
Youku-mPLUG:开创中文视频-语言预训练新纪元
在人工智能和计算机视觉领域,视频理解一直是一个充满挑战的研究方向。随着多模态预训练模型的兴起,视频-语言预训练模型在各类视频理解任务中展现出了强大的潜力。然而,相比于图像-文本预训练,大规模高质量的视频-语言数据集仍然稀缺,尤其是中文领域。为了推动中文视频-语言预训练的发展,阿里巴巴达摩院联合优酷视频推出了Youku-mPLUG数据集。这是目前公开的最大规模中文视频-语言数据集,包含1000万对精选的视频-文本数据对,为中文视频理解任务提供了全新的基准和预训练资源。
Youku-mPLUG数据集概览
Youku-mPLUG数据集的构建基于优酷视频平台,经过严格的安全、多样性和质量筛选。数据集包含以下核心特征:
-
规模庞大:总计1000万对视频-文本数据,是目前公开的最大规模中文视频-语言数据集。
-
类别丰富:覆盖20个大类和45个细分类别,涵盖范围广泛。
-
高质量:所有视频经过人工审核,确保内容安全、多样和高质量。
-
版权许可:所有数据均获得合法授权,可用于学术研究。

上图展示了Youku-mPLUG数据集中的一些视频剪辑和对应标题示例。我们可以看到,数据集涵盖了各种类型的视频内容,如美食烹饪、动物世界、体育运动等,展现了丰富的多样性。
数据集统计分析
Youku-mPLUG数据集中的1000万视频分布在20个大类和45个细分类别中。下图展示了各个类别的数据分布情况:
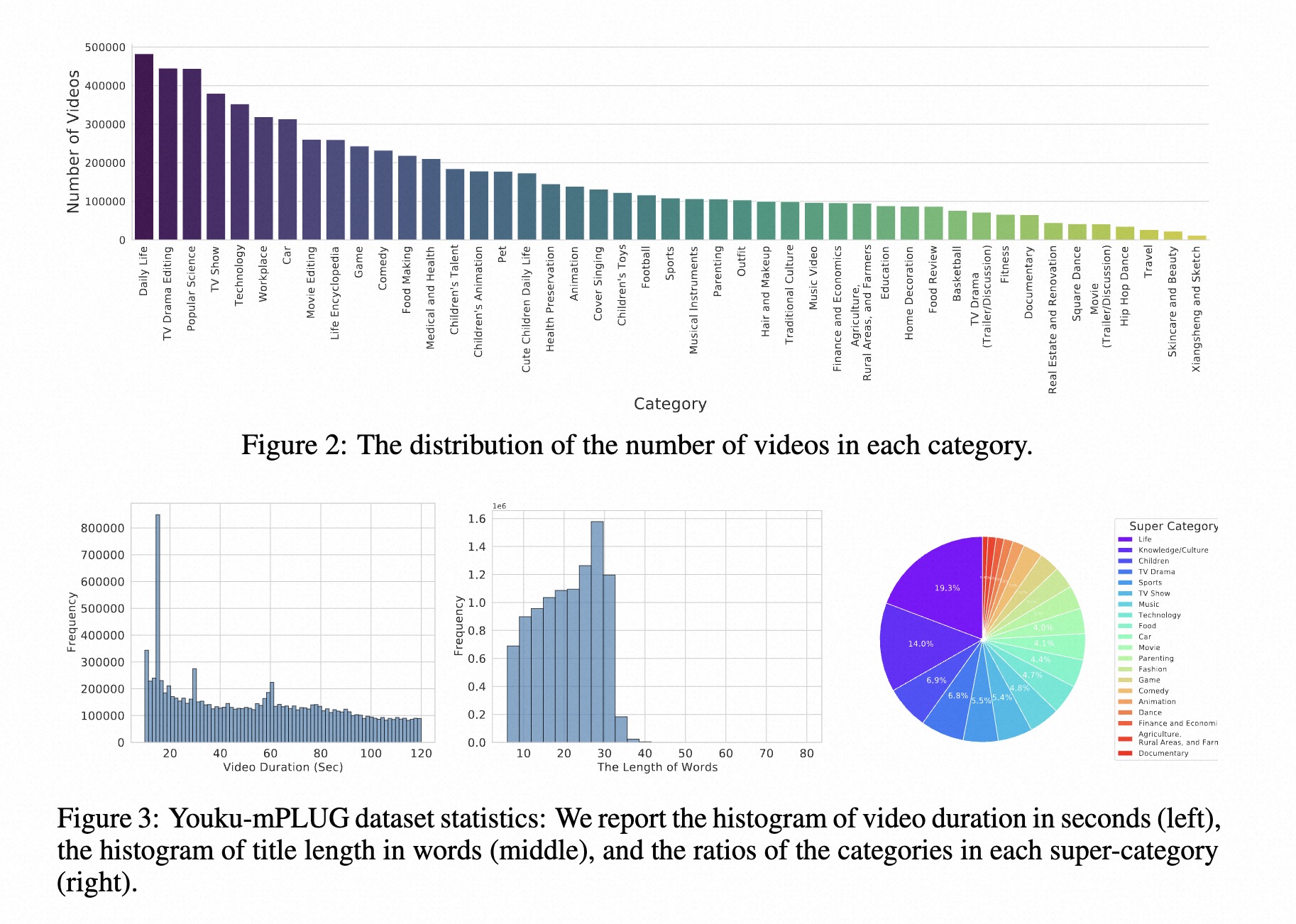
从图中可以看出,数据集在各个类别之间分布相对均衡,没有出现严重的类别不平衡问题。主要类别包括:
- 娱乐: 占比约15%
- 生活: 占比约12%
- 游戏: 占比约10%
- 音乐: 占比约9%
- 体育: 占比约8%
这种均衡的类别分布有助于模型学习到更加全面和通用的视频理解能力。
下游任务基准
为了全面评估预训练模型的能力,Youku-mPLUG还提供了3个下游多模态视频基准数据集,涵盖以下任务:
-
视频类别预测:给定视频和对应标题,预测视频所属类别。
-
视频-文本检索:在给定的视频和文本集合中,实现视频检索文本和文本检索视频。
-
视频描述生成:给定一段视频,生成描述其内容的文本。
这些下游任务涵盖了视频理解的多个关键方面,可以全面评估模型的视频内容理解、跨模态匹配以及文本生成能力。
mPLUG-Video模型
基于Youku-mPLUG数据集,研究人员开发了mPLUG-Video模型。该模型采用了多模态预训练的框架,能够同时处理视频和文本输入。mPLUG-Video模型有两个版本:
-
mPLUG-Video (1.3B / 2.7B): 基于GPT-3架构,参数量分别为13亿和27亿。
-
mPLUG-Video (BloomZ-7B): 基于BloomZ-7B大语言模型,总参数量为70亿。
这两个版本的模型在Youku-mPLUG数据集上进行了预训练,然后在下游任务上进行了微调。
实验结果
在下游任务的验证集上,mPLUG-Video模型展现出了优秀的性能:
-
视频类别预测:
- mPLUG-Video (1.3B): Top-1准确率 77.5%
- mPLUG-Video (2.7B): Top-1准确率 80.5%
-
视频-文本检索:
- mPLUG-Video (1.3B): R@1 53.4%, R@5 79.6%
- mPLUG-Video (2.7B): R@1 56.9%, R@5 82.1%
-
视频描述生成:
- mPLUG-Video (2.7B): CIDEr得分 68.9
这些结果表明,通过在Youku-mPLUG数据集上预训练,mPLUG-Video模型在各项视频理解任务上都取得了显著的性能提升。特别是在视频类别预测任务中,相比未经预训练的模型,性能提升高达23.1%。
零样本能力
除了在特定任务上的表现,mPLUG-Video模型还展现出了强大的零样本学习能力。以下是两个零样本理解的案例:
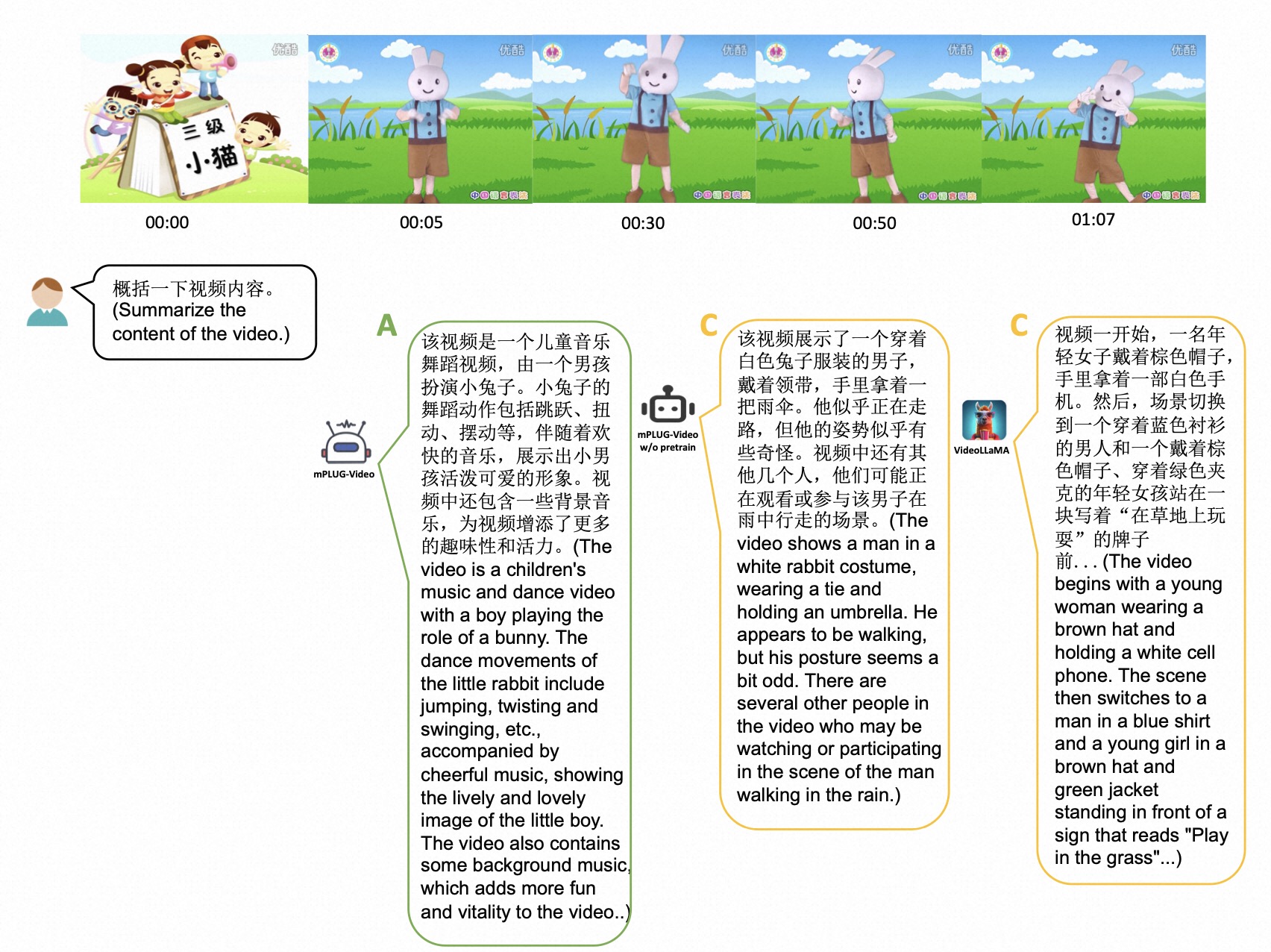
在这个例子中,模型能够准确理解视频中的场景,识别出"沙发"和"桌子",并正确描述了画面中的主要元素。

这个例子展示了模型对动作和事件的理解能力,准确描述了"女孩在滑滑板"的场景。
这些零样本案例表明,通过在Youku-mPLUG数据集上的预训练,模型不仅学习到了特定任务的能力,还获得了更广泛的视频理解和描述能力。
模型应用与开源
为了推动中文视频-语言预训练的研究和应用,研究团队已经将Youku-mPLUG数据集和预训练模型开源。感兴趣的研究者可以通过以下方式获取资源:
研究者可以基于这些资源进行进一步的模型优化、任务适配或应用开发。
总结与展望
Youku-mPLUG数据集的发布为中文视频-语言预训练领域带来了新的机遇。这个大规模、高质量的数据集不仅填补了中文视频理解研究的数据空白,还为开发更强大的视频理解模型提供了基础。基于Youku-mPLUG训练的mPLUG-Video模型在多个下游任务中展现出的卓越性能,证明了该数据集的价值。
未来,我们期待看到更多基于Youku-mPLUG的创新研究和应用,例如:
- 探索更高效的预训练方法,进一步提升模型性能。
- 将mPLUG-Video模型应用于更多视频理解任务,如视频问答、视频摘要等。
- 结合大语言模型,开发更智能的视频内容分析和生成系统。
- 在实际应用场景中部署和优化模型,如视频推荐、内容审核等。
Youku-mPLUG的开源为整个研究社区提供了宝贵的资源,我们相信它将推动中文视频-语言预训练技术的快速发展,为未来的人工智能和计算机视觉研究开辟新的方向。









