
XrayGLM: 开创性的中文医学多模态大模型
在人工智能与医疗健康深度融合的今天,一个能够"看懂"医学影像并给出专业诊断报告的AI模型无疑具有重大意义。近日,由澳门理工大学应用科学学院的研究团队开发的XrayGLM模型,作为首个能够对胸部X光片进行诊断和描述的中文多模态医学大模型,引起了学术界和医疗界的广泛关注。
XrayGLM的诞生背景
随着ChatGPT等大语言模型(LLM)的兴起,多模态AI模型在通用领域取得了长足进展。然而在专业性要求极高的医疗领域,此类模型的应用却相对滞后。虽然已有一些英文医学多模态模型的尝试,但中文领域仍是一片空白。XrayGLM正是为填补这一空白而生,旨在推动中文医学多模态大模型的发展。
技术原理与创新
XrayGLM采用了视觉模型与语言模型相结合的方法。它以VisualGLM-6B为基础,通过在中文胸部X光片诊断数据集上进行微调,使模型具备了"看"懂X光片并用自然语言描述诊断结果的能力。
具体来说,XrayGLM的主要创新点包括:
-
构建了一个
X光影像-诊断报告对的中文医学多模态数据集,为模型训练提供了高质量的数据支持。 -
在VisualGLM-6B的基础上进行微调,使模型能够理解胸部X光片的视觉特征,并将其转化为专业的诊断描述。
-
采用LoRA等高效的微调方法,在有限的计算资源下实现了模型性能的显著提升。
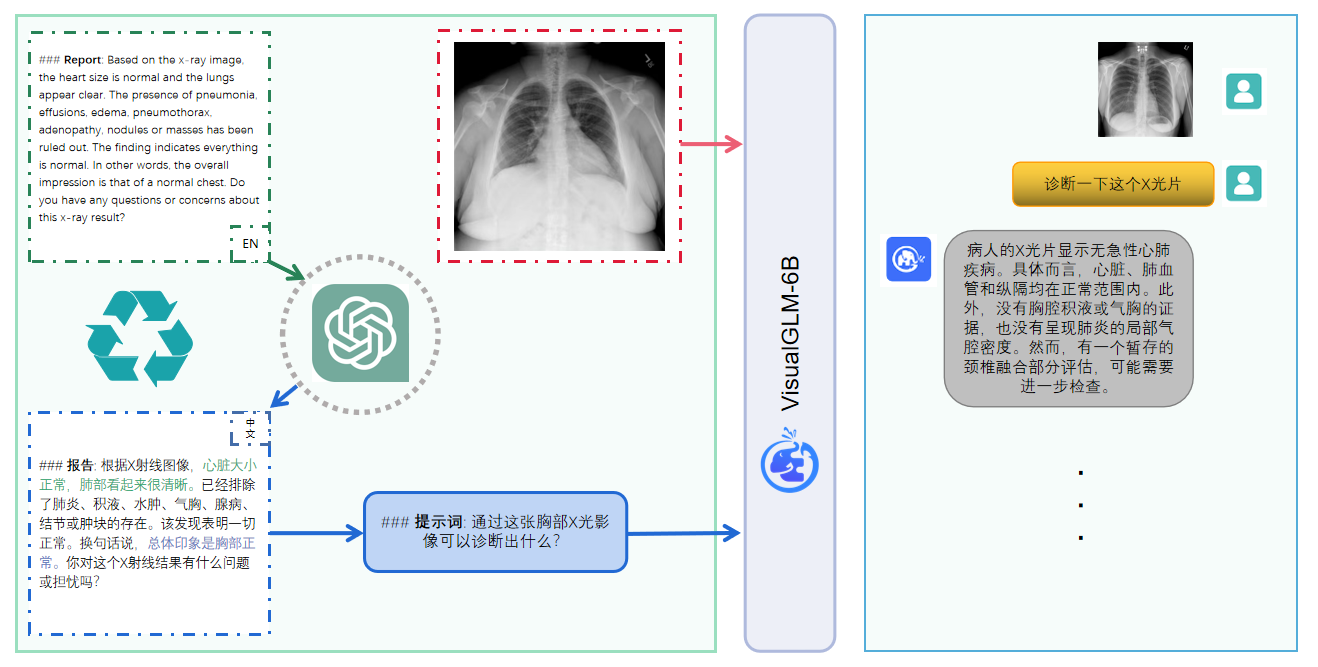
数据集构建
XrayGLM的训练数据主要来源于两个公开数据集:
- MIMIC-CXR:包含377,110张胸部X光片图像和227,827份相关报告。
- OpenI:来自印第安纳大学医院,包含6,459张图像和3,955份报告。
研究团队对这些原始数据进行了预处理和翻译,最终形成了可用于训练的中文数据集。其中,OpenI-zh数据集包含6,423对X光影像-诊断报告样本,为XrayGLM的训练提供了重要支持。
模型训练与部署
XrayGLM的训练过程主要包括以下步骤:
-
环境配置:安装必要的依赖库,如SwissArmyTransformer等。
-
数据准备:将处理好的中文诊疗报告和X光影像放入指定文件夹。
-
模型训练:使用LoRA等微调方法对VisualGLM-6B进行训练。
-
模型推理:支持CLI和WebUI两种方式进行模型推理。
研究团队还开源了两个版本的模型权重:XrayGLM-300和XrayGLM-3000,以供学术研究使用。
XrayGLM的能力展示
XrayGLM在胸部X光片的诊断描述上展现出了令人惊喜的能力。以下是一个实际案例:
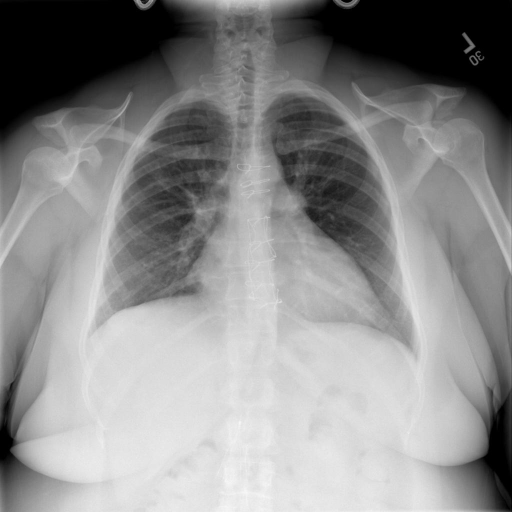
对于这张X光片,XrayGLM给出的诊断描述是:
"X光片显示,心脏大小正常。肺部没有气胸或胸腔积液的证据。骨骼结构看起来没有任何异常。总的来说,X光片表明没有发现急性心肺疾病的迹象。"
这一描述与人类医生的诊断报告高度一致,展示了XrayGLM在医学影像理解和自然语言生成方面的卓越能力。
除了单次诊断,XrayGLM还支持多轮对话,能够回答用户关于X光片的进一步提问,如是否存在某种特定疾病、日常生活中应注意的事项等。这种交互式的诊断体验,为医患沟通提供了新的可能性。
XrayGLM的未来展望
尽管XrayGLM已经展现出了令人瞩目的能力,但研究团队认为它仍有巨大的发展空间:
-
数据驱动:通过在更大规模、更高质量的数据集上进行预训练和微调,可以进一步提升模型的性能。
-
模型优化:加强语言模型部分,使XrayGLM不仅能给出专业的医学诊断,还能提供更富有人文关怀的回答。
-
扩大规模:考虑使用更大参数量的基础模型(如13B版本)进行微调,以获得更强大的性能。
结语
XrayGLM的出现,标志着中文医学多模态AI模型研究迈出了重要一步。它不仅为医学影像诊断领域带来了新的可能性,也为AI辅助医疗的发展指明了方向。随着模型的不断优化和完善,我们有理由相信,XrayGLM将在提高医疗诊断效率、减轻医生工作负担、改善患者就医体验等方面发挥越来越重要的作用。
然而,我们也应该清醒地认识到,XrayGLM及类似的AI模型目前仍处于研究阶段,其输出结果不能作为实际医疗诊断的依据。在使用这类模型时,我们应该保持谨慎态度,尊重医学专业性,将其视为辅助工具而非替代品。
XrayGLM的开源为推动中文医学AI的发展做出了重要贡献。我们期待看到更多研究者和开发者参与到这一领域,共同推动医学AI技术的进步,为人类健康事业做出贡献。









