
VoiceSmith简介
VoiceSmith是一个开源的文本转语音(TTS)工具,旨在让训练和使用语音合成模型变得简单易用。它基于修改版的DelightfulTTS和UnivNet,可以在用户自己的数据集上微调出高质量的TTS模型。VoiceSmith的主要特点包括:
- 支持训练单说话人和多说话人模型
- 无需编程经验即可使用
- 提供数据集预处理工具,如自动文本标准化
- 预训练模型基于5000说话人数据集
- 开源且免费使用
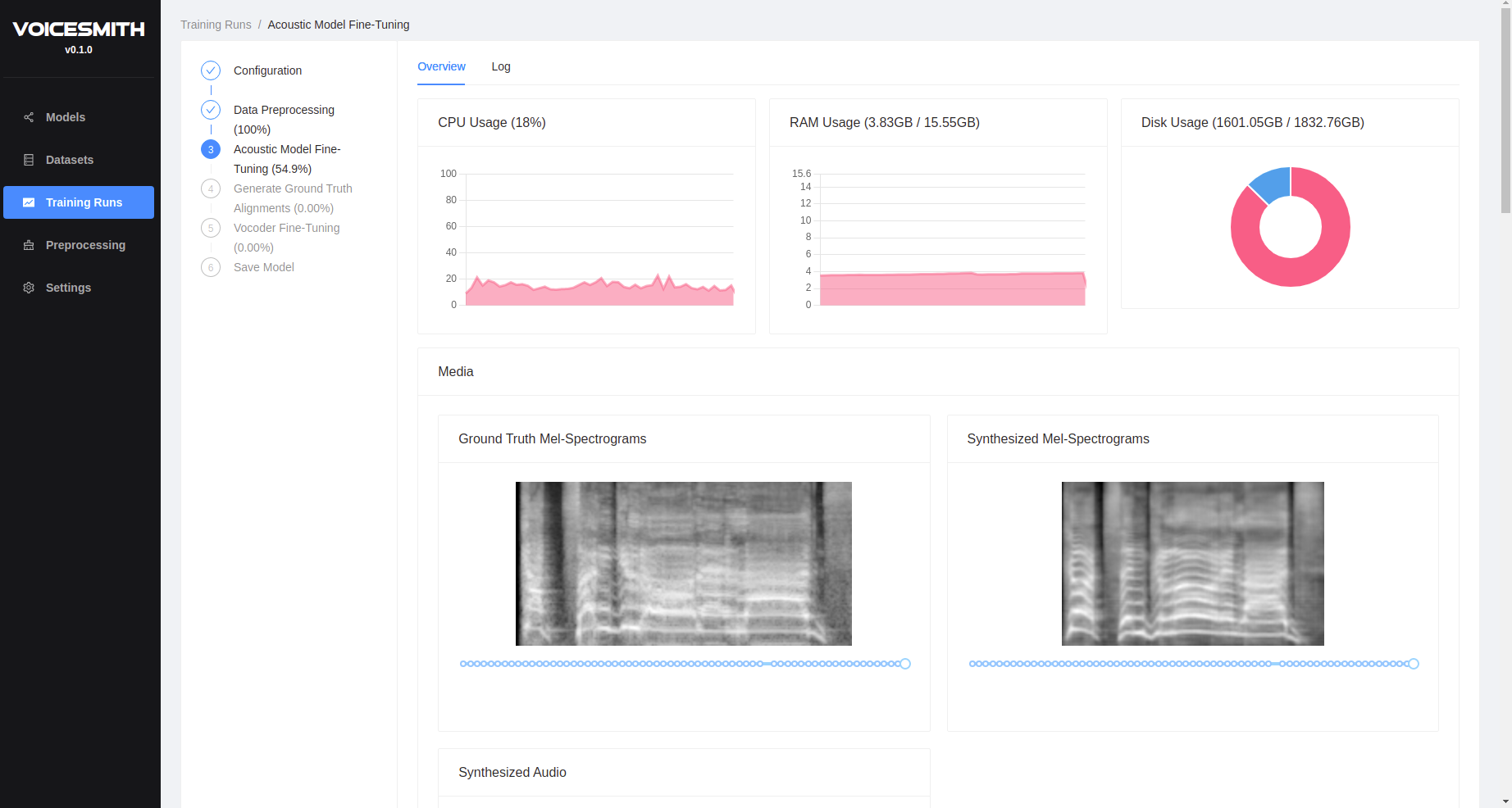
学习资源
官方文档
- VoiceSmith官方文档 - 最全面的使用指南和API文档
代码仓库
- GitHub仓库 - 源代码,安装指南和问题追踪
下载安装
- GitHub Releases - 下载最新版本安装包
在线演示
- Colab演示 - 使用60个说话人的情感数据集训练的模型演示
快速入门
- 从GitHub Releases下载最新安装包
- 运行安装程序
- 启动VoiceSmith,开始探索TTS模型训练和使用
开发指南
如果您想参与VoiceSmith的开发,可以按照以下步骤:
- 确保安装了最新版本的Node.js
- 克隆代码仓库:
git clone https://github.com/dunky11/voicesmith - 安装依赖:
cd voicesmith && npm install - 下载必要的资源文件并放入assets文件夹
- 启动项目:
npm start
社区支持
- GitHub Issues - 报告问题或提出改进建议
- 欢迎通过Star项目和提交Pull Request来支持VoiceSmith的发展
VoiceSmith作为一个强大而易用的开源TTS工具,正在不断发展完善。无论您是语音技术爱好者还是专业研究人员,都可以利用VoiceSmith探索语音合成的无限可能。希望这份学习资源汇总能帮助您快速上手VoiceSmith,开启语音合成的精彩旅程!










