
引言
近年来,视觉语言模型(Vision-Language Models, VLMs)在计算机视觉领域引起了广泛关注。VLMs通过学习图像和文本之间的关联,可以实现零样本预测,在多种视觉任务上取得了令人瞩目的成果。本文将对VLMs在视觉任务中的应用进行全面综述,包括VLM的预训练方法、迁移学习方法和知识蒸馏方法,并对未来研究方向进行展望。
VLM预训练方法
VLM的预训练通常采用大规模的图文对数据集,主要包括以下三类方法:
对比学习预训练
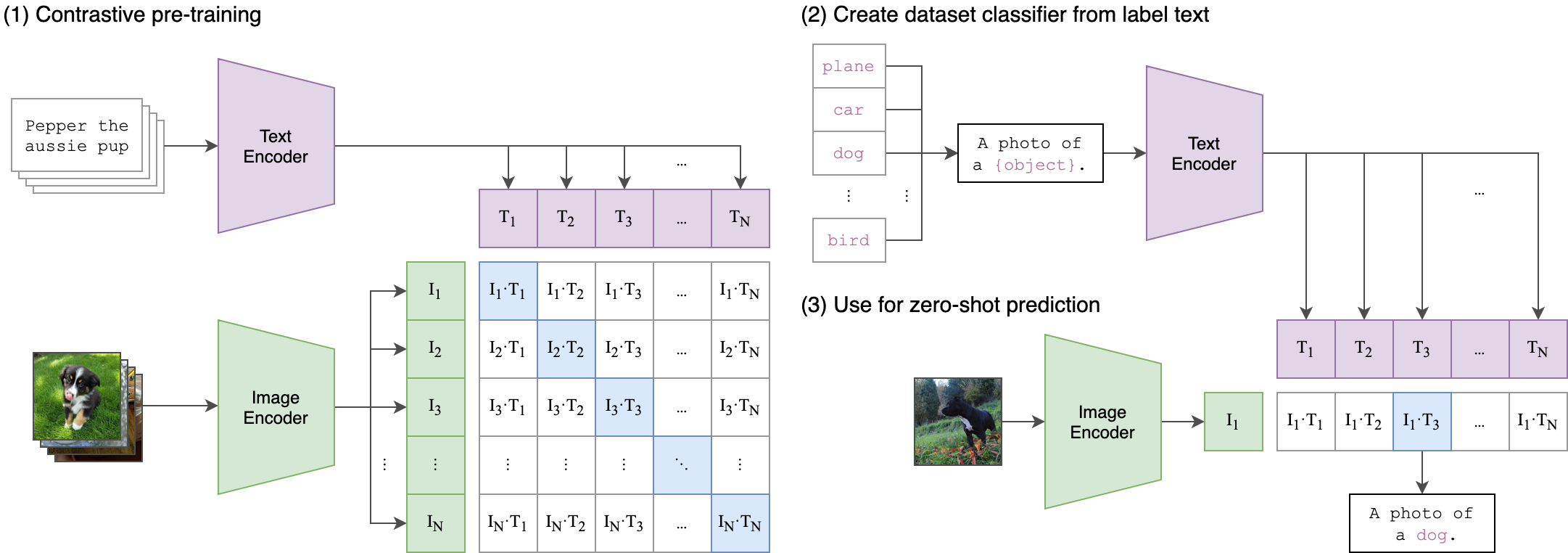
对比学习是VLM预训练的主流方法之一。其核心思想是最大化匹配的图文对的相似度,同时最小化不匹配图文对的相似度。代表性工作包括:
-
CLIP (Contrastive Language-Image Pre-training): 使用4亿个图文对进行预训练,在多个下游任务上实现了零样本迁移。
-
ALIGN: 使用18亿个图文对进行预训练,进一步扩大了数据规模。
-
FILIP: 引入细粒度的图像-文本交互,提高了模型性能。
-
PyramidCLIP: 利用多尺度特征对齐提升模型表达能力。
生成式预训练
生成式预训练通过重建图像或文本来学习多模态表示。代表性工作包括:
-
FLAVA: 同时进行图像重建、文本重建和图文匹配预训练。
-
CoCa: 结合对比学习和生成式预训练,实现了更好的性能。
-
SAM (Segment Anything Model): 通过图像分割任务进行预训练,可以实现零样本分割。
对齐式预训练
对齐式预训练旨在学习图像区域与文本之间的细粒度对应关系。代表性工作包括:
-
GLIP: 通过目标检测任务学习图像区域与文本的对齐。
-
DetCLIP: 引入词典增强的视觉概念并行预训练。
VLM迁移学习方法
为了将预训练的VLM应用到下游任务,研究人员提出了多种迁移学习方法:
提示调优
提示调优通过学习任务相关的提示来适应下游任务,主要包括:
- 文本提示调优:
- CoOp: 学习连续的文本提示嵌入。
- CoCoOp: 引入实例级的文本提示。
- CLIP-Adapter: 使用轻量级adapter进行提示调优。
- 视觉提示调优:
- VPT: 在图像编码器中插入可学习的提示tokens。
- VL-Prompt: 同时学习视觉和语言提示。
- 文本-视觉联合提示调优:
- UPT: 统一的提示调优框架,同时学习文本和视觉提示。

特征适配
特征适配通过在原有模型基础上添加少量可训练参数来实现迁移学习:
- CLIP-Adapter: 使用轻量级的adapter模块进行特征适配。
- Tip-Adapter: 基于近邻学习的快速适配方法。
- VL-Adapter: 结合视觉和语言适配器的多模态适配方法。
其他方法
- CLIP-ViL: 将CLIP特征与任务特定模型结合。
- CLIP-Adapter++: 引入对抗训练和知识蒸馏的适配方法。
- VLMo: 多任务训练的统一视觉语言模型。
VLM知识蒸馏方法
为了将VLM的知识迁移到下游任务专用模型中,研究人员提出了多种知识蒸馏方法:
目标检测知识蒸馏
- ViLD: 使用CLIP蒸馏目标检测模型。
- YOLO-World: 基于CLIP的开放词汇目标检测模型。
- RegionCLIP: 区域级的CLIP知识蒸馏。
语义分割知识蒸馏
- CLIPSeg: 使用CLIP特征进行零样本语义分割。
- ZegCLIP: 基于CLIP的零样本语义分割方法。
- MaskCLIP: 结合掩码预测的CLIP知识蒸馏。
其他任务知识蒸馏
- ActionCLIP: 基于CLIP的动作识别方法。
- CLIP-Event: 使用CLIP进行事件检测。
- CLIPScore: 基于CLIP的图像-文本相关性评估指标。
未来研究方向
尽管VLM在视觉任务中取得了显著进展,但仍存在一些挑战和潜在的研究方向:
-
大规模多模态预训练:如何更有效地利用大规模图文数据进行预训练,是未来研究的重要方向。
-
模型压缩与加速:如何在保持性能的同时,减小模型规模、提高推理速度,是VLM实际应用的关键问题。
-
跨语言跨模态迁移:如何实现VLM在不同语言和模态之间的高效迁移,值得进一步探索。
-
细粒度视觉-语言对齐:如何学习更精确的视觉区域与文本的对应关系,是提升VLM性能的重要途径。
-
可解释性与鲁棒性:如何提高VLM的可解释性和对抗攻击的鲁棒性,是保证模型可靠性的关键。
-
多模态融合:如何更好地融合视觉、语言等多种模态的信息,是未来多模态智能的重要研究方向。
结论
本文全面综述了视觉语言模型(VLM)在视觉任务中的应用现状,包括VLM的预训练方法、迁移学习方法和知识蒸馏方法。VLM通过学习图像和文本之间的关联,在多种视觉任务上取得了显著成果,为计算机视觉领域带来了新的研究范式。未来,大规模多模态预训练、模型压缩与加速、跨语言跨模态迁移等方向将是VLM研究的重点。相信随着研究的深入,VLM将在更多视觉任务中发挥重要作用,推动人工智能向着更高水平发展。
参考文献
-
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR.
-
Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., ... & Le, Q. V. (2021). Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning (pp. 4904-4916). PMLR.
-
Zhang, J., Huang, J., Jin, S., & Lu, S. (2024). Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence.
-
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022). Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9), 2337-2348.
-
Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., ... & Lin, D. (2022). CLIP-Adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544.
-
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., ... & Girshick, R. (2023). Segment anything. arXiv preprint arXiv:2304.02643.









