
YOLOv7简介
YOLOv7是YOLO(You Only Look Once)系列目标检测算法的最新版本,由Chien-Yao Wang、Alexey Bochkovskiy和Hong-Yuan Mark Liao于2022年7月提出。作为实时目标检测的最新突破,YOLOv7在速度和精度上都超越了之前的模型,为计算机视觉领域带来了新的可能性。
YOLOv7的主要特点
-
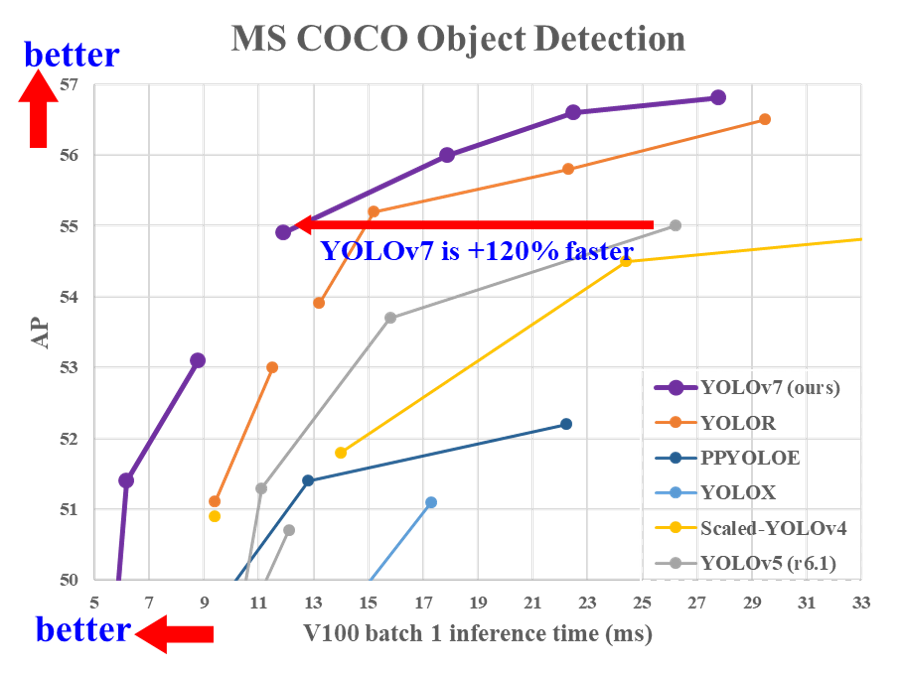
更高的精度:在MS COCO数据集上,YOLOv7达到了51.4% AP的精度,超过了之前的所有实时目标检测器。
-
更快的速度:YOLOv7可以在161 FPS的速度下运行,远超其他模型。
-
更高的效率:相比其他模型,YOLOv7减少了约40%的参数量和50%的计算量。
-
更强的通用性:YOLOv7不需要预训练权重,可以直接在小数据集上训练。
YOLOv7的创新点
YOLOv7的优异性能来源于多项创新:
1. 扩展高效层聚合网络(E-ELAN)
YOLOv7引入了E-ELAN模块,通过"扩展、打乱、合并基数"的方式,提高了网络的学习能力,同时不破坏原有的梯度路径。
2. 模型缩放技术
YOLOv7提出了一种新的复合模型缩放方法,可以同时调整网络的深度和宽度,保持模型架构的最优结构。
3. 计划重参数化
YOLOv7采用了计划重参数化策略,根据梯度流传播路径来决定网络中哪些模块应该使用重参数化技术。
4. 辅助头粗到细监督
YOLOv7引入了辅助检测头,并采用从粗到细的监督策略,提高了网络的训练效率。
YOLOv7的应用场景
YOLOv7凭借其出色的性能,可以应用于多个领域:
-
自动驾驶:实时检测道路上的车辆、行人和障碍物。
-
安防监控:快速识别异常行为和可疑物品。
-
工业制造:进行产品质量检测和缺陷识别。
-
零售分析:追踪顾客行为和商品摆放。
-
医疗影像:辅助医生进行疾病诊断。

YOLOv7的使用指南
安装
推荐使用Docker环境:
nvidia-docker run --name yolov7 -it -v your_coco_path/:/coco/ -v your_code_path/:/yolov7 --shm-size=64g nvcr.io/nvidia/pytorch:21.08-py3
训练
单GPU训练:
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
多GPU训练:
python -m torch.distributed.launch --nproc_per_node 4 --master_port 9527 train.py --workers 8 --device 0,1,2,3 --sync-bn --batch-size 128 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
推理
在视频上进行推理:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
在图像上进行推理:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
YOLOv7的未来展望
YOLOv7的作者还展示了将姿态估计和实例分割任务统一到YOLO框架中的初步成果,这预示着YOLO系列算法在未来可能会有更广泛的应用。

结语
YOLOv7作为目标检测领域的最新突破,不仅在性能上超越了之前的模型,还引入了多项创新技术。它的出现为实时目标检测带来了新的可能性,相信在未来会有更多基于YOLOv7的应用出现在我们的日常生活中。无论是研究人员还是工程师,都可以尝试使用YOLOv7来提升自己项目的性能。
随着计算机视觉技术的不断发展,我们期待看到更多像YOLOv7这样的创新成果,推动人工智能技术在各个领域的应用和发展。









