
UniTR:统一多模态Transformer开启3D感知新纪元
在自动驾驶领域,准确而稳健的3D环境感知至关重要。如何有效融合来自多个传感器的信息,一直是这一领域的核心挑战。近日,由北京大学、华为诺亚方舟实验室等机构合作完成的研究成果UniTR,为这一问题提供了一种全新的解决方案。这项工作被ICCV 2023会议录用,并在GitHub上开源了代码实现。
突破性的统一多模态设计
UniTR的最大亮点,在于它首次实现了一个真正统一的多模态骨干网络。与以往方法不同,UniTR采用了一个模态无关的Transformer编码器,可以并行处理不同视角的传感器数据,并自动实现跨模态交互,无需额外的融合步骤。这种设计不仅简化了网络结构,还显著提升了计算效率。
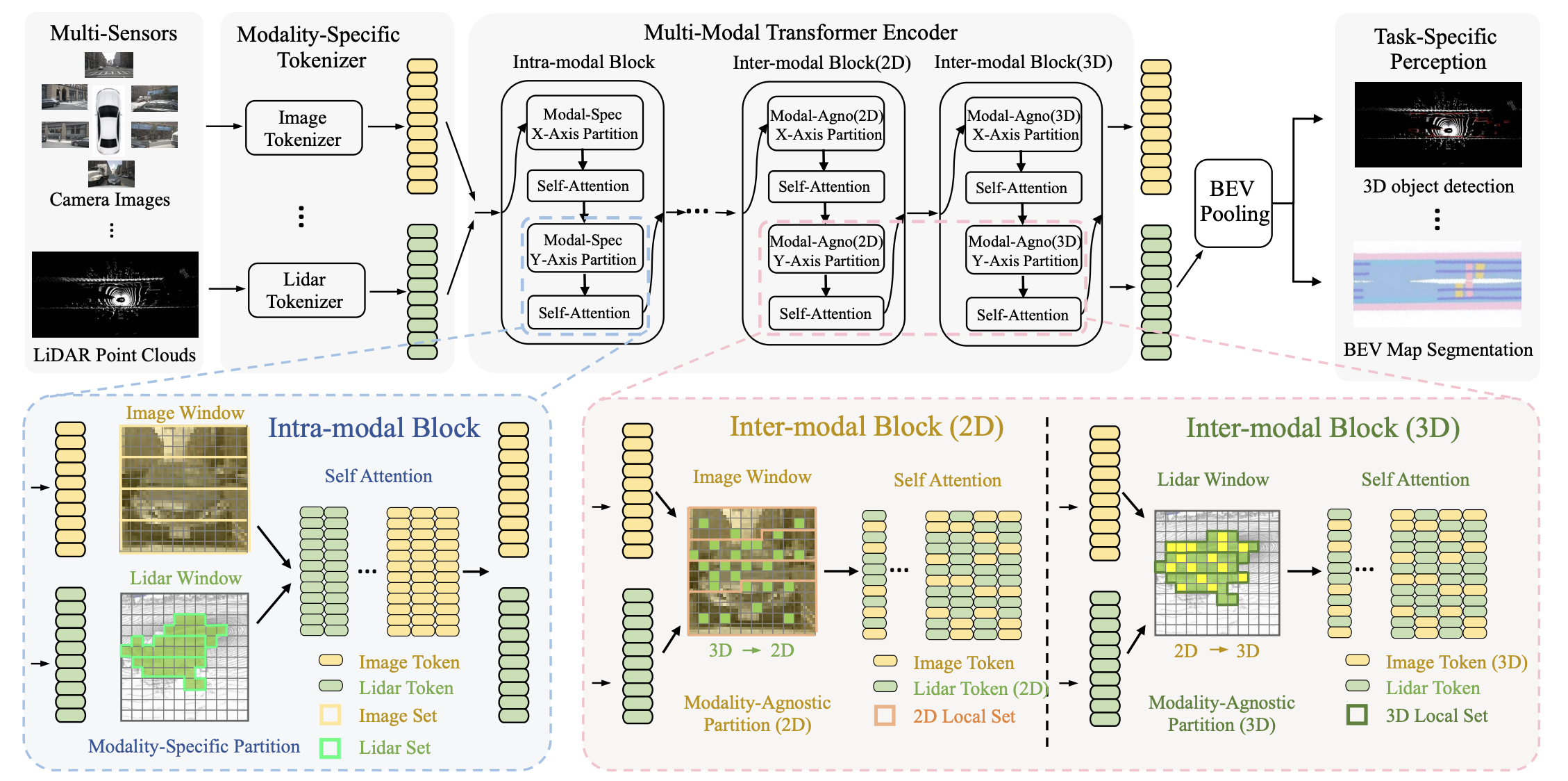
如上图所示,UniTR的核心是一个共享参数的多模态Transformer编码器。它可以同时处理来自相机和激光雷达的数据,在保持各自模态特征的同时,也能自然地实现跨模态信息交互。这种统一的设计为后续的3D检测头提供了丰富而连贯的特征表示。
卓越的性能表现
UniTR在nuScenes数据集上的表现令人印象深刻。在3D目标检测任务中,UniTR+LSS方法在测试集上达到了74.5的NDS分数,比之前的最好结果提高了1.1。在BEV地图分割任务上,UniTR+LSS在验证集上实现了74.7的mIoU,比基线方法提升了12个百分点。
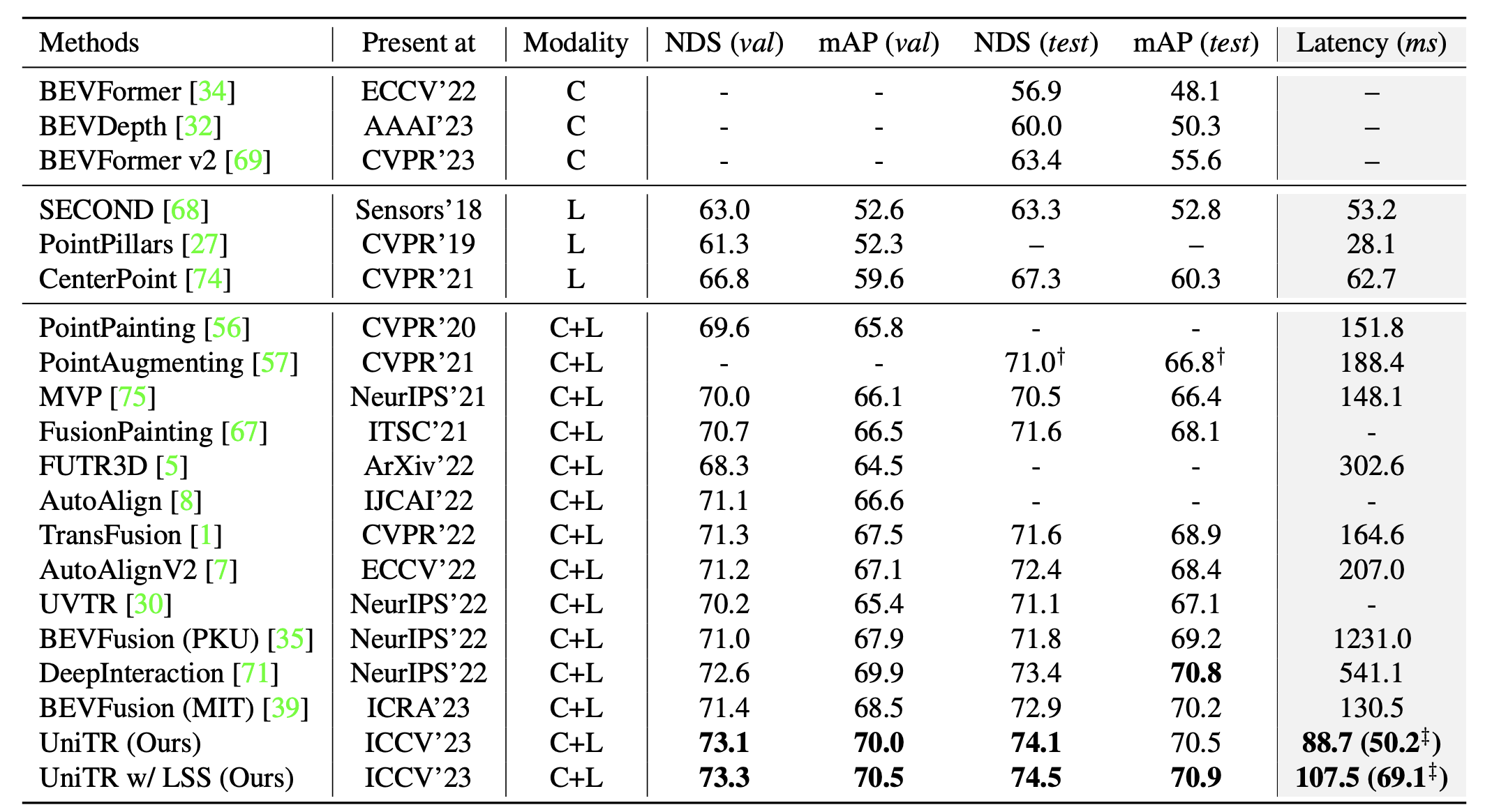
上图展示了UniTR与其他先进方法在3D目标检测任务上的性能对比。可以看到,UniTR在各项指标上都取得了显著优势,尤其是在整体性能指标NDS上的提升最为明显。
这些优异的结果充分证明了UniTR统一多模态处理策略的有效性。通过共享参数的设计,UniTR不仅提高了模型的表达能力,还显著降低了计算开销,为实际应用提供了更好的选择。
高效的推理性能
除了准确性,UniTR在推理效率方面也表现出色。研究人员提出了一种缓存模式,可以大幅提升推理速度。在nuScenes验证集上,使用缓存模式只会导致0.4的NDS性能下降,但可以减少40%的推理延迟。这对于自动驾驶等实时性要求高的场景来说非常有价值。
值得一提的是,UniTR的分区计算目前占用了大约40%的总时间,但研究人员指出,这部分还有很大的优化空间。通过改进分区策略或工程实现,有望将推理时间进一步缩短一半。而且这部分优化不会随模型规模增大而增加,这为未来扩展到更大规模模型提供了便利。
广泛的应用前景
UniTR不仅在性能上表现出色,其设计理念也为3D视觉领域的发展指明了方向。作为一个真正统一的多模态骨干网络,UniTR为构建3D视觉基础模型奠定了重要基础。研究人员指出,UniTR有望在以下几个方面产生深远影响:
- 3D视觉基础模型的基础设施:UniTR高效的网络设计为大规模模型的开发提供了可靠的结构基础。
- 基于图像-激光雷达对的多模态自监督学习:UniTR为利用不同模态数据之间的互补性进行无监督学习开辟了新途径。
- 单模态预训练:UniTR的结构与ViT非常相似,这为利用2D视觉领域的预训练模型提供了可能。
- 3D视觉的统一建模:UniTR为整合不同的3D视觉任务提供了统一的框架。
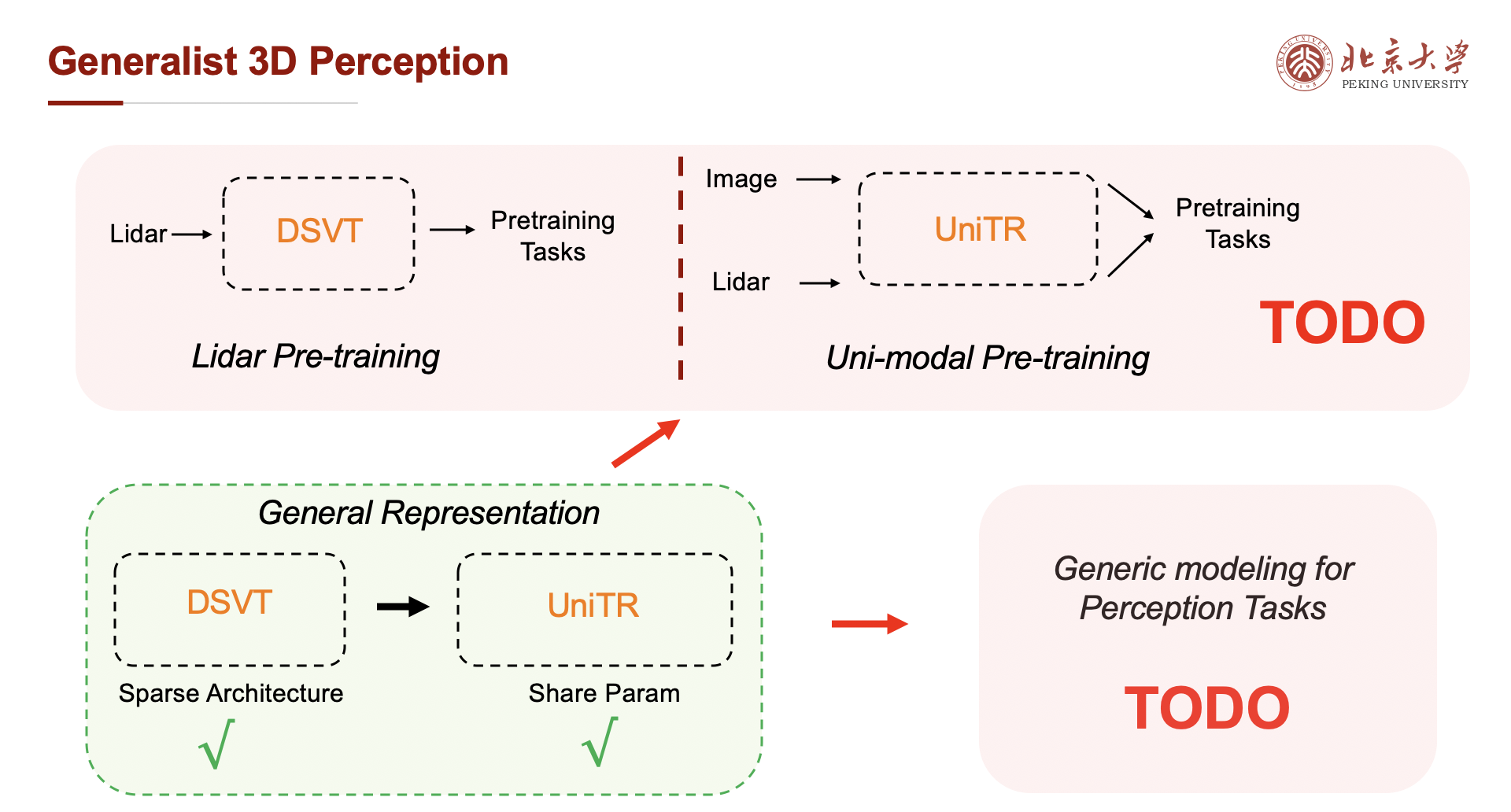
上图展示了UniTR如何为3D视觉的统一建模提供基础。从3D目标检测到BEV地图分割,再到3D重建等任务,都可以基于UniTR的统一表示进行建模。这种统一的范式有望大大促进3D视觉技术的发展和应用。
结语
UniTR的提出,不仅在技术上实现了突破,更为3D视觉领域的未来发展指明了方向。它展示了统一多模态处理的强大潜力,为构建更加智能、高效的3D感知系统开辟了新的可能性。随着自动驾驶、机器人等领域对3D感知能力的需求日益增长,UniTR这样的创新技术必将发挥越来越重要的作用。
未来,研究团队计划进一步优化UniTR的性能,探索更大规模模型的训练,以及将其应用到更广泛的3D视觉任务中。相信在学术界和工业界的共同努力下,基于UniTR的技术将不断evolve,为智能系统的发展注入新的活力。
如果您对UniTR感兴趣,欢迎访问上述链接了解更多技术细节,并关注该项目的最新进展。UniTR的开源不仅为学术研究提供了宝贵的资源,也为推动3D视觉技术的产业化应用铺平了道路。让我们共同期待UniTR在未来带来的更多突破和创新!









