
语音重合成技术的新突破
近年来,随着深度学习技术的发展,语音合成领域取得了长足的进步。然而,如何从语音中提取出富有表现力且可控的表示,一直是该领域面临的挑战之一。最近,Facebook AI研究院提出了一种新的语音重合成方法,通过利用自监督学习和表示解耦技术,在语音重建质量和可控性方面都取得了显著的进展。
什么是语音重合成?
语音重合成指的是将语音信号转换成某种中间表示,然后再从该表示重建出原始语音的过程。与传统的语音合成不同,重合成的目标是尽可能还原原始语音,同时提供对合成过程的灵活控制。
新方法的核心思想
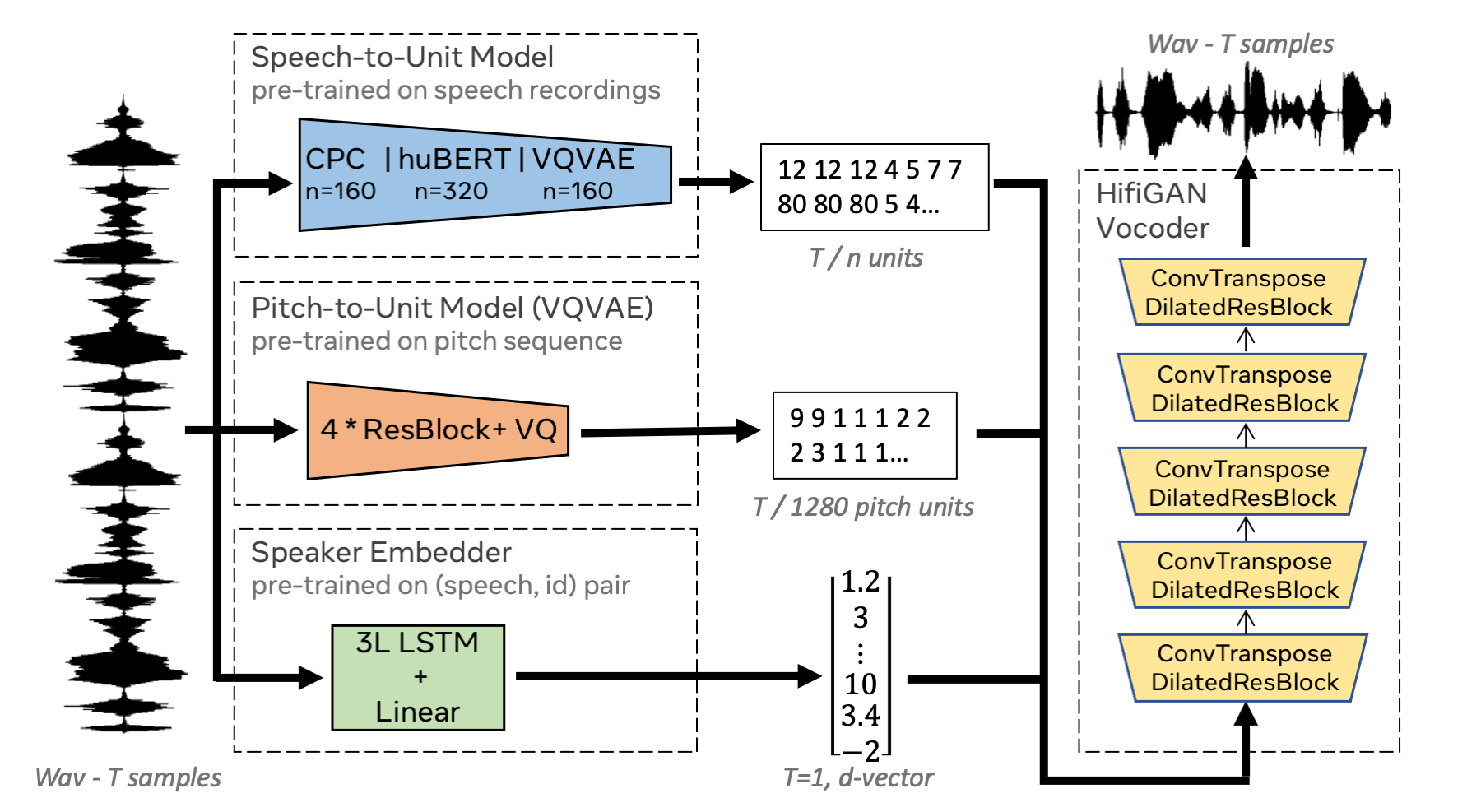
Facebook AI提出的新方法的核心思想是利用自监督学习从语音中提取出离散的、解耦的表示。具体来说,它分别提取了三类低比特率的表示:
- 语音内容表示
- 韵律信息表示
- 说话人身份表示
通过将这些表示解耦,该方法能够在重建语音的同时,实现对语音各个方面的精细控制。
技术细节
该方法主要包含以下几个关键步骤:
-
使用自监督学习方法(如HuBERT、CPC等)从原始语音中提取离散表示。
-
设计专门的网络结构,将提取的表示解耦成内容、韵律和说话人身份三个部分。
-
使用神经声码器(如HiFi-GAN)从解耦的表示重建语音波形。
-
在训练过程中,采用多任务学习的方式,同时优化重建质量和表示解耦程度。
实验结果
研究人员在多个数据集上评估了该方法的性能,结果表明:
-
在语音重建质量上,该方法优于现有的基线方法。
-
在F0重建、说话人识别等任务上,展现出了良好的表示解耦效果。
-
通过人工评估,证实了重建语音的可懂度和整体质量。
-
在低比特率语音编码任务中,该方法以365 bit/s的速率实现了高质量的语音重建。
应用前景
这项技术在多个领域都具有广阔的应用前景:
-
语音编码: 可用于开发超低比特率的语音编解码器,适用于带宽受限的通信场景。
-
声音转换: 通过替换说话人身份表示,可以实现灵活的声音转换。
-
语音增强: 可以通过操作解耦表示来去除语音中的噪声和混响。
-
情感语音合成: 通过控制韵律表示,可以生成具有不同情感色彩的语音。
未来展望
尽管该方法已经取得了令人瞩目的成果,但研究人员认为还有进一步提升的空间:
-
提高表示的解耦程度,实现更精细的语音控制。
-
探索在更多语音相关任务中应用该技术。
-
优化模型结构和训练策略,进一步提高重建质量和计算效率。
-
研究如何将该技术与其他语音处理方法(如文本到语音)结合,开发更强大的语音应用。
总的来说,这项语音重合成技术为语音处理领域开辟了新的研究方向,有望推动语音技术在通信、娱乐、辅助技术等多个领域的应用与创新。随着进一步的发展和完善,我们可以期待在不久的将来看到更多基于这一技术的令人惊叹的语音应用。









