
UniTS:开创时间序列分析新纪元
在当今数据驱动的世界中,时间序列分析已成为众多领域不可或缺的工具。然而,传统的时间序列模型往往局限于特定任务或领域,难以应对日益复杂和多样化的实际需求。为了解决这一挑战,来自哈佛大学医学院的研究团队开发了一个突破性的统一时间序列模型——UniTS。这个创新模型不仅能够处理跨多个领域的各种任务,还具有共享参数和无任务特定模块的独特优势。
UniTS的核心理念与创新设计
UniTS的核心理念源于基础模型,特别是大型语言模型(LLMs)在深度学习领域带来的变革。研究团队意识到,与其为每个特定任务训练单独的模型,不如构建一个通用的预训练模型,通过少量样本提示或微调来适应多种任务。然而,将这一理念应用于时间序列数据并非易事,因为时间序列数据具有独特的挑战,如数据集的多样性、跨领域特性,以及不同任务(如预测、分类等)之间的规范差异。
为了应对这些挑战,UniTS采用了一种新颖的统一网络骨架设计。这一设计巧妙地融合了序列注意力和变量注意力机制,并结合了动态线性算子。通过这种方式,UniTS能够作为一个统一模型进行训练,支持包括分类、预测、插补和异常检测在内的多种任务。
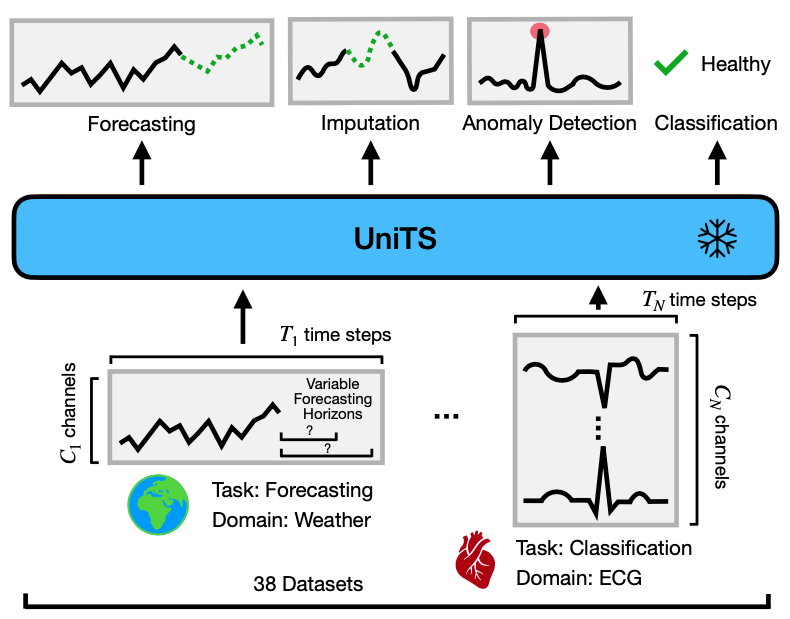
UniTS的卓越性能与广泛应用
UniTS的强大之处不仅体现在其设计理念上,更体现在其实际表现中。在涵盖38个多领域数据集的广泛测试中,UniTS展现出了优于专门任务模型和重新调整用途的自然语言LLMs的卓越性能。特别值得一提的是,UniTS在面对新的数据领域和任务时,表现出了令人瞩目的零样本、少样本和提示学习能力。
这种多功能性和适应性使UniTS成为时间序列分析领域的一个重要突破。它不仅能够处理传统的预测和分类任务,还能胜任更复杂的插补和异常检测任务。这意味着UniTS可以在金融、医疗、工业和环境监测等多个领域发挥重要作用,为决策者和研究人员提供更全面、更准确的数据洞察。
UniTS的实际应用与使用指南
对于希望在自己的项目中使用UniTS的研究人员和开发者,该团队提供了详细的使用指南和教程。通过GitHub仓库(https://github.com/mims-harvard/UniTS),用户可以轻松获取模型代码、预训练权重和使用说明。
使用UniTS的基本步骤包括:
- 安装必要的依赖项,包括PyTorch 2.0+。
- 准备数据,可以使用提供的脚本下载示例数据集。
- 根据具体任务选择合适的训练和评估脚本。
UniTS支持多种学习范式,包括:
- 多任务学习:适用于预测和分类任务
- 少样本迁移学习:用于新的预测、分类、异常检测和插补任务
- 零样本学习:适用于新的预测长度和数据集
这种灵活性使得UniTS能够适应各种实际应用场景,无论是需要处理大量已知数据的项目,还是面对全新领域的探索性研究。
UniTS的未来发展与潜在影响
UniTS的出现标志着时间序列分析领域迈向更加统一和通用的方向。这种统一模型的理念不仅简化了模型选择和训练过程,还为跨领域知识迁移开辟了新的可能性。随着UniTS的进一步发展和完善,我们可以预见它在以下几个方面带来深远影响:
- 研究效率提升:研究人员可以使用单一模型处理多种时间序列任务,大大提高研究效率。
- 跨领域应用:UniTS的通用性使得在不同领域之间迁移知识变得更加容易,促进跨学科研究。
- 资源优化:通过共享参数和消除任务特定模块,UniTS有助于减少计算资源的消耗。
- 智能系统升级:在物联网和智能城市等应用中,UniTS可以为复杂的时间序列数据分析提供更全面的解决方案。
结语
UniTS的诞生无疑是时间序列分析领域的一个重要里程碑。它不仅代表了技术的进步,更体现了科研思维的创新。通过打破传统模型的局限性,UniTS为我们展示了一个更加统一、高效的时间序列分析未来。
随着更多研究者和开发者开始采用和改进UniTS,我们有理由相信,这一创新模型将继续推动时间序列分析技术的边界,为各行各业带来前所未有的数据洞察力。无论是在科学研究、商业决策还是社会治理方面,UniTS都有潜力成为关键的技术支撑,帮助我们更好地理解和预测复杂的时间序列现象。
对于那些对时间序列分析感兴趣的研究者和实践者来说,现在正是深入了解和尝试UniTS的最佳时机。通过访问UniTS的GitHub仓库,您可以获取更多技术细节、使用指南和最新更新。让我们共同期待UniTS在未来带来更多令人兴奋的应用和突破!









