
VideoMamba: 视频理解的革命性突破
在人工智能和计算机视觉领域,视频理解一直是一个充满挑战的研究方向。传统的视频处理模型往往难以同时兼顾局部细节和长期依赖关系,这严重制约了视频理解技术的进步。然而,随着VideoMamba的出现,这一困境似乎找到了突破口。
VideoMamba的创新之处
VideoMamba是由来自多个知名研究机构的学者联合开发的一种新型视频理解模型。它的核心创新在于巧妙地将Mamba架构引入视频领域,从而实现了对视频数据的高效处理。
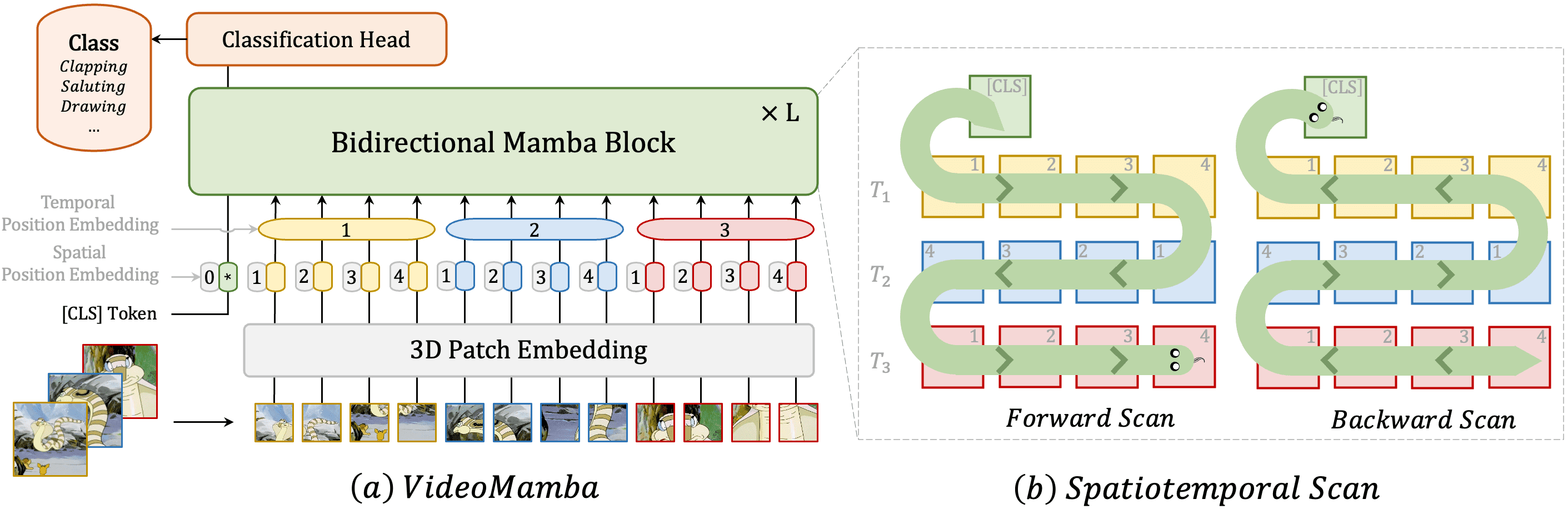
如上图所示,VideoMamba的架构设计充分考虑了视频数据的特性。它采用了3D patch embedding层来将输入视频分割成非重叠的时空块,然后通过创新的VideoMamba block进行处理。这种设计不仅能够捕捉局部的时空特征,还能有效建模长期依赖关系。
VideoMamba的四大核心能力
-
可扩展性:得益于一种新颖的自蒸馏技术,VideoMamba无需大规模数据集预训练就能在视觉领域展现出色的可扩展性。这一特性大大提高了模型的实用性和适应性。
-
短期动作识别敏感性:即使面对细微的动作差异,VideoMamba也能准确识别短期动作。这使得它在诸如手势识别、动作分类等任务中表现出色。
-
长期视频理解优势:相比传统的基于特征的模型,VideoMamba在长视频理解任务上展现出显著的进步。这一能力对于视频摘要、长视频内容分析等应用极为重要。
-
多模态兼容性:VideoMamba不仅在单模态视频任务中表现出色,还展示了与其他模态(如文本)结合的强大能力,为多模态视频理解开辟了新的可能性。
VideoMamba的技术细节
VideoMamba的核心在于其创新的状态空间模型(State Space Model, SSM)设计。这种设计使得模型能够以线性复杂度处理长序列输入,这对于高分辨率长视频的理解至关重要。具体来说:
-
线性复杂度算子:VideoMamba采用了特殊设计的线性复杂度算子,使得模型能够高效处理长序列数据,而不会像传统Transformer那样随序列长度增加而出现二次方复杂度增长的问题。
-
双向Mamba块:VideoMamba扩展了原有的Mamba块,使其能够处理3D视频数据。这种双向设计让模型能够同时考虑前向和后向的时空信息,从而更全面地理解视频内容。
-
自蒸馏技术:为了提高模型的可扩展性,研究人员引入了一种新颖的自蒸馏技术。这使得VideoMamba能够在较小的数据集上训练,同时保持良好的泛化能力。
VideoMamba的多任务应用
VideoMamba的versatility在多种视频理解任务中得到了充分验证:
-
短期视频理解:在动作识别、手势识别等短视频任务中,VideoMamba展现出了超越传统3D CNN和视频Transformer的性能。
-
长期视频理解:对于长视频分析、视频摘要等任务,VideoMamba的线性复杂度特性使其能够高效处理长时间序列,表现优于基于特征的传统方法。
-
视频-文本检索:在多模态任务中,VideoMamba展示了与文本模态结合的强大能力,为视频-文本检索任务带来了新的解决方案。
-
掩码建模预训练:VideoMamba还支持掩码建模预训练策略,这进一步增强了模型的泛化能力和迁移学习潜力。
VideoMamba的开源贡献
值得一提的是,VideoMamba项目已在GitHub上开源(https://github.com/OpenGVLab/VideoMamba),这为整个计算机视觉社区带来了宝贵的资源。研究者和开发者可以访问完整的代码库、预训练模型以及详细的文档,这大大促进了技术的传播和进一步创新。
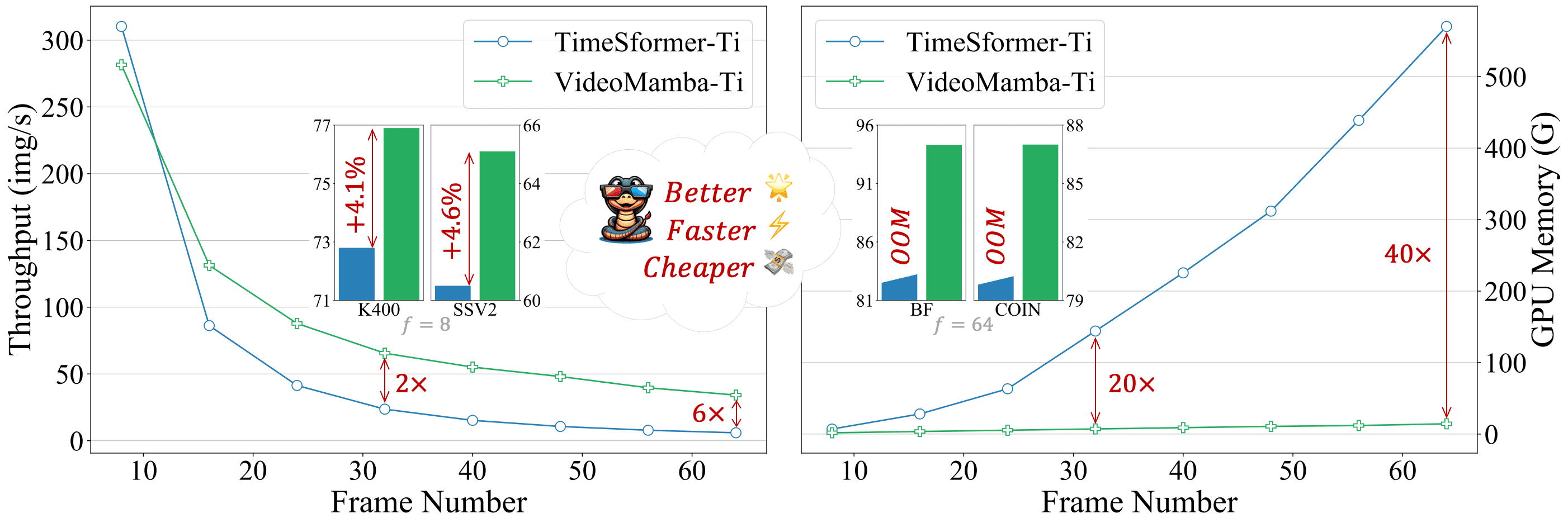
如上图所示,VideoMamba在多个benchmark上都展现出了优异的性能,特别是在效率和准确性的平衡上,VideoMamba显示出了明显的优势。
VideoMamba的未来展望
尽管VideoMamba已经展现出了令人瞩目的性能,但研究团队并未就此止步。他们指出,当前的实现还存在一些可以改进的地方,例如:
-
层衰减优化:研究人员发现,由于实现中的一个bug,当前的视频模型是在没有层衰减的情况下微调的。修复这个问题可能会进一步提升模型性能。
-
规模化探索:目前的实验主要集中在中小规模模型上,未来可能会探索更大规模的VideoMamba模型,以充分发挥其潜力。
-
多模态融合:虽然VideoMamba已经在视频-文本任务上展现出色表现,但在更复杂的多模态场景中还有很大的探索空间。
-
实时处理能力:进一步优化VideoMamba的推理速度,使其能够应用于实时视频处理场景,如视频监控、自动驾驶等。
结语
VideoMamba的出现无疑为视频理解领域带来了一股新的革新力量。它不仅在性能上超越了现有的许多方法,更重要的是提供了一种新的思路——如何将高效的序列处理技术应用于复杂的视频数据。随着研究的深入和应用的拓展,我们有理由相信,VideoMamba将在计算机视觉的未来发展中扮演越来越重要的角色,推动视频理解技术向更高效、更智能的方向迈进。
对于研究者和开发者来说,深入了解和应用VideoMamba不仅可以提升当前的视频处理能力,还可能激发出更多创新性的应用场景。随着开源社区的不断贡献和完善,我们期待看到基于VideoMamba的更多令人惊叹的应用出现,共同推动视频智能处理技术的进步。









