BCEmbedding:为RAG优化的双语跨语言嵌入模型
BCEmbedding是网易有道最近开源的一个专为检索增强生成(RAG)优化的嵌入和重排模型。它在英文和中文的单语、双语和跨语言任务中都表现出色,为RAG应用提供了强大的语义表示能力。本文将详细介绍BCEmbedding的特点、使用方法和性能评估。
🌟 主要特点
BCEmbedding包含两个核心模型:
-
EmbeddingModel:用于生成语义向量,在语义搜索和问答中发挥重要作用。
-
RerankerModel:专门用于优化搜索结果和排序任务。
BCEmbedding的主要特点包括:
- 双语和跨语言能力:得益于有道的翻译引擎,在中英文及跨语言任务中表现优异。
- 为RAG优化:针对翻译、摘要和问答等RAG任务进行了专门优化,能准确理解查询意图。
- 高效精准检索:EmbeddingModel采用双编码器架构实现高效检索,RerankerModel使用交叉编码器进行深度语义分析,提高精准度。
- 广泛领域适应性:在多样化数据集上训练,可适应不同领域。
- 用户友好设计:无需为每个任务指定查询指令,可灵活用于多种场景。
- 有意义的重排分数:RerankerModel提供有意义的相关性分数,有助于提高结果质量。
- 生产环境验证:已在有道的多个产品中成功应用。
🚀 最新更新
- 2024-02-04:发布技术博客《为RAG而生-BCEmbedding技术报告》。
- 2024-01-16:提供LangChain和LlamaIndex集成支持。
- 2024-01-03:发布bce-embedding-base_v1和bce-reranker-base_v1模型。
- 2024-01-03:发布CrosslingualMultiDomainsDataset评估数据集,用于评估RAG性能。
- 2024-01-03:发布跨语言语义表示评估数据集。
💻 模型列表
BCEmbedding目前提供以下模型:
| 模型名称 | 模型类型 | 支持语言 | 参数量 | 模型链接 |
|---|---|---|---|---|
| bce-embedding-base_v1 | EmbeddingModel | 中文, 英文 | 279M | Huggingface |
| bce-reranker-base_v1 | RerankerModel | 中文, 英文, 日文, 韩文 | 279M | Huggingface |
📚 使用指南
安装
推荐从源码安装:
git clone git@github.com:netease-youdao/BCEmbedding.git
cd BCEmbedding
pip install -v -e .
快速上手
使用EmbeddingModel生成嵌入向量:
from BCEmbedding import EmbeddingModel
sentences = ['sentence_0', 'sentence_1']
model = EmbeddingModel(model_name_or_path="maidalun1020/bce-embedding-base_v1")
embeddings = model.encode(sentences)
使用RerankerModel计算相关性分数和重排:
from BCEmbedding import RerankerModel
query = 'input_query'
passages = ['passage_0', 'passage_1']
sentence_pairs = [[query, passage] for passage in passages]
model = RerankerModel(model_name_or_path="maidalun1020/bce-reranker-base_v1")
scores = model.compute_score(sentence_pairs)
rerank_results = model.rerank(query, passages)
BCEmbedding还提供了基于transformers和sentence-transformers的使用方法,以及与LangChain和LlamaIndex的集成示例,详见项目文档。
🔍 性能评估
BCEmbedding在语义表示和RAG任务上都进行了全面的评估。
语义表示评估(MTEB)
在MTEB基准测试中,BCEmbedding在114个数据集的119个评估结果中表现优异:
| 模型 | 维度 | Pooler | 是否需要指令 | Retrieval (47) | STS (19) | PairClassification (5) | Classification (21) | Reranking (12) | Clustering (15) | 平均 (119) |
|---|---|---|---|---|---|---|---|---|---|---|
| bce-embedding-base_v1 | 768 | cls | 不需要 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
bce-embedding-base_v1在检索和重排任务上表现尤为突出,整体性能优于其他开源嵌入模型。
在重排任务上,bce-reranker-base_v1的表现同样出色:
| 模型 | Reranking (12) | 平均 (12) |
|---|---|---|
| bce-reranker-base_v1 | 61.29 | 61.29 |
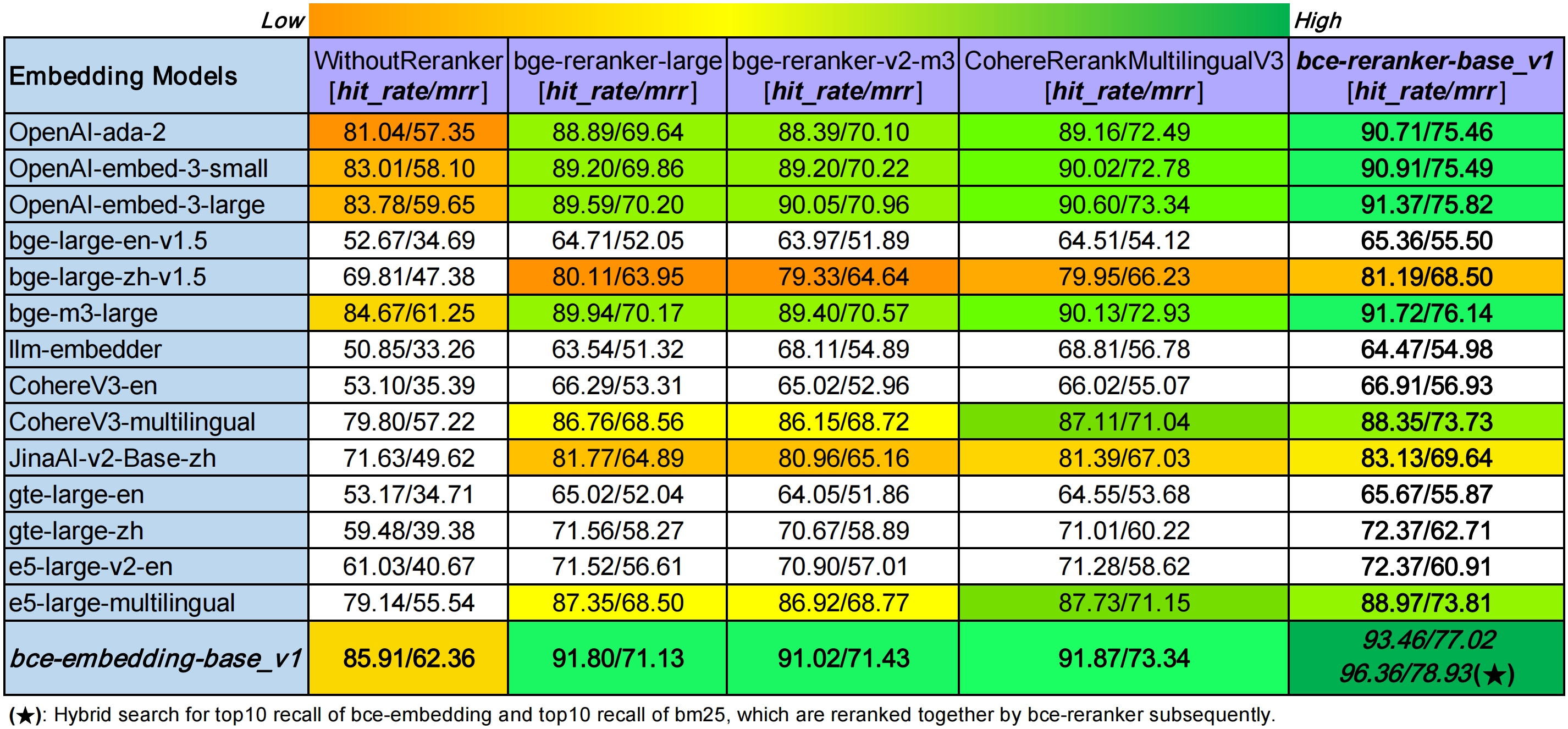
RAG评估(LlamaIndex)
BCEmbedding还在LlamaIndex框架下进行了RAG性能评估。评估指标包括:
- Hit Rate:系统在前k个检索结果中找到正确答案的比例。
- Mean Reciprocal Rank (MRR):首个相关文档排名的倒数的平均值。
评估结果显示:
- 在不使用重排模型的情况下,bce-embedding-base_v1优于所有其他嵌入模型。
- 在固定嵌入模型的情况下,bce-reranker-base_v1取得最佳性能。
- bce-embedding-base_v1和bce-reranker-base_v1的组合达到了最先进的水平。
为了评估BCEmbedding在广泛领域的适应性和跨语言能力,研究团队构建了CrosslingualMultiDomainsDataset数据集,涵盖计算机科学、物理学、生物学、经济学、数学和量化金融等多个领域。评估结果进一步证实了BCEmbedding在多语言、多领域RAG任务中的优越性能。
🔧 Youdao BCEmbedding API
网易有道还提供了BCEmbedding的API服务,支持向量检索、重排等功能,方便开发者快速集成到自己的应用中。详细的API文档和使用说明可在项目仓库中查看。
📝 总结
BCEmbedding作为一个专为RAG优化的双语跨语言嵌入模型,在语义表示和检索增强生成任务中都展现出了卓越的性能。它不仅在MTEB等标准基准测试中表现出色,还在实际的RAG应用场景中证明了其有效性。BCEmbedding的开源为NLP和RAG社区提供了一个强大的工具,相信它将在未来的研究和应用中发挥重要作用。
研究者和开发者可以通过GitHub仓库了解更多详情,使用BCEmbedding来增强他们的RAG应用。随着持续的更新和优化,我们期待看到BCEmbedding在更广泛的语言和领域中的应用,以及它对推动多语言NLP技术发展的贡献。
🔗 相关链接
通过深入了解和使用BCEmbedding,开发者和研究者可以在RAG相关任务中获得更好的性能,特别是在中英文及跨语言场景下。随着更多的更新和社区贡献,BCEmbedding有望成为RAG应用的重要基础设施之一。










