
Zingg:用机器学习实现大规模数据整合与实体解析
在当今数据驱动的商业环境中,整合分散在多个系统中的客户数据、构建单一客户视图已成为企业的一项关键挑战。Zingg作为一个开源的实体解析工具,正是为解决这一难题而生。本文将深入介绍Zingg的功能特性、技术原理以及应用场景,帮助读者了解如何利用这一强大工具实现大规模数据整合。
Zingg解决的核心问题
现实世界的数据中,同一客户的记录往往分散在多个系统中,且存在各种细微差异。这给数据分析和客户洞察带来了巨大挑战:
- 无法建立准确的客户生命周期价值
- 忠诚度计划和营销活动效果难以评估
- 客户分群等AI算法的结果失真
- 数据仓库中的维度表存在重复,影响分析质量

传统的ETL流程虽然能解决数据抽取和加载的问题,但在数据转换和整合方面仍需要大量人工工作。Zingg的出现填补了这一空白,为分析工程师和数据科学家提供了一种快速、可扩展的方法来构建核心业务实体的单一真实源。
Zingg的核心功能与特性
作为一个基于机器学习的实体解析工具,Zingg具有以下关键特性:
-
支持多种实体类型:可处理客户、患者、供应商、产品等各类实体数据。
-
多源数据连接能力:可连接本地和云端文件系统、企业应用、关系型与NoSQL数据库、数据仓库等多种数据源。
-
大规模处理能力:采用分布式架构,可扩展到处理海量数据。
-
交互式训练数据构建:通过主动学习方法,仅需少量样本即可构建高精度模型。
-
支持自定义匹配函数:可定义特定领域的匹配规则以提高准确性。
-
多语言支持:除英语外,还支持中文、泰语、日语、印地语等多种语言。
这些特性使Zingg成为多个场景下的理想选择:
- 跨系统构建统一的客户和供应商视图
- 大规模实体解析用于反洗钱、KYC等合规场景
- 数据去重和质量提升
- 身份解析
- 并购中的数据整合
- 外部数据的匹配与丰富
- 客户家庭关系建立
Zingg的技术原理
Zingg主要通过学习两个模型来实现高效的实体解析:
- 阻塞模型(Blocking Model)
传统的实体匹配需要对输入的每条记录进行两两比对,导致比较次数随数据量呈平方增长。Zingg通过学习一个聚类/阻塞模型,将相似记录索引到一起,大大减少了需要比较的记录对数量。典型情况下,Zingg只需比较整个问题空间的0.05%-1%。
- 相似度模型(Similarity Model)
相似度模型用于预测哪些记录对是匹配的。它仅在同一个块/簇内的记录间运行,进一步提高了处理大型数据集的效率。该模型是一个分类器,可以预测那些不完全相同但可能属于同一实体的记录之间的相似度。
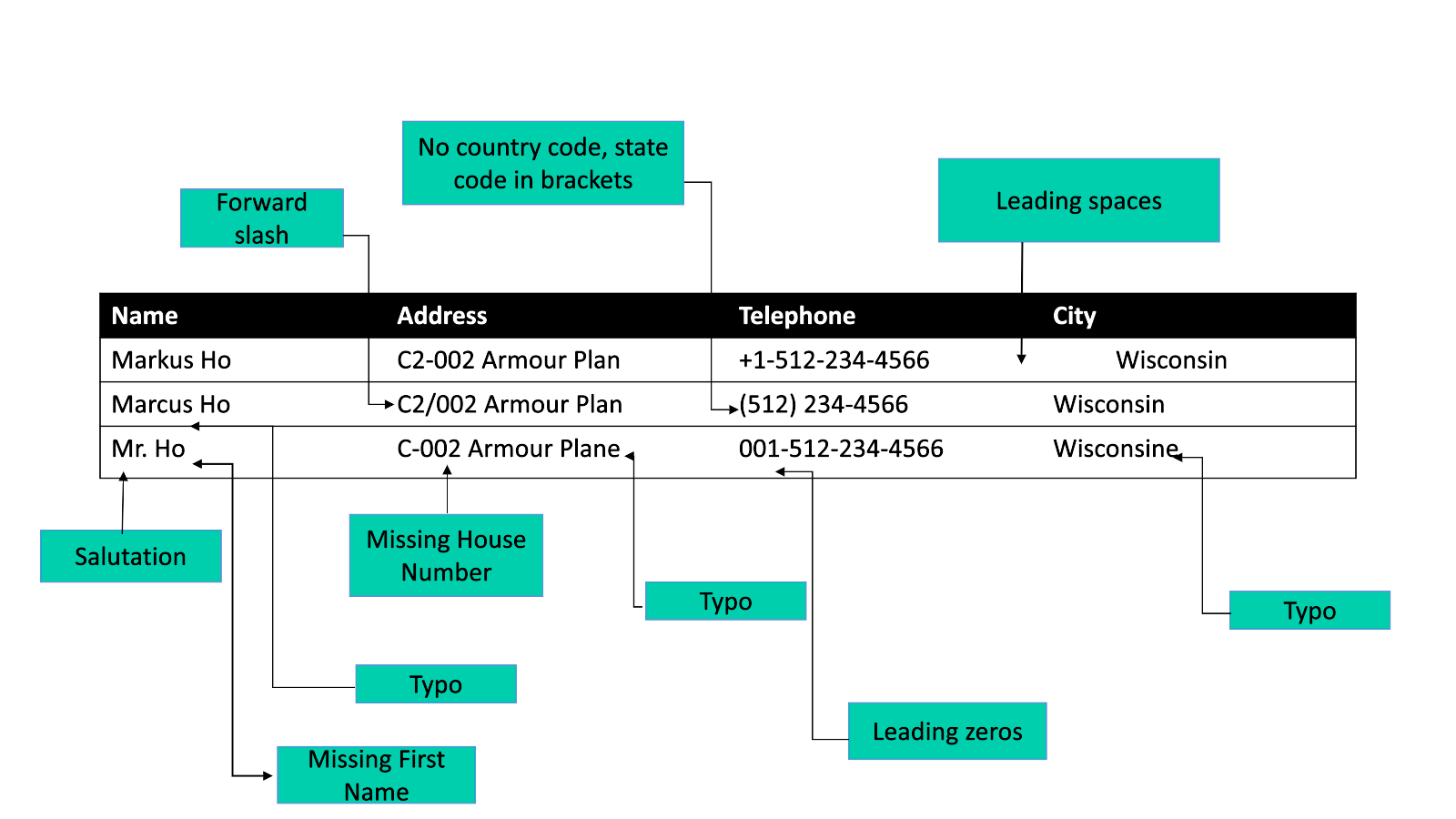
为了构建这些模型,Zingg提供了一个交互式学习器,可以快速构建训练集:
Zingg的实际应用
Zingg可以在多个行业和场景中发挥重要作用:
-
零售与电商:整合线上线下客户数据,构建360度客户视图。
-
金融服务:实现跨部门、跨产品线的客户信息整合,支持反欺诈和风控。
-
医疗健康:整合患者电子健康记录,提供全面的病史视图。
-
制造业:整合供应商和产品数据,优化供应链管理。
-
公共部门:整合公民数据,提供更高效的公共服务。
-
电信:整合用户账户信息,提供个性化服务和精准营销。
快速上手Zingg
要开始使用Zingg,最简单的方法是通过Docker运行预构建模型:
docker pull zingg/zingg:0.4.0
docker run -it zingg/zingg:0.4.0 bash
./scripts/zingg.sh --phase match --conf examples/febrl/config.json
更多详细步骤可参考Zingg文档。
Zingg的开源生态
Zingg是一个活跃的开源项目,欢迎社区贡献:
项目采用AGPL v3.0许可证,允许自由使用、修改和分发。
结语
在数据驱动决策日益重要的今天,Zingg为企业提供了一个强大的工具,帮助他们突破数据孤岛的限制,构建统一且可信的实体视图。通过机器学习和分布式处理,Zingg能够高效地处理大规模数据集,适应各种复杂的实体解析场景。无论是提升客户体验、优化运营效率,还是支持高级分析,Zingg都能为企业带来显著价值。随着数据量的持续增长和数据源的日益多样化,Zingg这样的工具将在现代数据栈中扮演越来越重要的角色。









