
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Awesome Video Diffusion 
A curated list of recent diffusion models for video generation, editing, restoration, understanding, nerf, etc.


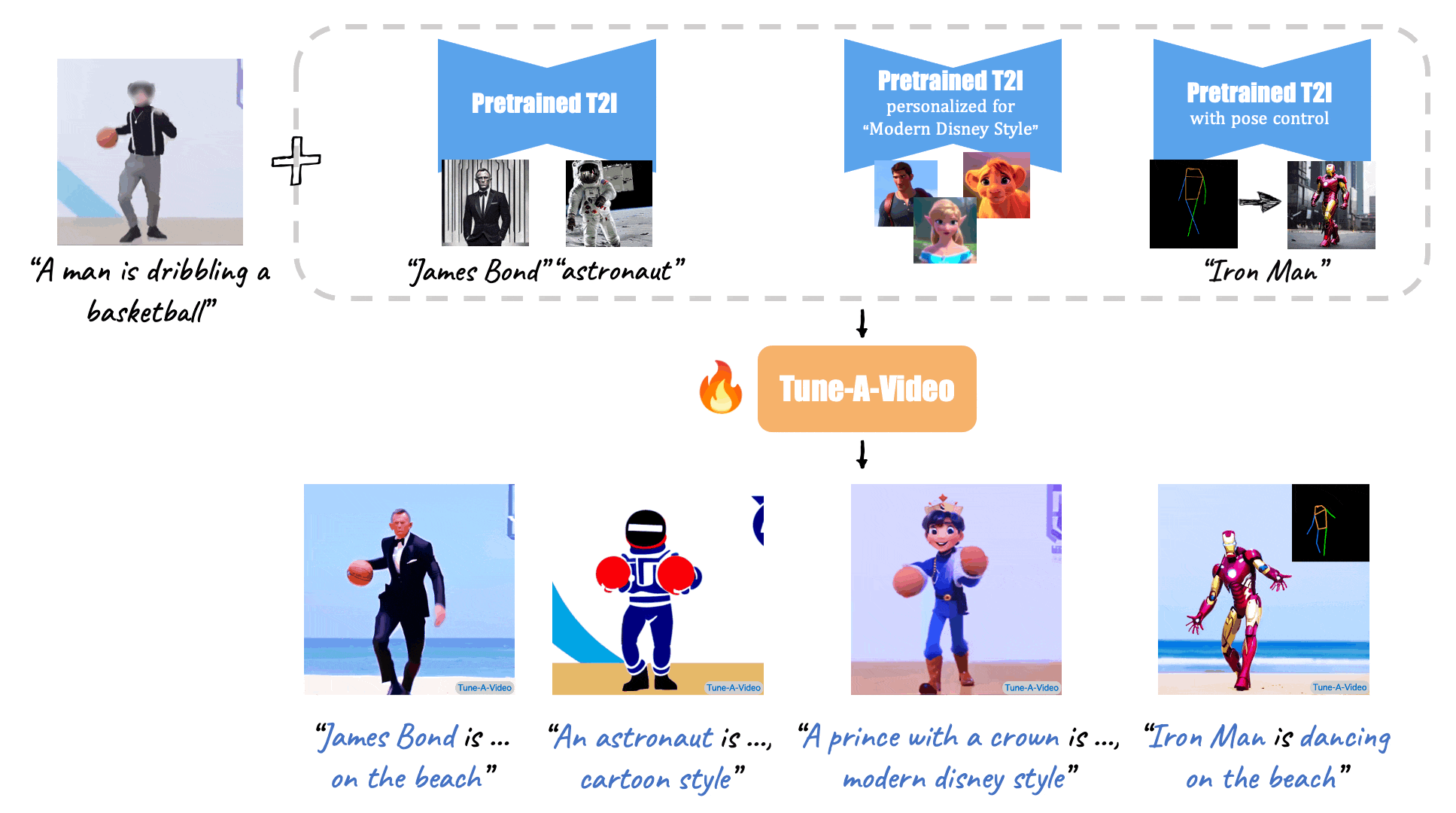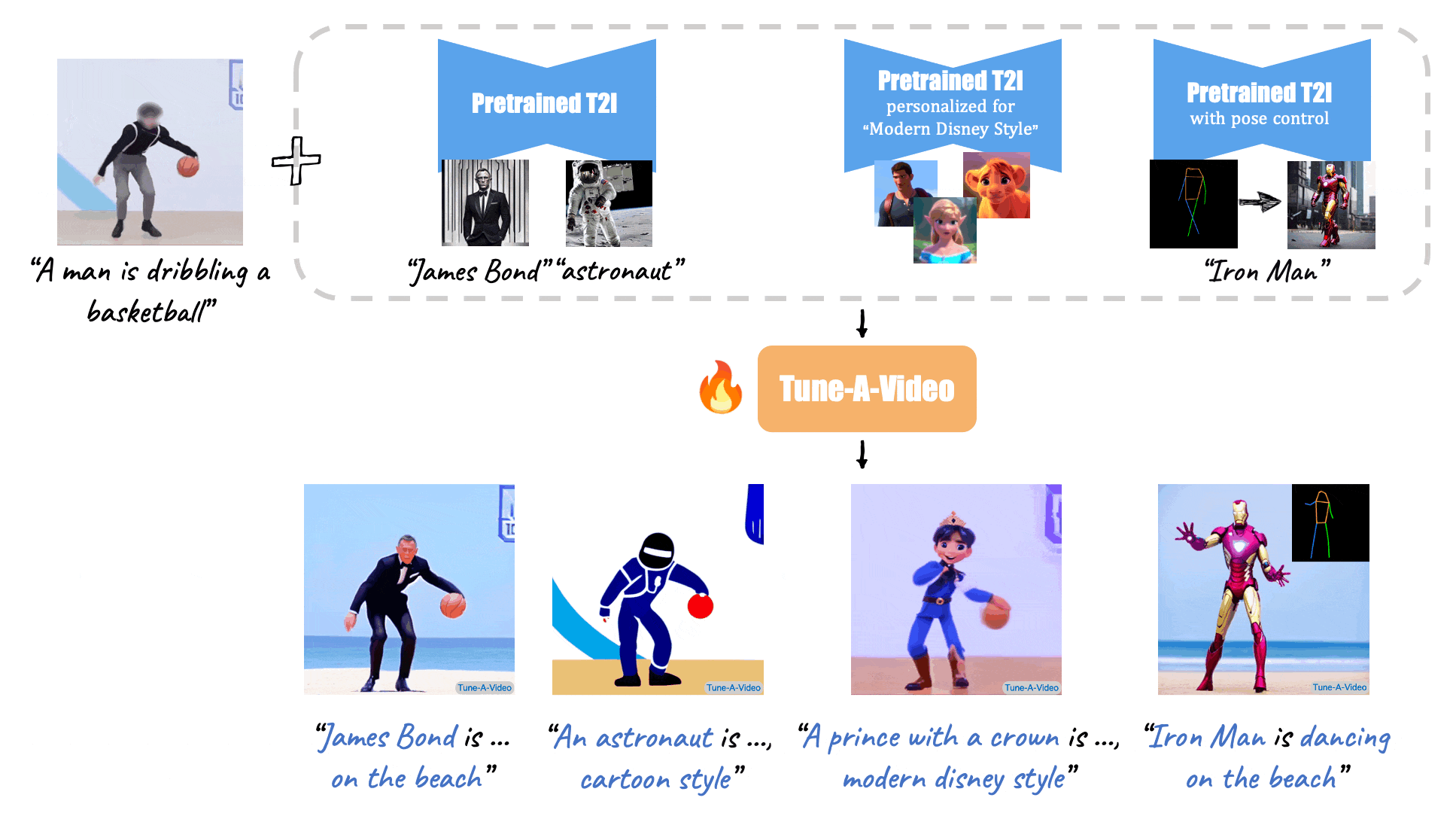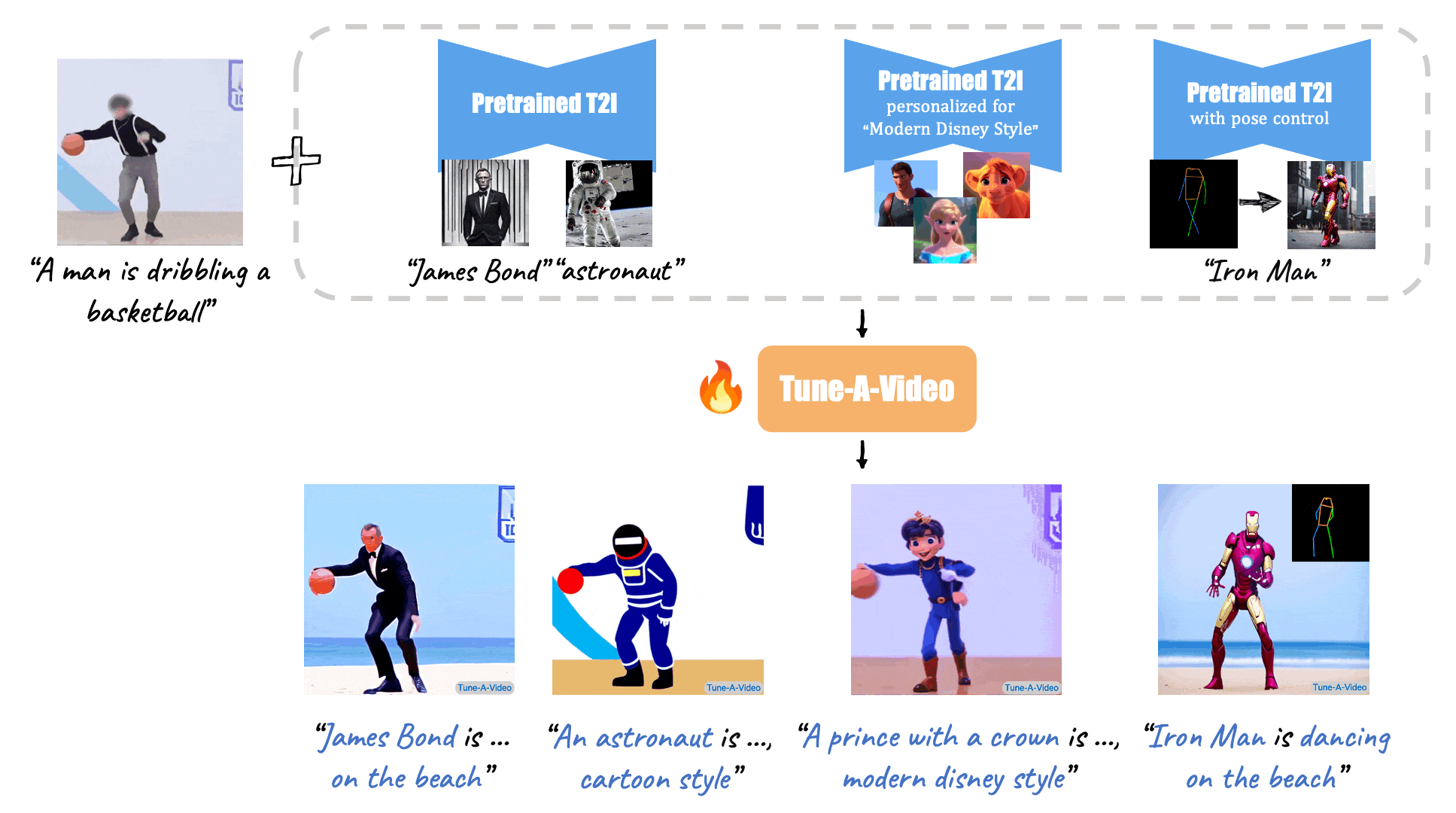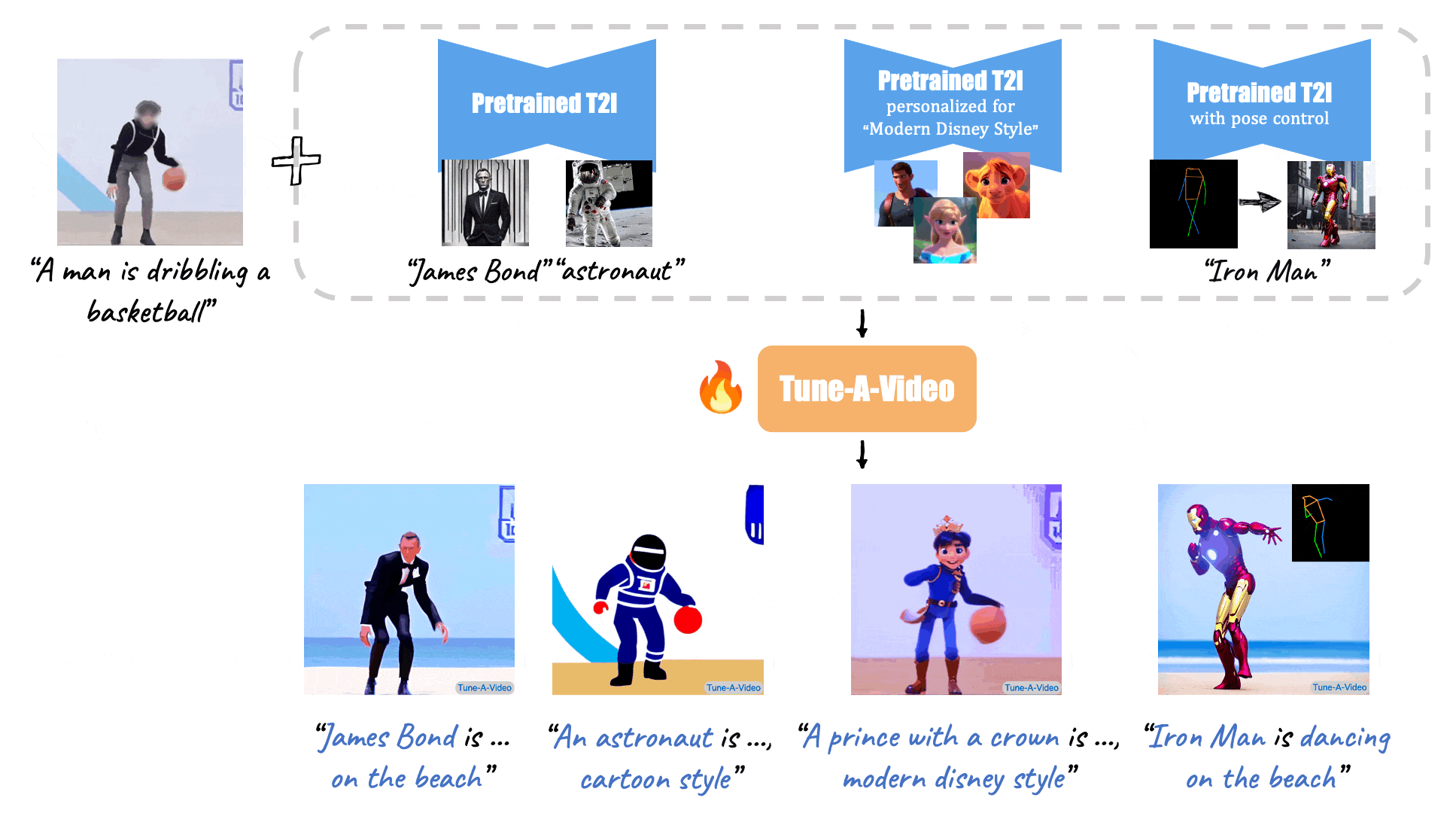


(Source: Make-A-Video, Tune-A-Video, and Fate/Zero.)
Table of Contents
- Open-source Toolboxes and Foundation Models
- Evaluation Benchmarks and Metrics
- Video Generation
- Controllable Video Generation
- Long Video / Film Generation
- Video Generation with Physical Prior / 3D
- Video Editing
- Long-form Video Generation and Completion
- Human or Subject Motion
- AI Safety for Video Generation
- Video Enhancement and Restoration
- Audio Synthesis for Video
- Human Feedback for Video Generation
- Policy Learning with Video Generation
- 3D / NeRF
- World Model
- Video Understanding
- Healthcare and Biology
Open-source Toolboxes and Foundation Models









Evaluation Benchmarks and Metrics
-
Frechet Video Motion Distance: A Metric for Evaluating Motion Consistency in Videos (Jun., 2024)


-
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation (Jun., 2024)

-
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation (Jun., 2024)

-
PEEKABOO: Interactive Video Generation via Masked-Diffusion (CVPR, 2024)

-
T2VScore: Towards A Better Metric for Text-to-Video Generation (Jan., 2024)

-
VBench: Comprehensive Benchmark Suite for Video Generative Models (Nov., 2023)

-
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation (Nov., 2023)

-
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models (Oct., 2023)

-
Evaluation of Text-to-Video Generation Models: A Dynamics Perspective (Jul., 2024)

-
VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models (May., 2024)

-
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (CVPR, 2024)

Video Generation
-
CogVideoX: Text-to-video generation (Aug., 2024)

-
FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention (Aug., 2024)
-
VEnhancer: Generative Space-Time Enhancement for Video Generation (Jul., 2024)

-
Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models (Jul., 2024)












