
WebCPM:开创中文长文问答新范式
在自然语言处理领域,长文问答一直是一个具有挑战性的任务。如何准确理解复杂问题并给出详尽的回答,需要模型具备强大的知识获取和推理能力。近日,清华大学自然语言处理实验室(THUNLP)发布的WebCPM项目,为中文长文问答带来了创新性的解决方案。
项目概览
WebCPM(Web-based Chinese Pre-trained Model)是一个基于交互式网络搜索的中文长文问答系统。该项目由清华大学自然语言处理实验室开发,旨在通过结合大规模预训练语言模型和实时网络搜索,实现高质量的中文长文问答。
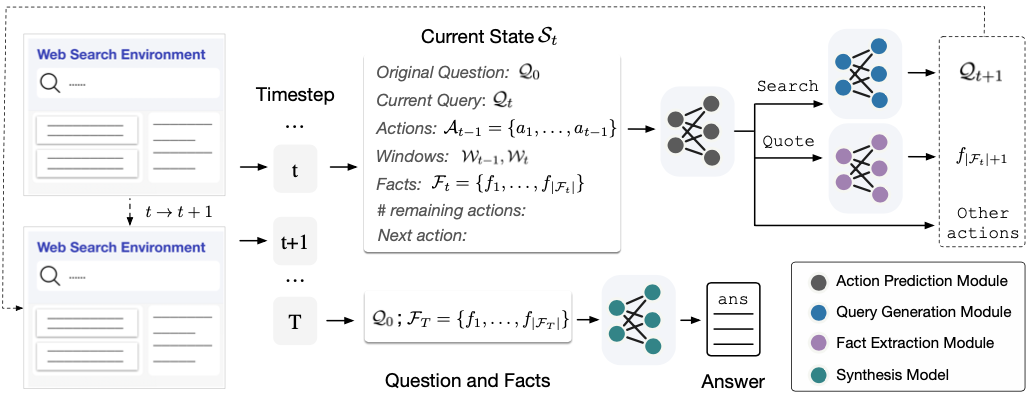
如上图所示,WebCPM的核心思想是模拟人类在回答复杂问题时的行为 - 通过网络搜索获取相关信息,然后基于搜集到的事实生成答案。具体来说,WebCPM包含以下关键组件:
-
网络搜索界面:允许模型和人类用户进行实时网络搜索。
-
大规模预训练语言模型:基于CPM-Bee,参数量达100亿。
-
数据集:包含5500个高质量的问答对,以及相关的支持事实和网络搜索行为。
-
多任务训练:包括搜索查询生成、行为预测、支持事实提取和答案合成等任务。
技术创新
WebCPM的主要技术创新点包括:
-
交互式网络搜索:不同于传统的静态知识库,WebCPM可以实时访问互联网获取最新信息。这大大扩展了模型的知识范围,使其能够回答更广泛的问题。
-
人类行为模拟:WebCPM通过学习人类的网络搜索行为,实现了更加智能和高效的信息检索。例如,它可以根据问题动态生成搜索查询,并从网页中提取关键信息。
-
多任务学习框架:WebCPM将网络搜索过程分解为多个子任务,如查询生成、行为预测等,并通过多任务学习方式进行联合优化。这种方法有助于提高模型的整体性能。
-
大规模中文预训练模型:WebCPM基于100亿参数的CPM-Bee模型,这是目前最大的开源中文预训练语言模型之一。强大的语言理解和生成能力为高质量问答奠定了基础。
数据集构建
WebCPM项目的一个重要贡献是构建了高质量的中文长文问答数据集。该数据集包含:
- 5500个问答对:涵盖广泛的主题和复杂度
- 14,315个支持事实:从网页中提取的关键信息片段
- 121,330个网络搜索行为:记录了人类在回答问题时的搜索过程
这些数据不仅用于训练WebCPM模型,也为中文长文问答研究提供了宝贵的资源。
实验结果
WebCPM在多个评估指标上都取得了优秀的表现:
- 搜索查询生成:Rouge-L分数达到0.5以上
- 行为预测:F1分数超过0.7
- 支持事实提取:Rouge-L分数接近0.6
- 答案合成:Rouge-L分数超过0.4
这些结果表明,WebCPM能够有效地执行网络搜索、提取关键信息并生成高质量的答案。
开源贡献
为了推动中文自然语言处理的发展,WebCPM项目开源了以下资源:
- 网络搜索界面:可用于数据标注和模型评估
- 数据集:包括问答对、支持事实和搜索行为
- 实现代码:涵盖数据预处理、模型训练和评估等完整流程
- 模型参数:开放了预训练和微调后的模型权重
这些开源资源为研究人员和开发者提供了宝贵的工具,有助于进一步推动中文长文问答技术的进步。
应用前景
WebCPM的技术创新为中文长文问答带来了广阔的应用前景:
-
智能客服:能够回答复杂的产品和服务相关问题,提升用户体验。
-
教育辅助:为学生提供详细的学习解答和拓展阅读材料。
-
科研助手:帮助研究人员快速获取和综合最新的科研信息。
-
决策支持:为管理者提供全面的信息汇总和分析,辅助决策制定。
-
内容创作:协助作者进行资料收集和内容生成,提高创作效率。
未来展望
尽管WebCPM已经取得了显著的成果,但中文长文问答仍有很大的发展空间。未来的研究方向可能包括:
-
提高搜索效率:优化搜索策略,减少不必要的查询次数。
-
增强事实验证:加强模型对信息可靠性的判断能力,避免错误信息的传播。
-
拓展多模态能力:整合图像、视频等多模态信息,提供更全面的答案。
-
强化推理能力:提升模型在复杂问题上的逻辑推理和知识整合能力。
-
个性化定制:根据用户的背景知识和偏好,提供定制化的回答。
WebCPM的发布标志着中文长文问答技术迈出了重要的一步。通过结合大规模语言模型和交互式网络搜索,WebCPM为解决复杂问答任务提供了新的思路。随着技术的不断进步和应用场景的拓展,我们有理由期待中文自然语言处理在不久的将来会迎来更大的突破。

作为一个开源项目,WebCPM也欢迎更多的研究者和开发者参与贡献。无论是改进模型性能,扩展数据集,还是开发新的应用,都有助于推动这一领域的发展。让我们共同期待WebCPM及其衍生技术在未来为中文自然语言处理带来的更多可能性。









