
AsyncDiff: 非同步去噪加速扩散模型的并行推理
近年来,扩散模型在图像生成、视频生成等多个领域展现出了卓越的性能。然而,扩散模型的推理过程通常需要多步顺序去噪,这导致了高延迟的问题,限制了其在实际应用中的使用。为了解决这一挑战,来自新加坡国立大学学习与视觉实验室的研究团队提出了一种名为AsyncDiff的创新方法,旨在通过异步去噪实现扩散模型的并行推理加速。
AsyncDiff的核心思想
AsyncDiff的核心思想是将传统的顺序去噪过程转变为异步并行的过程。具体来说,该方法将复杂的噪声预测模型分解为多个组件,并将每个组件分配到不同的设备上。为了打破这些组件之间的依赖链,AsyncDiff巧妙地利用了连续扩散步骤中隐藏状态之间的高度相似性,将常规的顺序去噪转换为异步过程。这样,每个组件就能够在独立的设备上并行计算,从而显著降低了推理延迟。
上图展示了AsyncDiff的异步去噪过程概览。去噪模型εθ被分为四个组件以便清晰说明。在预热阶段之后,每个组件的输入都会提前准备好,从而打破了依赖链,实现了并行处理。
AsyncDiff的主要优势
-
通用性强: AsyncDiff是一种即插即用的加速方案,可以应用于多种扩散模型,包括Stable Diffusion系列、ControlNet、AnimateDiff等。
-
显著提升推理速度: 在多个GPU设备上,AsyncDiff能够实现2-4倍的加速比。例如,在4个设备上运行SDXL时,AsyncDiff可以将50步推理时间从13.81秒降低到4.98秒,实现了2.8倍的加速。
-
保持生成质量: 尽管大幅提升了推理速度,AsyncDiff对生成质量的影响却微乎其微。实验结果表明,即使在高加速比的情况下,生成图像的质量仍能保持在较高水平。
-
灵活的配置选项: AsyncDiff提供了多个可调整的参数,如模型分割数量、去噪步幅等,使用者可以根据具体需求和硬件条件进行灵活配置。
AsyncDiff的技术实现
AsyncDiff的实现主要包括以下几个关键步骤:
-
模型分割: 将噪声预测模型分割为多个组件,每个组件负责处理部分计算任务。
-
异步更新: 利用连续扩散步骤中隐藏状态的相似性,实现各组件的异步更新。
-
预热阶段: 在正式并行推理前,设置一个预热阶段,为后续的异步处理做好准备。
-
时间偏移: 引入时间偏移机制,在某些情况下可以进一步提升去噪能力。
AsyncDiff的应用示例
AsyncDiff支持多种主流的扩散模型,包括:
- Stable Diffusion 3 Medium
- Stable Diffusion 2.1 / 1.5
- Stable Diffusion XL 1.0
- Stable Diffusion XL Inpainting
- ControlNet
- Stable Video Diffusion
- AnimateDiff
对于不同的模型和任务,AsyncDiff提供了相应的加速脚本。例如,要加速Stable Diffusion XL的推理,可以使用以下命令:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.run --nproc_per_node=4 --run-path examples/run_sdxl.py
AsyncDiff的实验结果
研究团队在多个数据集上对AsyncDiff进行了全面的评估。实验结果表明,AsyncDiff在保持生成质量的同时,显著提升了推理速度。

上图展示了AsyncDiff在SDXL和SD 2.1上的定性结果。可以看出,即使在高加速比的情况下,AsyncDiff生成的图像质量仍与原始模型相当。
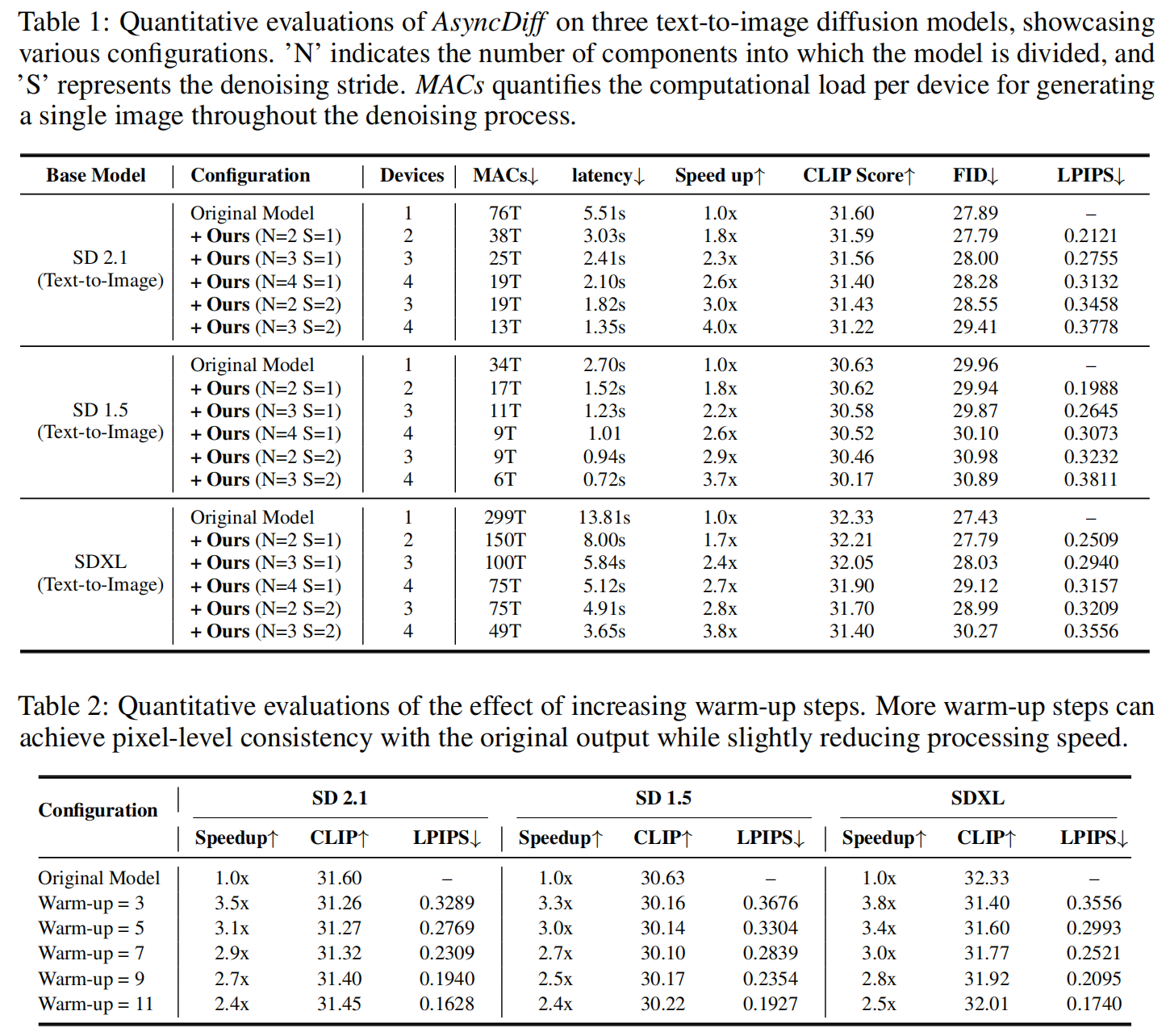
量化评估结果进一步证实了AsyncDiff的有效性。在不同的配置下,AsyncDiff都能在保持较高CLIP评分的同时,实现显著的推理加速。
AsyncDiff的潜在应用
AsyncDiff的提出为扩散模型的实际应用打开了新的可能性:
-
实时图像生成: 通过大幅降低推理延迟,AsyncDiff使得扩散模型在实时图像生成场景中的应用成为可能。
-
高吞吐量服务: 对于需要处理大量图像生成请求的在线服务,AsyncDiff可以显著提高系统的吞吐量。
-
资源受限环境: 在计算资源有限的环境中,AsyncDiff能够更好地利用现有硬件,提高模型的实用性。
-
视频生成加速: AsyncDiff在AnimateDiff和Stable Video Diffusion上的成功应用,为视频生成任务的加速提供了新思路。
AsyncDiff的局限性与未来展望
尽管AsyncDiff取得了显著的成果,但仍存在一些局限性和有待探索的方向:
-
硬件依赖: AsyncDiff的性能提升依赖于多GPU设备,这可能限制其在单GPU环境下的应用。
-
模型适配性: 虽然AsyncDiff支持多种扩散模型,但对于某些特殊结构的模型,可能需要进行额外的适配工作。
-
长序列生成: 对于视频生成等长序列任务,AsyncDiff的加速效果可能会随着序列长度的增加而降低,这是未来研究的一个重要方向。
-
与其他加速技术的结合: 探索AsyncDiff与其他模型加速技术(如知识蒸馏、量化等)的结合,可能会带来更显著的性能提升。
结论
AsyncDiff作为一种创新的扩散模型加速技术,通过巧妙的异步去噪策略实现了多设备并行推理,在保持生成质量的同时显著提高了推理速度。这一方法不仅为扩散模型的实际应用提供了新的可能性,也为深度学习模型的并行优化开辟了新的研究方向。随着AsyncDiff的进一步发展和完善,我们有理由期待它能够在更广泛的领域发挥重要作用,推动生成AI技术的实际应用与创新。
参考资料
[1] Chen, Z., Ma, X., Fang, G., Tan, Z., & Wang, X. (2024). AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising. arXiv preprint arXiv:2406.06911.
[2] AsyncDiff GitHub Repository: https://github.com/czg1225/AsyncDiff
[3] AsyncDiff Project Page: https://czg1225.github.io/asyncdiff_page/









