
BitNet简介
在人工智能和深度学习领域,大型语言模型(Large Language Models, LLMs)的规模不断扩大,计算资源需求也随之激增。为了解决这一挑战,研究人员提出了BitNet,这是一种革命性的1比特Transformer架构,旨在显著减少模型大小和计算复杂度,同时保持卓越的性能。
BitNet的核心思想是将传统32位浮点数权重量化为1比特,即仅使用+1和-1两个值来表示模型参数。这种极端量化方法不仅大幅降低了模型的存储需求,还简化了计算过程,使得BitNet在推理速度和能耗效率方面具有显著优势。
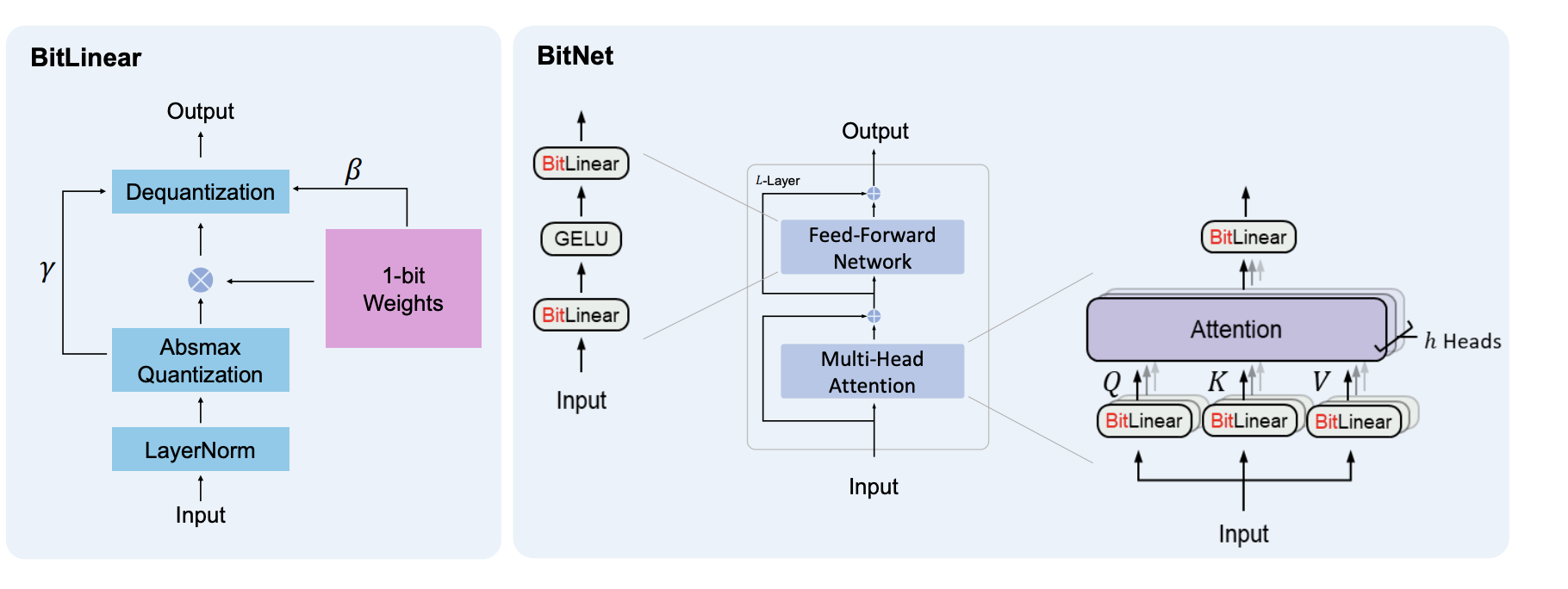
BitNet的技术创新
BitLinear层
BitNet的核心创新在于引入了BitLinear层,作为传统线性层(nn.Linear)的替代品。BitLinear层的工作流程如下:
- 输入张量
- 应用层归一化(LayerNorm)
- 二值化处理
- 绝对值最大量化
- 反量化
这一过程确保了信息在1比特表示中得到有效保留,同时保持了网络的表达能力。
BitNetTransformer
基于BitLinear层,研究人员构建了完整的BitNetTransformer模型。该模型包含了多头注意力机制(MHA)和BitFeedForward层,能够处理文本、图像,甚至可能扩展到视频和音频处理领域。BitNetTransformer还保留了残差连接和跳跃连接,以确保梯度的有效传播。
# BitNetTransformer示例代码
import torch
from bitnet import BitNetTransformer
# 创建随机整数张量作为输入
x = torch.randint(0, 20000, (1, 1024))
# 初始化BitNetTransformer模型
bitnet = BitNetTransformer(
num_tokens=20000, # 输入中唯一token的数量
dim=1024, # 输入和输出嵌入的维度
depth=6, # Transformer层的数量
heads=8, # 注意力头的数量
ff_mult=4, # 前馈网络隐藏层维度的乘数
)
# 将张量传递给Transformer模型
logits = bitnet(x)
# 打印输出的形状
print(logits)
BitAttention和BitFeedForward
BitNet还引入了BitAttention和BitFeedForward模块,它们分别是注意力机制和前馈网络的1比特实现。BitAttention采用了多组查询注意力(Multi-Grouped Query Attention)机制,以实现更快的解码速度和更长的上下文处理能力。BitFeedForward则采用了BitLinear-GELU-BitLinear的结构,可以根据需要添加dropout和层归一化等操作。
BitNet的应用与潜力
大规模语言模型压缩
BitNet最直接的应用是在大规模语言模型中。通过将32位浮点数权重压缩为1比特,BitNet可以显著减少模型的存储需求,使得在资源受限的设备上部署大型语言模型成为可能。这对于移动设备、嵌入式系统和边缘计算设备上的AI应用具有重要意义。
提高推理效率
由于BitNet使用1比特表示,它可以将复杂的浮点数乘法运算简化为简单的加法和减法操作。这种计算简化不仅加快了模型的推理速度,还大幅降低了能耗,使得BitNet在实时应用场景中具有显著优势。
扩展到其他领域
虽然BitNet最初是为自然语言处理任务设计的,但其1比特量化思想可以扩展到计算机视觉、语音识别等其他深度学习领域。例如,研究人员已经提出了基于BitNet的1比特视觉Transformer(OneBitViT),展示了该技术在图像处理任务中的潜力。
import torch
from bitnet import OneBitViT
# 创建OneBitViT模型实例
v = OneBitViT(
image_size=256,
patch_size=32,
num_classes=1000,
dim=1024,
depth=6,
heads=16,
mlp_dim=2048,
)
# 生成随机图像张量
img = torch.randn(1, 3, 256, 256)
# 将图像传递给OneBitViT模型获取预测结果
preds = v(img) # (1, 1000)
# 打印预测结果
print(preds)
BitNet的挑战与未来发展
尽管BitNet展现了巨大的潜力,但它仍然面临一些挑战:
-
训练稳定性: 1比特量化可能导致训练过程中的梯度消失或爆炸问题,需要开发更稳定的训练算法。
-
精度损失: 极端量化inevitably会带来一定的精度损失,如何在压缩率和模型性能之间取得最佳平衡是一个关键问题。
-
硬件适配: 充分发挥BitNet的优势需要专门的硬件支持,如何设计和优化适合1比特操作的硬件加速器是一个重要研究方向。
为了应对这些挑战并进一步推动BitNet的发展,研究人员正在探索以下方向:
-
改进量化算法: 开发更先进的量化方法,以在保持1比特表示的同时提高信息保留能力。
-
混合精度策略: 探索在模型的不同部分使用不同位宽的可能性,以在性能和效率之间取得更好的平衡。
-
神经架构搜索: 利用自动化方法寻找最适合1比特量化的网络结构。
-
领域特定优化: 针对不同应用场景(如自然语言处理、计算机视觉等)开发专门的BitNet变体。

结论
BitNet作为一种创新的1比特Transformer架构,为解决大型语言模型的计算和存储挑战提供了一个极具前景的方向。通过极端量化和巧妙的设计,BitNet在保持模型性能的同时,大幅降低了资源需求。尽管仍面临一些技术挑战,但BitNet的潜力是巨大的。随着研究的深入和技术的成熟,我们有理由相信,BitNet将在推动AI技术向更高效、更普及的方向发展中发挥重要作用。
未来,我们期待看到更多基于BitNet的应用和创新,以及它在各个领域带来的变革。研究者和开发者可以通过BitNet的GitHub仓库深入了解这项技术,并为其发展做出贡献。随着技术的不断进步,BitNet有望成为下一代AI系统的关键构建块,为人工智能的发展开辟新的可能性。











