
 访问官网
访问官网 Github
Github 论文
论文

AsyncDiff: 通过异步去噪并行化扩散模型




AsyncDiff: 通过异步去噪并行化扩散模型
陈子庚,马鑫音,方功凡,谭振雄,王鑫超
学习与视觉实验室,新加坡国立大学
🥯[Arxiv]🎄[项目页面]
代码贡献者:陈子庚,谭振雄

使用4个设备,SDXL速度提升2.8倍。上:原始50步(13.81秒)。下:AsyncDiff 50步(4.98秒)

使用2个设备,AnimateDiff速度提升1.8倍。上:原始50步(43.5秒)。下:AsyncDiff 50步(24.5秒)
更新
- 🚀 2024年8月14日:现已支持Stable Diffusion XL修复绘制!加速SDXL修复绘制的推理示例可在run_sdxl_inpaint.py中找到。
- 🚀 2024年7月18日:现已支持Stable Diffusion 3 Medium!加速SD 3的推理示例可在run_sd3.py中找到。
- 🚀 2024年6月18日:现已支持ControlNet!加速controlnet+SDXL的推理示例可在run_sdxl_controlnet.py中找到。
- 🚀 2024年6月17日:现已支持Stable Diffusion x4 Upscaler!推理示例可在run_sd_upscaler.py中找到。
- 🚀 2024年6月12日:AsyncDiff代码已发布。
支持的扩散模型:
- ✅ Stable Diffusion 3 Medium
- ✅ Stable Diffusion 2.1
- ✅ Stable Diffusion 1.5
- ✅ Stable Diffusion x4 Upscaler
- ✅ Stable Diffusion XL 1.0
- ✅ Stable Diffusion XL修复绘制
- ✅ ControlNet
- ✅ Stable Video Diffusion
- ✅ AnimateDiff
简介
我们提出了AsyncDiff,这是一种通用且即插即用的扩散加速方案,可实现跨多个设备的模型并行。我们的方法将繁重的噪声预测模型划分为多个组件,并将每个组件分配给不同的设备。为了打破这些组件之间的依赖链,它通过利用连续扩散步骤中隐藏状态之间的高度相似性,将传统的顺序去噪转变为异步过程。因此,每个组件都可以在单独的设备上并行计算。这种策略显著减少了推理延迟,同时对生成质量的影响最小。
 上图展示了异步去噪过程的概览。为了清晰起见,去噪模型εθ被分为四个组件。在预热阶段之后,每个组件的输入都会提前准备好,打破了依赖链并促进了并行处理。
上图展示了异步去噪过程的概览。为了清晰起见,去噪模型εθ被分为四个组件。在预热阶段之后,每个组件的输入都会提前准备好,打破了依赖链并促进了并行处理。
🔧 快速开始
安装
-
前提条件
NVIDIA GPU + CUDA >= 12.0 和相应的 CuDNN
-
创建环境:
conda create -n asyncdiff python=3.10 conda activate asyncdiff pip install -r requirements.txt
使用示例
只需添加两行代码即可为扩散模型启用异步并行推理。
import torch
from diffusers import StableDiffusionPipeline
from asyncdiff.async_sd import AsyncDiff
pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1",
torch_dtype=torch.float16, use_safetensors=True, low_cpu_mem_usage=True)
async_diff = AsyncDiff(pipeline, model_n=2, stride=1, time_shift=False)
async_diff.reset_state(warm_up=1)
image = pipeline(<prompts>).images[0]
if dist.get_rank() == 0:
image.save(f"output.jpg")
这里我们以Stable Diffusion管道为例。你可以将pipeline替换为任何Stable Diffusion管道的变体,如SD 2.1、SD 1.5、SDXL或SVD。我们还在asyncdiff.async_animate中提供了AsyncDiff对AnimateDiff的实现。
model_n:去噪模型被分割的组件数量。选项:2、3或4。stride:每个并行计算批次的去噪步长。选项:1或2。warm_up:预热阶段的步数。更多的预热步骤可以实现与原始输出在像素级别的一致性,同时略微降低处理速度。time_shift:启用时间偏移。将time_shift设置为True可以增强扩散模型的去噪能力。但通常应保持为False。只有当加速模型产生的图像或视频噪声明显时才启用time_shift。
推理
我们在examples/中提供了详细的脚本,用于使用我们的AsyncDiff框架加速SD 2.1、SD 1.5、SDXL、SD 3、ControNet、SD_Upscaler、AnimateDiff和SVD的推理。
🚀 加速Stable Diffusion XL:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.run --nproc_per_node=4 --run-path examples/run_sdxl.py
🚀 加速Stable Diffusion 2.1或1.5:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.run --nproc_per_node=4 --run-path examples/run_sd.py
🚀 加速Stable Diffusion 3 Medium:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_sd3.py
🚀 加速Stable Diffusion x4 Upscaler:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_sd_upscaler.py
🚀 加速SDXL Inpainting:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_sdxl_inpaint.py
🚀 加速ControlNet+SDXL:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_sdxl_controlnet.py
🚀 加速Animate Diffusion:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_animatediff.py
🚀 加速Stable Video Diffusion:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 --run-path examples/run_svd.py
定性结果
SDXL和SD 2.1的定性结果。更多定性结果可以在我们的论文中找到。


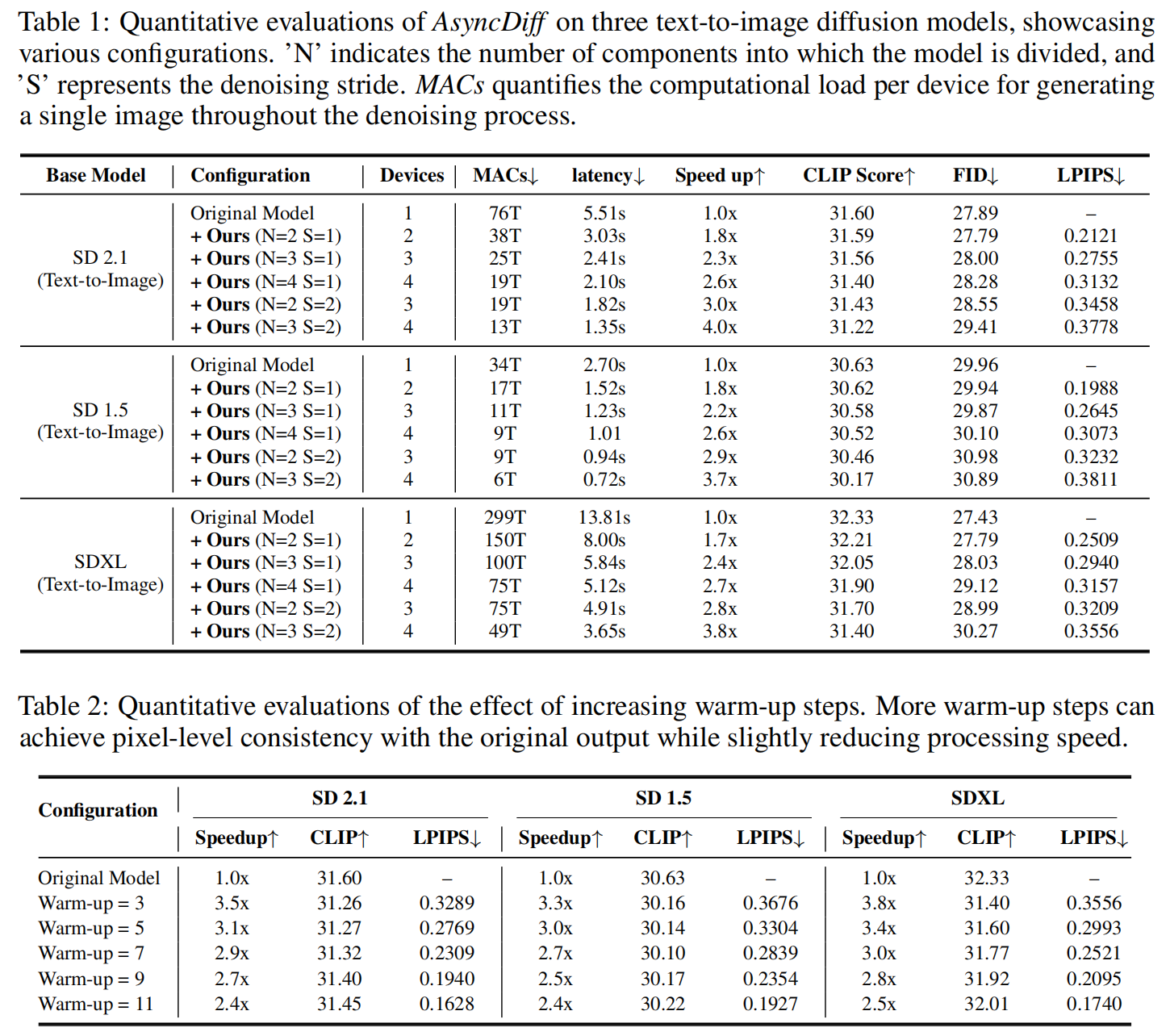
定量结果
AsyncDiff在三个文本到图像扩散模型上的定量评估,展示了各种配置。更多定量结果可以在我们的论文中找到。
引用
@article{chen2024asyncdiff,
title={AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising},
author={Chen, Zigeng and Ma, Xinyin and Fang, Gongfan and Tan, Zhenxiong and Wang, Xinchao},
journal={arXiv preprint arXiv:2406.06911},
year={2024}
}











