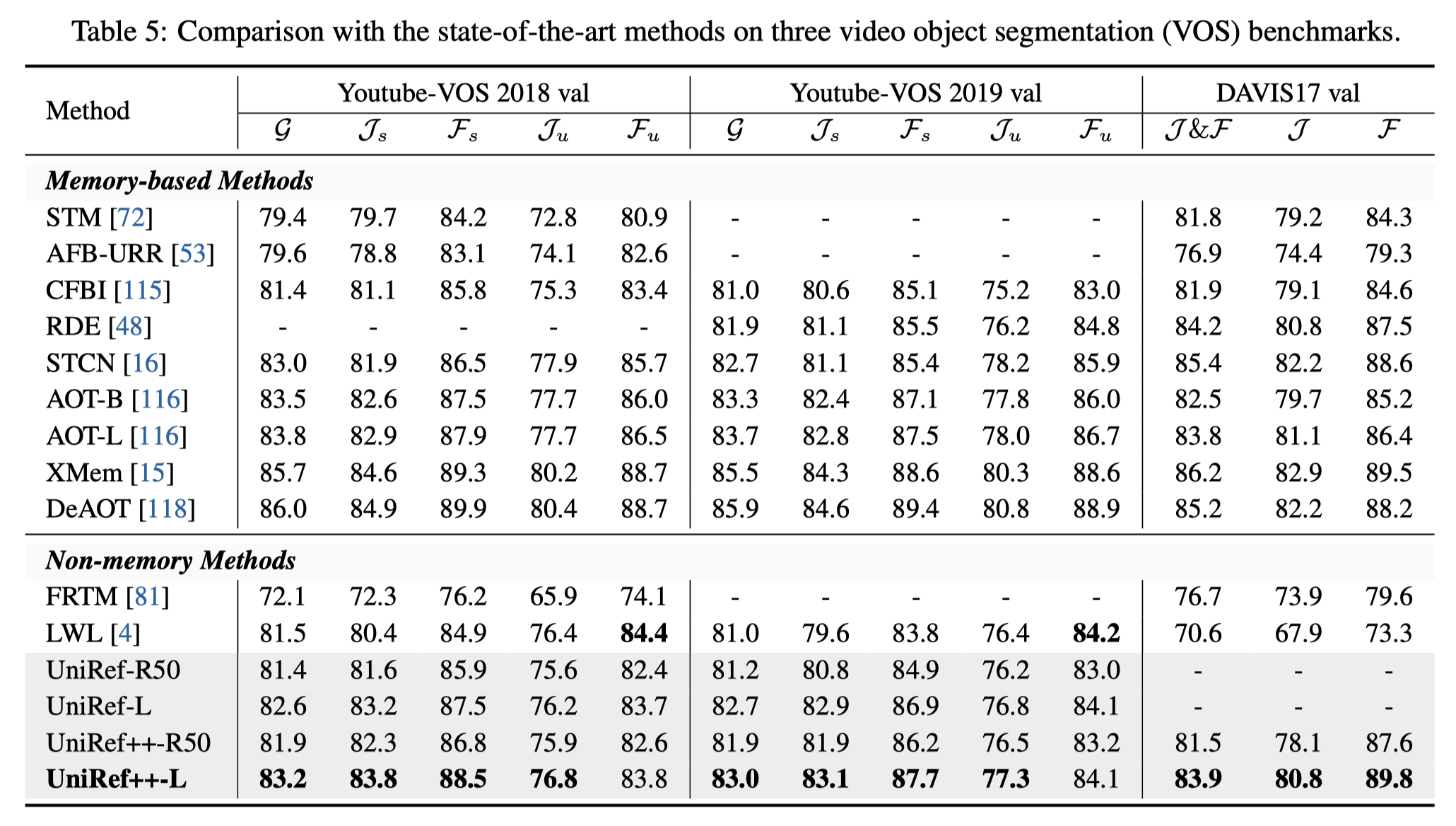
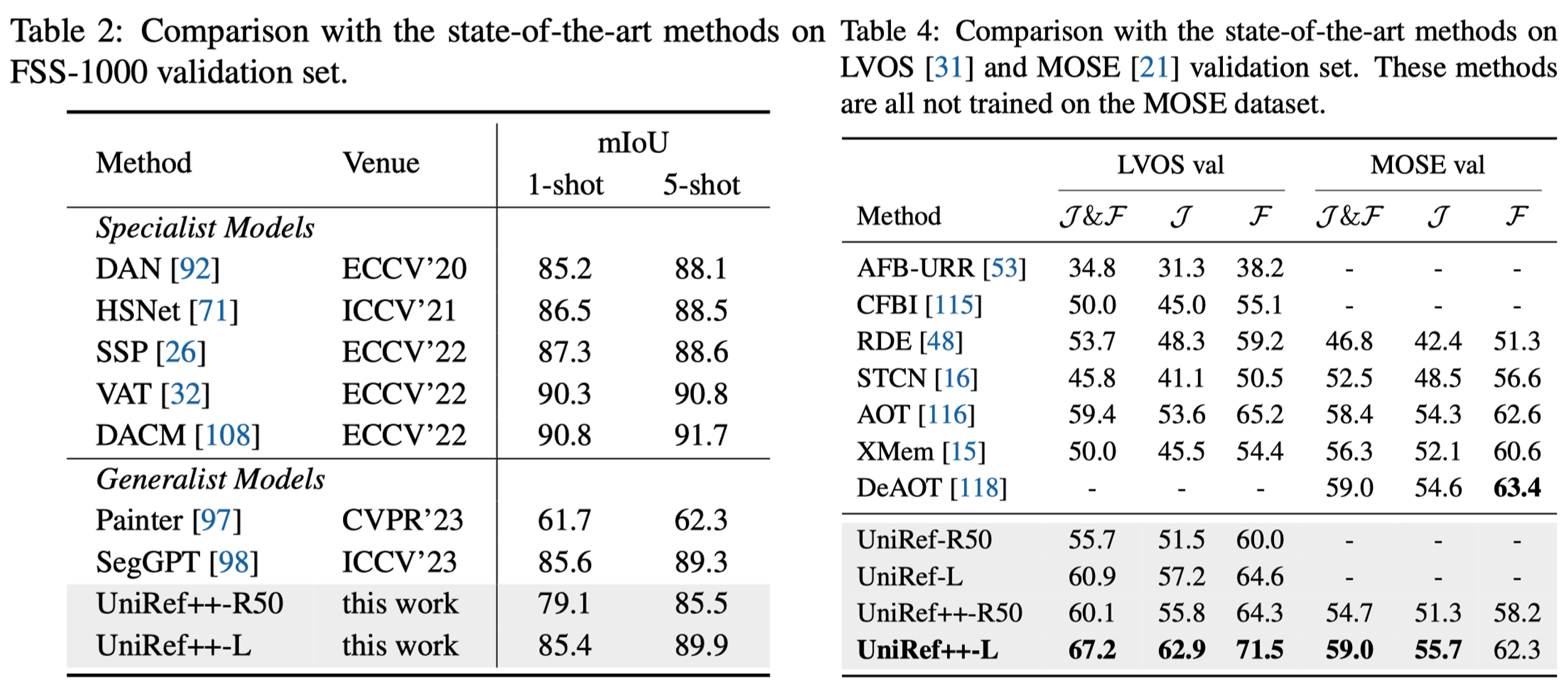
UniRef++的性能评估
研究团队在多个基准数据集上对UniRef++进行了全面的评估。以下是部分结果:
| 模型 | RefCOCO | FSS-1000 | Ref-Youtube-VOS | Ref-DAVIS17 | Youtube-VOS18 | DAVIS17 | LVOS |
|---|---|---|---|---|---|---|---|
| UniRef++-R50 | 75.6 | 79.1 | 61.5 | 63.5 | 81.9 | 81.5 | 60.1 |
| UniRef++-Swin-L | 79.1 | 85.4 | 66.9 | 67.2 | 83.2 | 83.9 | 67.2 |
可以看出,UniRef++在各项任务上都取得了优异的成绩,特别是采用Swin-L作为主干网络的版本,性能更加出色。
UniRef++的应用前景
UniRef++作为一个统一的跨模态物体分割框架,具有广阔的应用前景:
-
智能视觉助手:结合自然语言交互,UniRef++可以帮助视障人士理解周围环境,定位和识别特定物体。
-
自动驾驶:在自动驾驶场景中,UniRef++可以实现对道路、行人、车辆等目标的精确分割和追踪。
-
视频编辑:在视频后期制作中,UniRef++可以根据用户需求快速定位和分割特定目标,简化编辑流程。
-
增强现实:在AR应用中,UniRef++可以实现实时的场景理解和物体分割,提升交互体验。
-
医学影像分析:在医疗领域,UniRef++可以辅助医生进行器官、病变区域的精确分割,提高诊断效率。
结语
UniRef++的提出代表了物体分割领域的一个重要进展。它不仅统一了多个分割任务,还展示了优异的性能和灵活的应用能力。未来,随着模型的进一步优化和应用场景的拓展,UniRef++有望在更多领域发挥重要作用,推动计算机视觉技术的发展和应用。
研究团队已经开源了UniRef++的代码和预训练模型,欢迎学术界和工业界的研究者们下载使用,共同推动物体分割技术的进步。相信在不久的将来,我们会看到更多基于UniRef++的创新应用,为人工智能的发展贡献力量。









