
Vearch: 为AI应用打造的云原生向量数据库
在人工智能和机器学习快速发展的今天,高效处理和检索大规模向量数据的需求日益迫切。Vearch应运而生,它是一个专为AI应用设计的开源分布式向量数据库系统,能够高效地存储和检索深度学习生成的embedding向量。
核心特性
Vearch具有以下几个突出的特点:
-
混合搜索: Vearch支持向量搜索和标量过滤的混合查询,能够同时处理结构化和非结构化数据。
-
高性能: 采用先进的索引技术,Vearch可以在毫秒级别内从数百万级的向量集合中检索出最相似的结果。
-
可扩展性: Vearch采用分布式架构设计,支持数据分片和副本机制,可以轻松扩展到大规模集群。
-
可靠性: 通过数据多副本和容错机制,Vearch保证了系统的高可用性。
-
灵活性: 支持多种向量索引方法(如IVFPQ、HNSW等)和距离计算方式(如内积、欧氏距离等)。
系统架构
Vearch采用了经典的主从架构,主要包含三个核心组件:
-
Master: 负责元数据管理、集群调度等工作。
-
Router: 提供RESTful API接口,负责请求路由和结果聚合。
-
PartitionServer (PS): 负责数据存储和检索,是Vearch的核心引擎。
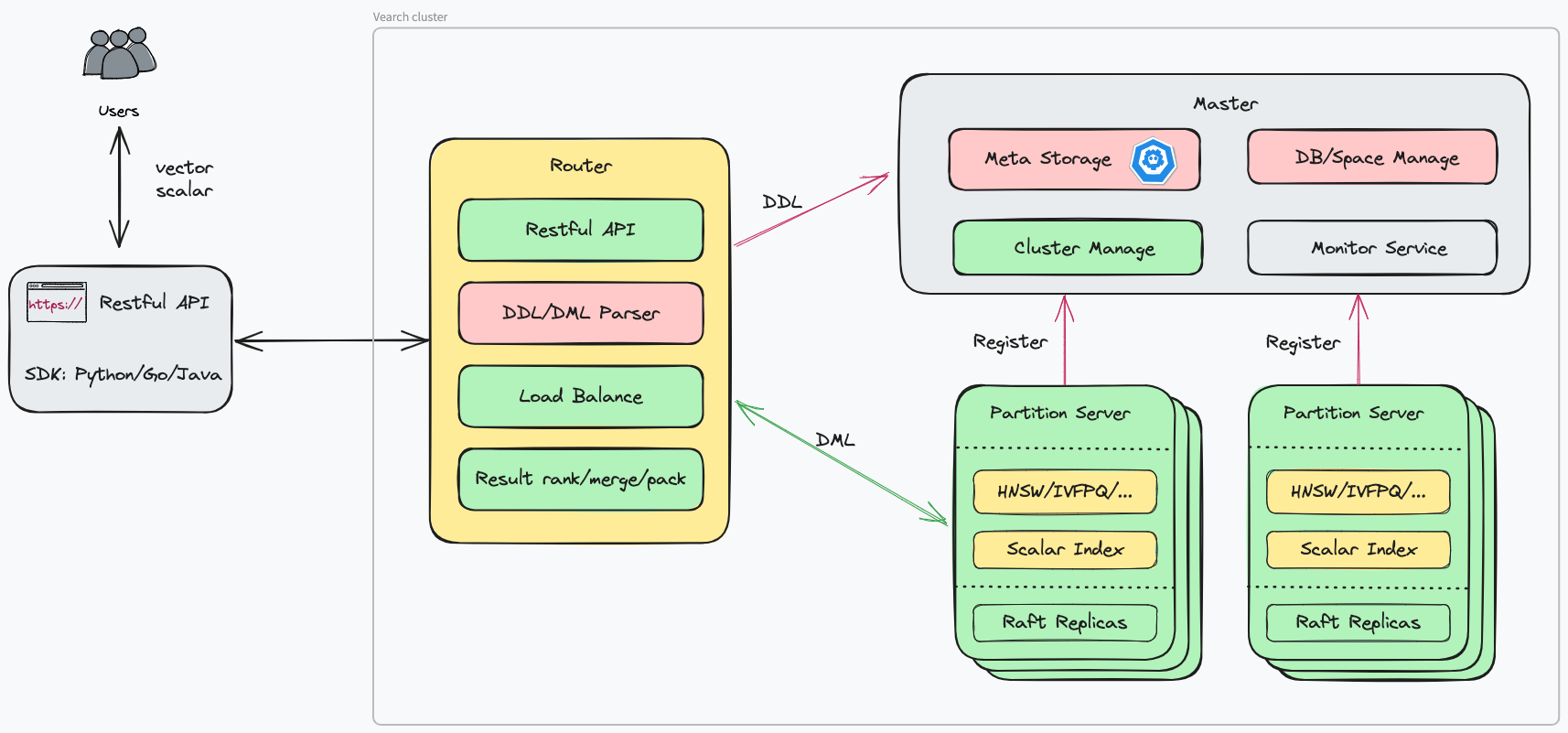
PS节点采用了基于Raft协议的多副本机制,保证了数据的一致性和可用性。其核心检索引擎Gamma基于Facebook开源的Faiss库实现,提供了高效的向量检索能力。
应用场景
Vearch在多个AI领域都有广泛的应用前景:
-
图像检索: 可以构建大规模的图像检索系统,支持以图搜图等应用。
-
推荐系统: 存储用户和物品的embedding向量,支持基于相似度的个性化推荐。
-
智能问答: 作为检索增强生成(RAG)系统的向量存储后端,提升大语言模型的知识检索能力。
-
相似文本检索: 支持海量文本的语义相似度搜索。
快速上手
Vearch提供了多种部署方式,包括Docker、Kubernetes等。以Docker Compose为例,只需几个简单的步骤就可以启动一个Vearch集群:
$ cd cloud
$ cp ../config/config.toml .
$ docker-compose --profile standalone up -d
Vearch还提供了Python、Go等多种语言的SDK,方便开发者快速集成到自己的应用中。
开源社区
作为一个活跃的开源项目,Vearch拥有广泛的社区支持。开发者可以通过GitHub Issues、邮件列表或Slack频道参与讨论,贡献代码。目前已有包括京东、快手、58同城等在内的多家知名企业在生产环境中使用Vearch。
总结
Vearch作为一款专为AI应用优化的向量数据库,在性能、可扩展性和易用性等方面都表现出色。随着AI技术的不断发展,Vearch有望在更多领域发挥重要作用,成为构建智能应用的关键基础设施之一。
无论是构建搜索引擎、推荐系统,还是智能问答机器人,Vearch都能为您的AI应用提供强大的向量检索支持。欢迎访问Vearch官网了解更多信息,加入这个充满活力的开源社区!









