
BM25S:基于稀疏矩阵的超快速文本检索库
在当今信息爆炸的时代,如何从海量文本数据中快速准确地检索出所需信息已成为一个至关重要的问题。BM25(Best Matching 25)作为一种经典的文本相关性排序算法,在信息检索领域得到了广泛应用。然而,随着数据规模的不断扩大,传统BM25算法的性能瓶颈日益凸显。为了解决这一问题,一个名为BM25S的创新实现应运而生,它通过巧妙利用稀疏矩阵技术,实现了前所未有的检索速度。
BM25S的诞生背景
BM25S由研究者Xing Han Lù开发,是一个基于Python和SciPy稀疏矩阵实现的高效BM25文本检索库。它的诞生源于对现有BM25实现性能的不满。虽然BM25算法本身已经相当成熟,但在处理大规模数据时,许多现有的实现方案都面临着速度慢、内存消耗大等问题。BM25S的目标就是要在保持算法准确性的同时,大幅提升检索速度和内存效率。
BM25S的核心特性
BM25S具有以下几个突出的特点:
-
超高速度: 通过预先计算并存储文档得分,BM25S在查询时可以实现极快的响应速度。与其他流行的Python实现相比,BM25S可以实现高达500倍的速度提升。
-
低内存占用: BM25S采用了内存映射(memory-mapping)技术,允许将索引存储在磁盘上并按需加载。这种方式可以显著降低内存使用,特别适合处理大规模数据集。
-
纯Python实现: BM25S完全用Python实现,仅依赖NumPy和SciPy这两个常用科学计算库。这使得它易于安装和使用,无需复杂的环境配置。
-
灵活性强: BM25S支持多种BM25变体算法,包括原始BM25、BM25L、BM25+等,用户可以根据需求灵活选择。
-
与Hugging Face集成: BM25S可以与Hugging Face的模型库无缝集成,方便用户分享和使用预训练的BM25索引。
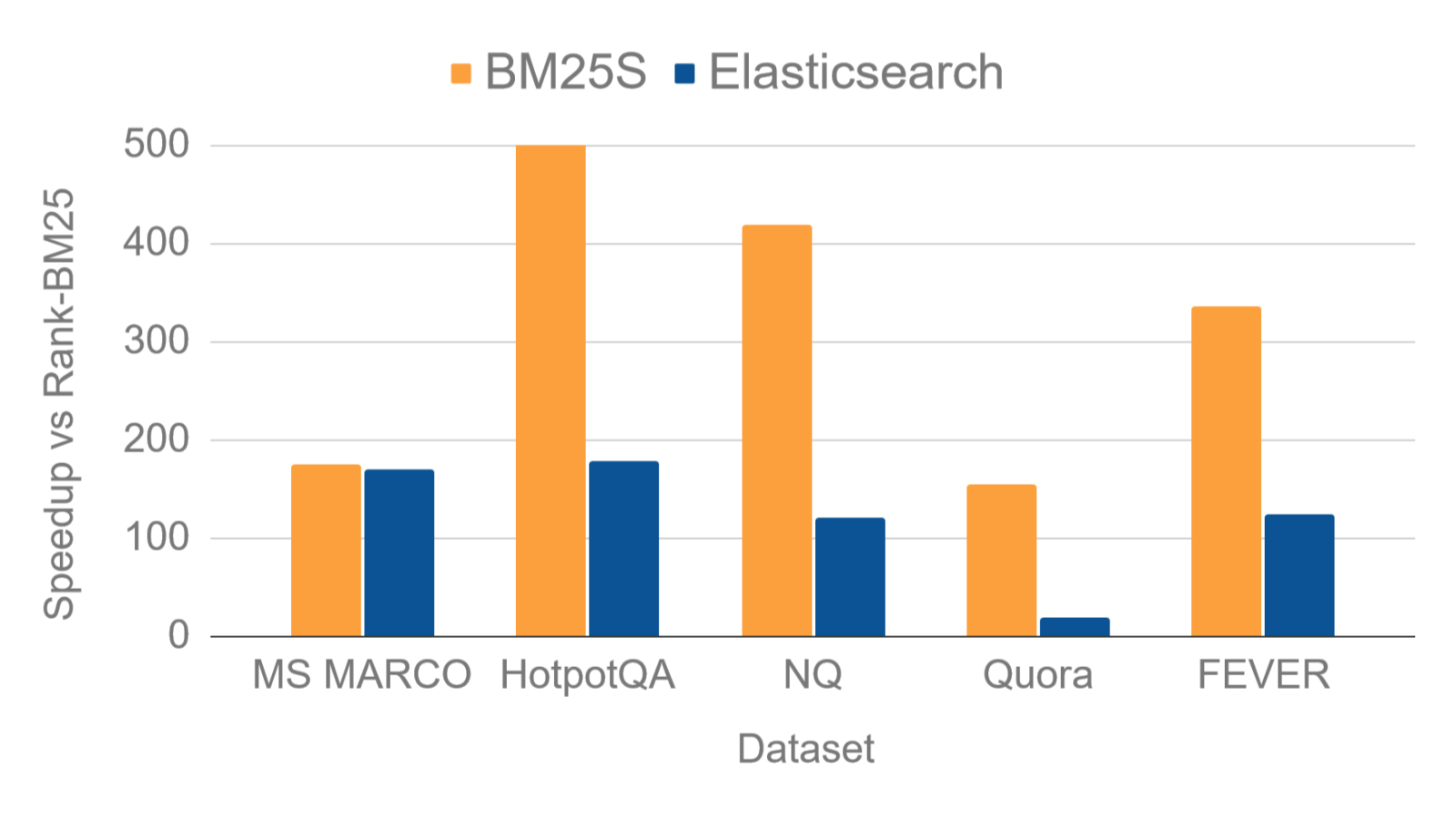
图1: BM25S与其他实现的性能对比
BM25S的工作原理
BM25S的核心创新在于其"急切稀疏评分"(eager sparse scoring)策略。传统的BM25实现通常在查询时才计算文档得分,而BM25S则在索引构建阶段就预先计算好所有可能的得分,并将结果存储在稀疏矩阵中。这种方法虽然会增加索引的大小,但在查询时可以实现极快的响应速度。
具体来说,BM25S的工作流程如下:
-
文档预处理: 对输入的文档集合进行分词、去停用词等预处理操作。
-
索引构建: 计算每个词在每个文档中的BM25得分,并将结果存储在稀疏矩阵中。
-
查询处理: 当收到查询时,BM25S直接从预计算的稀疏矩阵中提取相关得分,无需重新计算。
-
结果排序: 根据提取的得分对文档进行排序,返回最相关的结果。
这种方法的优势在于将大部分计算工作转移到了离线的索引构建阶段,从而大大提高了在线查询的速度。
BM25S的使用方法
使用BM25S非常简单,以下是一个基本的使用示例:
import bm25s
# 创建文档集合
corpus = [
"a cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
"a fish is a creature that lives in water and swims",
]
# 对文档进行分词
corpus_tokens = bm25s.tokenize(corpus)
# 创建BM25模型并索引文档
retriever = bm25s.BM25()
retriever.index(corpus_tokens)
# 进行查询
query = "does the fish purr like a cat?"
query_tokens = bm25s.tokenize(query)
# 获取top-k个结果
results, scores = retriever.retrieve(query_tokens, corpus=corpus, k=2)
# 打印结果
for i in range(results.shape[1]):
doc, score = results[0, i], scores[0, i]
print(f"Rank {i+1} (score: {score:.2f}): {doc}")
这个简单的例子展示了BM25S的基本用法,包括文档索引、查询处理和结果获取。对于更复杂的应用场景,BM25S还提供了许多高级功能,如自定义分词器、不同的BM25变体选择、内存映射等。
BM25S的性能评估
为了评估BM25S的性能,研究者进行了一系列基准测试,将其与其他流行的BM25实现进行比较。测试使用了来自BEIR(Benchmarking IR)项目的多个数据集,在单线程环境下测量每秒查询次数(QPS)。
图2: BM25S在不同数据集上的性能对比
从测试结果可以看出,BM25S在绝大多数数据集上都显著优于其他实现。特别是在处理大规模数据集时,BM25S的优势更为明显。例如,在msmarco数据集上,BM25S的QPS达到12.20,而最接近的ElasticSearch也只有11.88,传统的rank-bm25则只有0.07。
BM25S的应用场景
BM25S的高性能和低资源消耗使其适用于多种应用场景:
-
大规模文本检索: 对于包含数百万甚至数十亿文档的大型语料库,BM25S可以提供快速而准确的检索服务。
-
实时搜索系统: 由于其极低的查询延迟,BM25S非常适合构建需要快速响应的实时搜索系统。
-
资源受限环境: 在内存或计算资源有限的环境中,BM25S的低资源消耗特性显得尤为重要。
-
学术研究: 对于需要进行大规模文本检索实验的研究人员来说,BM25S提供了一个高效且易用的工具。
-
作为神经检索的基线: 在评估更复杂的神经网络检索模型时,BM25S可以作为一个强大的基线系统。
BM25S的未来展望
尽管BM25S已经展现出了卓越的性能,但其开发团队并未就此止步。他们正在探索多个方向来进一步提升BM25S的能力:
-
多语言支持: 增强BM25S对非英语文本的处理能力,使其能够更好地支持多语言检索任务。
-
分布式计算: 研究如何将BM25S扩展到分布式环境,以处理更大规模的数据集。
-
与深度学习的结合: 探索将BM25S与最新的神经网络模型结合,创造更强大的混合检索系统。
-
领域特定优化: 针对特定领域(如医疗、法律等)的文本特点,开发定制化的BM25变体。
-
实时索引更新: 研究如何在保持高性能的同时,支持索引的实时更新。
结语
BM25S的出现为文本检索领域带来了一股新的活力。它不仅大幅提升了检索速度,还降低了系统资源需求,使得在各种环境下构建高性能检索系统成为可能。随着数据规模的不断增长和实时性要求的提高,BM25S无疑将在未来的信息检索应用中扮演越来越重要的角色。
对于研究人员和工程师来说,BM25S提供了一个强大而灵活的工具,可以帮助他们更好地应对文本检索的挑战。无论是构建搜索引擎、问答系统,还是进行文本挖掘研究,BM25S都是一个值得考虑的选择。
随着BM25S的不断发展和完善,我们有理由相信,它将为推动信息检索技术的进步做出重要贡献,让我们拭目以待它在未来带来的更多惊喜。












