
BERTScore简介
BERTScore是由康奈尔大学的研究团队在2020年提出的一种新型自然语言处理评估指标。它的核心思想是利用BERT(Bidirectional Encoder Representations from Transformers)模型的预训练上下文嵌入来计算候选句子和参考句子之间的相似度。相比于传统的基于n-gram重叠的评估方法(如BLEU),BERTScore能够更好地捕捉语义信息,从而在多个任务上取得了更好的性能。
BERTScore的工作原理
BERTScore的计算过程可以概括为以下几个步骤:
-
使用BERT模型对候选句子和参考句子进行编码,得到每个词的上下文嵌入表示。
-
计算候选句子中每个词与参考句子中每个词的余弦相似度。
-
使用贪心匹配算法,为候选句子中的每个词找到参考句子中最相似的词。
-
基于匹配结果计算精确率、召回率和F1分数。
具体来说,BERTScore的召回率计算公式如下:
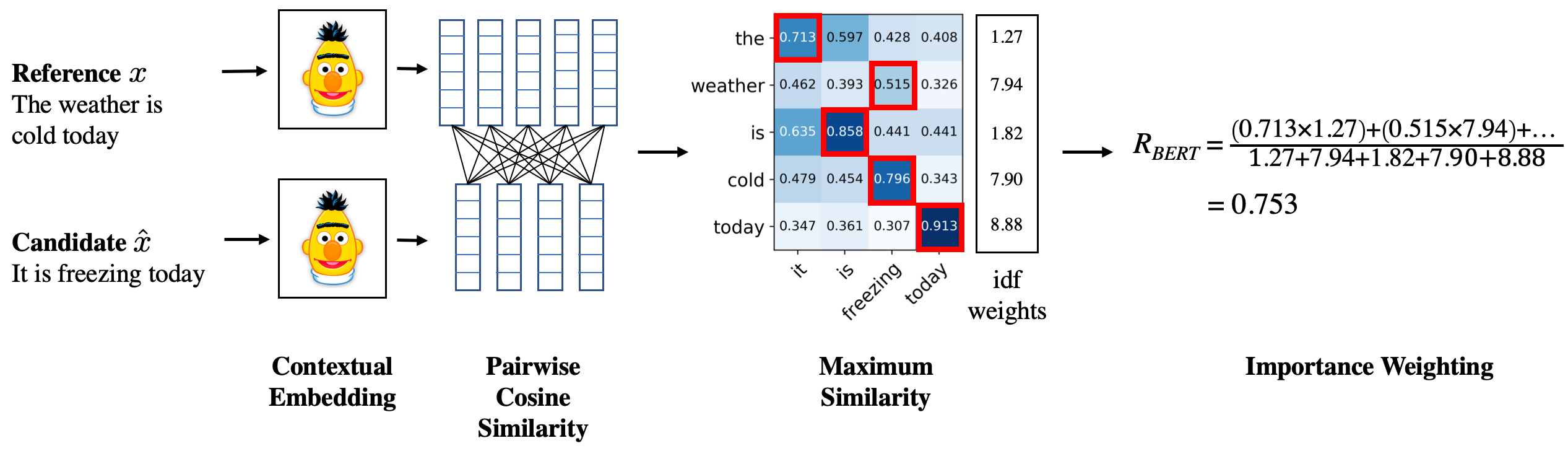
其中,x和y分别表示候选句子和参考句子中的词,BERT(x)表示词x的BERT嵌入表示。
BERTScore的优势
BERTScore相比传统评估指标具有以下几个优势:
-
更好的语义理解: 利用BERT的上下文嵌入,BERTScore能够捕捉词语的语义信息,而不仅仅是表面的字符匹配。
-
灵活的词语匹配: 通过计算词嵌入的相似度,BERTScore可以识别同义词或相似表达,而不局限于完全相同的词语。
-
考虑上下文信息: BERT模型能够根据上下文生成动态的词嵌入,使得BERTScore能够更好地处理多义词等复杂情况。
-
与人工评判的高相关性: 实验表明,BERTScore在句子级和系统级评估上都与人工判断有较高的相关性。
BERTScore的实现与使用
安装
BERTScore可以通过pip轻松安装:
pip install bert-score
基本使用
使用BERTScore评估文本生成质量的基本流程如下:
from bert_score import score
candidates = ["The cat sits on the mat.", "There is a cat on the mat."]
references = ["The cat is on the mat."]
P, R, F1 = score(candidates, references, lang="en", verbose=True)
print(f"Precision: {P.mean():.3f}")
print(f"Recall: {R.mean():.3f}")
print(f"F1: {F1.mean():.3f}")
高级功能
-
多参考评估: BERTScore支持为每个候选句子提供多个参考句子,取最高分作为最终得分。
-
自定义模型: 除了默认的BERT模型,BERTScore还支持使用其他预训练模型,如RoBERTa、XLNet等。
-
逆文档频率(IDF)加权: 可以使用参考句子集合计算IDF权重,以突出重要词语的贡献。
-
可视化: BERTScore提供了可视化工具,帮助分析词语匹配情况。
BERTScore在实践中的应用
BERTScore已被广泛应用于多个自然语言处理任务的评估中,包括但不限于:
-
机器翻译: 评估翻译质量,特别是在语义保持方面的表现。
-
文本摘要: 衡量自动生成摘要与人工摘要的相似度。
-
对话系统: 评估生成回复的质量和相关性。
-
图像描述: 判断自动生成的图像描述与人工描述的匹配程度。
-
文本纠错: 评估纠错系统的性能。
在这些应用中,BERTScore通常表现出比传统评估指标更好的性能,尤其是在捕捉语义相似性方面。
BERTScore的局限性与未来发展
尽管BERTScore在多个方面优于传统评估指标,但它仍然存在一些局限性:
-
计算成本高: 由于需要使用大型预训练模型,BERTScore的计算速度相对较慢,尤其是在处理大规模数据时。
-
依赖预训练模型: BERTScore的性能在很大程度上依赖于所使用的预训练模型的质量。
-
长文本处理: 对于超过BERT模型最大输入长度(通常为512个token)的文本,BERTScore可能需要进行截断处理。
-
跨语言泛化性: 虽然BERTScore支持多语言评估,但在某些低资源语言上的表现可能不够理想。
为了解决这些问题,研究者们正在探索以下方向:
-
模型压缩与加速: 通过知识蒸馏、量化等技术,降低BERTScore的计算复杂度。
-
结合任务特定信息: 将领域知识或任务特定的评估标准融入BERTScore中。
-
改进长文本处理: 探索更好的长文本编码方法,如使用Longformer等支持更长序列的模型。
-
增强跨语言能力: 利用多语言预训练模型和跨语言对齐技术,提高BERTScore在低资源语言上的表现。
结论
BERTScore作为一种基于BERT的自动文本生成评估指标,在多个自然语言处理任务中展现出了优秀的性能。它通过利用预训练语言模型的强大语义理解能力,克服了传统评估方法难以捕捉语义信息的局限性。尽管仍存在一些挑战,但随着研究的不断深入和技术的持续改进,BERTScore有望在未来发挥更大的作用,为自然语言处理领域的发展提供更加可靠和有效的评估工具。
对于研究者和开发者来说,了解并合理使用BERTScore可以帮助更准确地评估模型性能,从而推动自然语言处理技术的进步。同时,深入研究BERTScore的原理和改进方向,也可能为设计更先进的评估指标提供启发。在实际应用中,建议将BERTScore与其他评估指标结合使用,以获得更全面的评估结果。









