
Video-MME:开创性的视频分析评估基准
在人工智能快速发展的今天,多模态大语言模型(MLLMs)正成为研究的焦点。然而,这些模型在处理连续视觉数据方面的潜力尚未被充分探索。为了填补这一空白,研究人员推出了Video-MME,这是首个全面评估MLLMs在视频分析能力的基准测试。
什么是Video-MME?
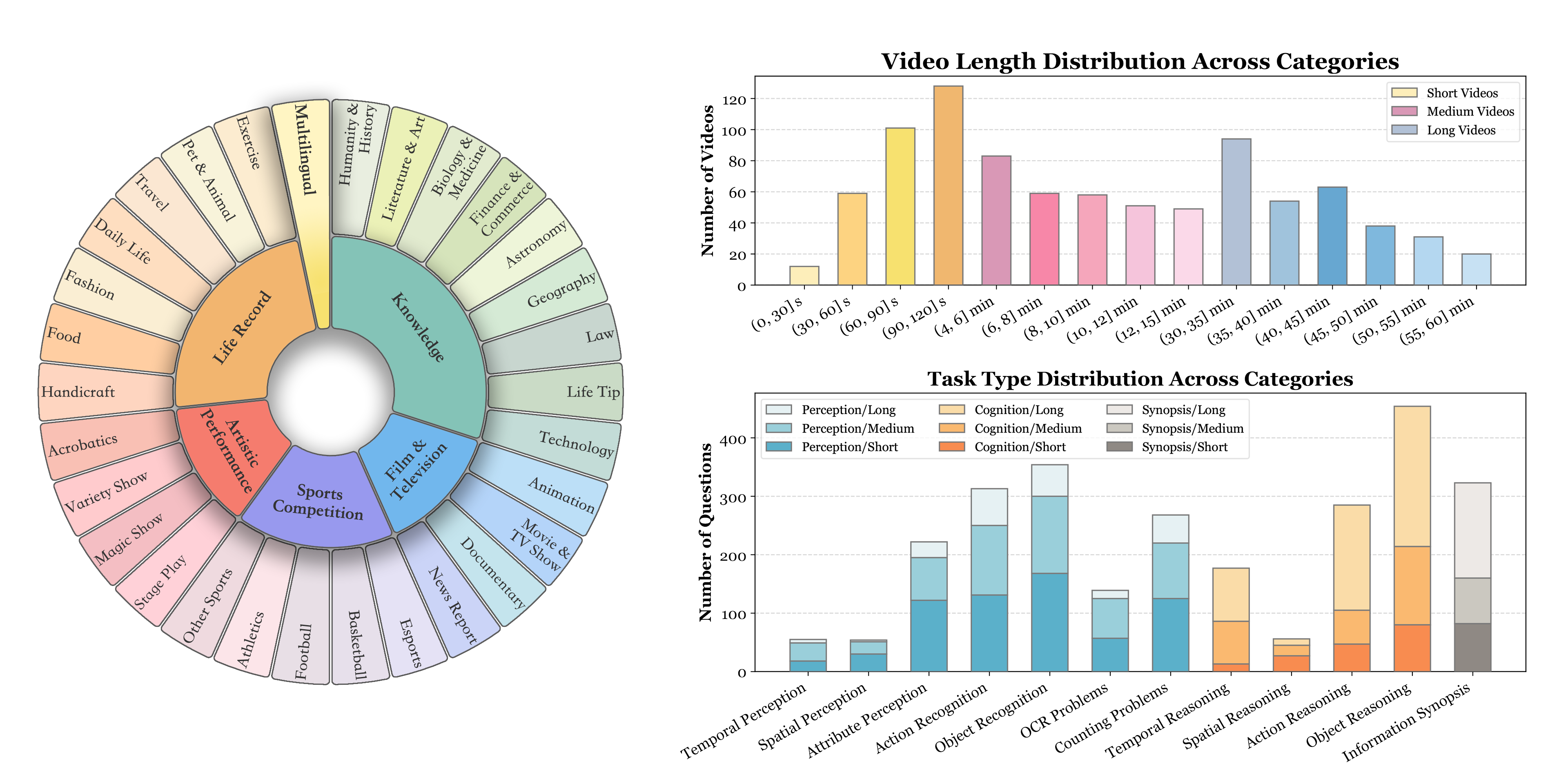
Video-MME代表视频多模态评估(Video Multi-Modal Evaluation)。它是专门为评估MLLMs在视频分析中的表现而设计的综合基准。这个基准包含900个视频,总时长达254小时,并配有2,700个人工标注的问答对。
Video-MME的核心特点
-
时间维度的多样性:Video-MME涵盖了短期(2分钟以下)、中期(4-15分钟)和长期(30-60分钟)视频,时长范围从11秒到1小时不等,以测试模型对不同时长视频的处理能力。
-
视频类型的广泛性:基准涉及6个主要视觉领域,包括知识、影视、体育竞技、生活记录和多语言等,共30个子领域,确保了测试场景的广泛性。
-
数据模态的丰富性:除了视频帧,Video-MME还整合了字幕和音频等多模态输入,全面评估MLLMs的处理能力。
-
注释质量的保证:所有数据都是新收集并由人工标注的,而非来自任何现有的视频数据集,保证了多样性和质量。
Video-MME的评估流程
Video-MME的评估流程包括以下几个关键步骤:
-
提取帧和字幕:基准包含900个视频和744个字幕文件,所有长视频都配有字幕。
-
设置提示:评估中使用的通用提示遵循特定格式,包括字幕内容(如果有)和多项选择题。
-
评估:模型响应被添加到JSON文件中,然后使用评估脚本计算准确性得分。

实验结果
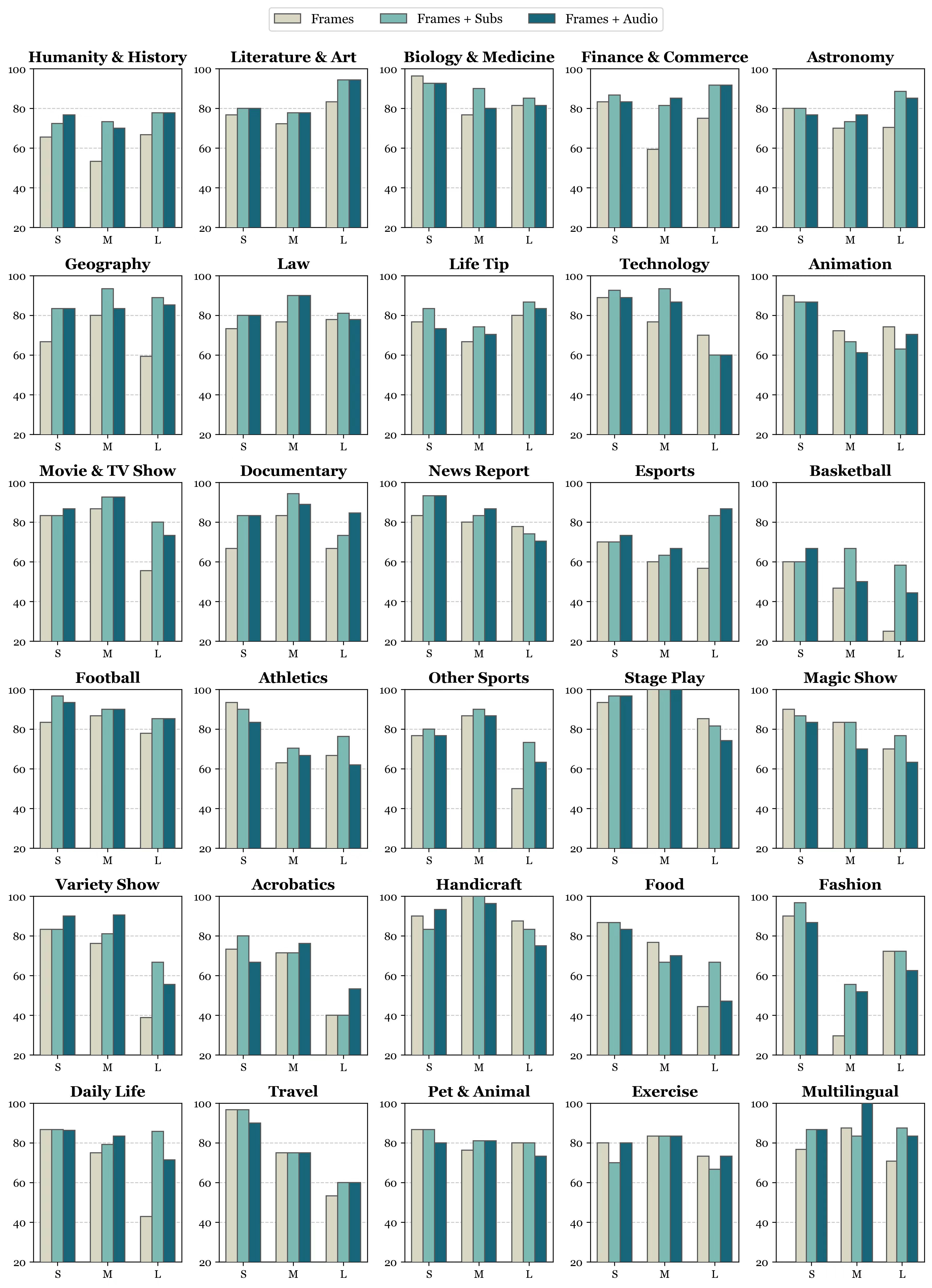
初步实验结果显示,不同的MLLMs在Video-MME基准上表现各异。例如,Gemini 1.5 Pro在不同视频持续时间类型和不同视频子类型上的表现各有特点。
Video-MME的意义
-
全面评估:Video-MME提供了首个全面评估MLLMs在视频分析能力的基准,填补了现有评估工具的空白。
-
推动技术进步:通过提供详细的评估指标,Video-MME有助于研究人员和开发者改进MLLMs在视频处理方面的能力。
-
跨领域应用:基准涵盖的广泛视频类型和任务,为MLLMs在不同领域的应用提供了重要参考。
-
标准化评估:Video-MME为视频分析领域提供了一个标准化的评估工具,有利于不同模型之间的公平比较。
未来展望
随着Video-MME的推出,我们可以期待看到:
- MLLMs在视频分析能力上的快速提升。
- 更多针对视频处理的专门化模型的出现。
- 视频分析技术在各行各业的广泛应用,如教育、医疗、安防等领域。
Video-MME的出现无疑为多模态大语言模型在视频分析领域的研究和应用开辟了新的道路。它不仅为研究人员提供了宝贵的评估工具,也为人工智能在处理复杂视觉信息方面的进步铺平了道路。随着技术的不断发展,我们可以期待看到更多基于Video-MME的创新成果,推动视频分析技术向更高水平迈进。
要了解更多关于Video-MME的信息,可以访问项目主页或查阅arXiv论文。研究人员和开发者也可以通过GitHub仓库参与到这个开创性项目中来,共同推动多模态大语言模型在视频分析领域的发展。









