
AudioLM-PyTorch:开启音频生成的新纪元
在人工智能和深度学习领域,音频生成一直是一个充满挑战的任务。然而,随着AudioLM的出现,这一领域迎来了突破性的进展。AudioLM是由谷歌研究院开发的一种基于语言模型的音频生成方法,它在音频合成方面展现出了惊人的能力。而AudioLM-PyTorch则是这一创新模型在PyTorch框架下的实现,为研究人员和开发者提供了一个强大而灵活的工具。
AudioLM的核心理念
AudioLM的核心思想是将音频生成问题转化为一个语言建模任务。这种方法的独特之处在于,它不是直接在波形或频谱图上进行操作,而是将音频编码为一系列离散的标记。这些标记可以被视为"音频语言"中的单词或字符。通过在这些标记序列上训练大规模的Transformer模型,AudioLM学会了捕捉音频中的长期依赖关系和复杂结构。
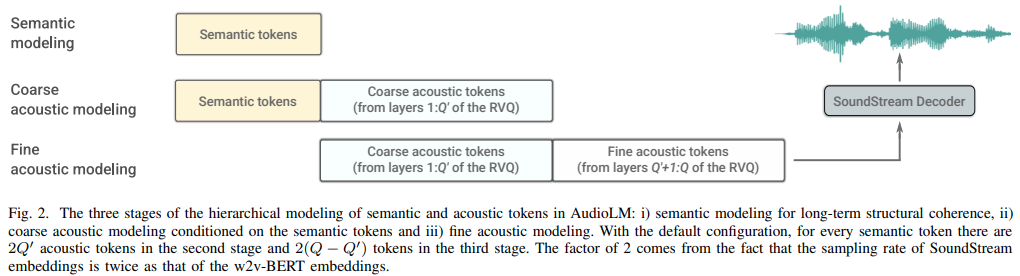
AudioLM-PyTorch的主要组件
AudioLM-PyTorch的实现包含了几个关键组件:
-
SoundStream编解码器: 这是一个神经音频编解码器,负责将原始音频波形压缩成离散的标记序列,以及将这些标记序列重建回连续的音频信号。
-
语义Transformer: 这个模型负责捕捉音频的高级语义结构,例如语音中的语言内容或音乐中的旋律和和声进展。
-
粗粒度Transformer: 它处理中等尺度的音频特征,如音色和节奏。
-
细粒度Transformer: 这个模型关注最细微的音频细节,确保生成的音频具有高保真度和自然度。
训练过程
训练AudioLM-PyTorch涉及几个阶段:
-
首先,需要训练SoundStream编解码器,使其能够有效地压缩和重建音频。
-
然后,使用大量的音频数据训练三个Transformer模型(语义、粗粒度和细粒度)。每个模型都专注于音频的不同方面。
-
最后,这些模型被整合到一起,形成一个端到端的音频生成系统。
文本条件生成
AudioLM-PyTorch的一个重要特性是支持文本条件音频生成。这意味着用户可以提供文本描述,模型将生成与之匹配的音频。例如,你可以要求模型生成"雨滴落在屋顶上的声音",它会尝试创造出符合这一描述的音频。
from audiolm_pytorch import AudioLM
audiolm = AudioLM(
wav2vec = wav2vec,
codec = soundstream,
semantic_transformer = semantic_transformer,
coarse_transformer = coarse_transformer,
fine_transformer = fine_transformer
)
generated_audio = audiolm(text = ['雨滴落在屋顶上的声音'])
应用前景
AudioLM-PyTorch的应用前景广阔,包括但不限于:
- 文本到语音合成(TTS)
- 音乐创作和编曲
- 环境音效生成
- 语音修复和增强
- 音频内容创作工具
技术挑战与未来发展
尽管AudioLM-PyTorch展现出了巨大的潜力,但在实际应用中仍面临一些挑战:
-
计算资源需求: 训练和运行大规模Transformer模型需要大量的计算资源。
-
生成速度: 由于模型的复杂性,实时音频生成仍然具有挑战性。
-
控制精度: 如何更精确地控制生成音频的各个方面(如音色、节奏等)仍需进一步研究。
-
多模态整合: 将AudioLM与其他模态(如视觉)结合,创造更丰富的多模态生成体验。
未来,研究人员可能会专注于解决这些挑战,同时探索新的应用领域。例如,将AudioLM与其他AI技术结合,可能会催生出全新的创意工具和交互式应用。
开源社区的贡献
AudioLM-PyTorch作为一个开源项目,得益于活跃的开发者社区。许多贡献者通过提供代码改进、bug修复和新功能实现,推动了项目的不断发展。这种开放协作的模式不仅加速了技术的迭代,也使得更多人能够参与到前沿AI研究中来。
结语
AudioLM-PyTorch代表了音频生成领域的一个重要里程碑。它不仅展示了语言模型在处理非文本数据方面的潜力,也为音频合成和处理开辟了新的可能性。随着技术的不断进步和社区的持续贡献,我们可以期待看到更多令人兴奋的应用和创新。无论你是研究人员、开发者还是创意工作者,AudioLM-PyTorch都为探索音频AI的无限可能性提供了一个强大的工具。🎵🚀
要了解更多信息或开始使用AudioLM-PyTorch,可以访问其GitHub仓库。同时,也欢迎感兴趣的开发者加入Discord社区,与其他enthusiasts交流讨论,共同推动这项激动人心的技术向前发展。










