
ViTamin: 视觉语言时代的革新性可扩展视觉模型
在人工智能和计算机视觉快速发展的今天,研究人员不断追求更高效、更强大的视觉模型。最近,一个名为ViTamin的创新项目引起了学术界和工业界的广泛关注。ViTamin不仅在多个基准测试中创造了新的记录,还为视觉模型的设计和应用开辟了新的方向。让我们深入了解这个令人兴奋的项目。
ViTamin的核心理念
ViTamin项目的核心理念是在视觉语言时代设计可扩展的视觉模型。随着多模态学习的兴起,视觉和语言的融合变得越来越重要。ViTamin正是在这一背景下应运而生,旨在创造一种能够在各种视觉任务中表现出色,同时又能与语言模型无缝集成的视觉模型。
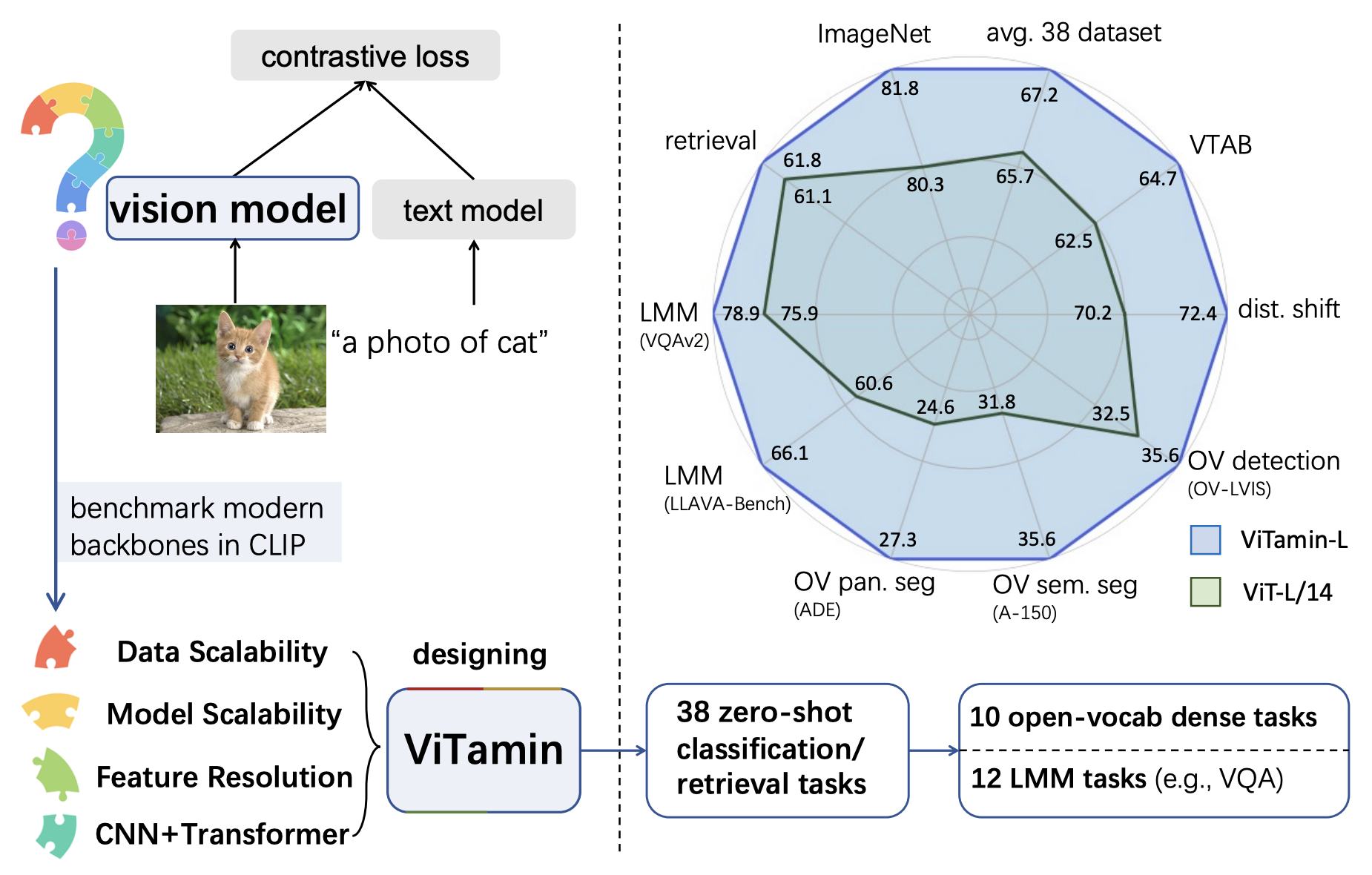
卓越的性能表现
ViTamin的表现令人印象深刻。以ViTamin-XL为例,它仅有436M参数,在公开的DataComp-1B数据集上训练后,就能在ImageNet零样本分类任务上达到82.9%的准确率。这一成绩不仅证明了ViTamin模型的效率,也展示了其强大的泛化能力。
在开放词汇分割任务中,ViTamin-L更是在七个基准测试中创造了新的最高纪录。这意味着ViTamin不仅在传统的图像分类任务上表现出色,在更复杂的语义分割任务中也能发挥强大的性能。
广泛的应用场景
ViTamin的应用范围非常广泛,涵盖了多个计算机视觉领域:
-
预训练和微调: ViTamin提供了完整的CLIP预训练和微调管道,以及零样本评估管道。这使得研究人员可以轻松地在自己的数据集上训练和评估ViTamin模型。
-
开放词汇检测和分割: ViTamin在开放词汇检测和分割任务中表现出色。例如,在OV-COCO和OV-LVIS等数据集上,ViTamin-L配合滑动F-ViT检测器取得了显著的性能提升。
-
大型多模态模型: ViTamin还推动了大型多模态模型(如LLaVA)的能力边界。在VQAv2、GQA等多个多模态理解任务中,ViTamin展现了优异的表现。
技术创新与实现
ViTamin的成功离不开其背后的技术创新。项目团队在视觉transformer的基础上进行了一系列优化,包括:
- 高效的注意力机制: 优化了自注意力计算,提高了模型在处理大规模图像数据时的效率。
- 多尺度特征提取: 设计了能够捕获不同尺度视觉信息的架构,增强了模型的表示能力。
- 与语言模型的无缝集成: 开发了专门的接口,使ViTamin能够与各种语言模型高效协作。
开源与社区支持
ViTamin项目得到了广泛的社区支持。它已经被timm和OpenCLIP等知名库官方支持。研究者可以通过简单的一行代码就能调用ViTamin模型:
model = timm.create_model('vitamin_xlarge_384')
此外,项目团队还在HuggingFace上发布了ViTamin模型卡片集合,方便研究者和开发者使用和评估模型。
未来展望
ViTamin的成功为视觉模型的设计和应用开辟了新的可能性。未来,我们可以期待:
- 更大规模的模型: 随着计算资源的增加,可能会出现参数量更大、性能更强的ViTamin变体。
- 跨模态应用的拓展: ViTamin在视觉-语言任务中的成功,可能会推动其在更多跨模态场景中的应用。
- 实时处理能力的提升: 优化ViTamin的推理速度,使其能够在实时应用中发挥作用。
- 领域特定的微调: 针对医疗、自动驾驶等特定领域对ViTamin进行微调,发挥其在专业领域的潜力。
结语
ViTamin项目展示了在视觉语言时代设计可扩展视觉模型的新方向。通过创新的架构设计和训练策略,ViTamin在多个任务中展现出卓越的性能,为计算机视觉和多模态学习领域带来了新的可能性。随着项目的持续发展和社区的广泛参与,我们有理由相信ViTamin将在未来的AI应用中发挥更加重要的作用。
对于有兴趣深入了解或使用ViTamin的研究者和开发者,可以访问ViTamin的GitHub仓库获取更多详细信息和代码实现。同时,关注HuggingFace上的ViTamin模型集合也是了解最新进展的好方法。
让我们期待ViTamin在推动视觉AI技术发展方面继续发挥重要作用,为创造更智能、更理解世界的AI系统贡献力量。🚀🔬👁️









