
BM25S入门指南 - 快速高效的Python词法搜索库
BM25S是一个令人兴奋的新词法搜索库,它在Python中实现了BM25算法,并通过巧妙的设计实现了卓越的性能。本文将为您介绍BM25S的主要特性、使用方法以及性能优势,帮助您快速掌握这个强大的搜索工具。
BM25S简介
BM25S是一个纯Python实现的BM25搜索库,它利用Scipy稀疏矩阵来存储预先计算的文档token分数。这种设计允许在查询时进行极快的评分,性能比常见库提高了数个数量级。
BM25S的主要特点包括:
- 高速: 利用Scipy稀疏矩阵存储预计算分数,查询时速度极快
- 简单: 仅依赖Numpy和Scipy,无需Java或PyTorch等外部依赖
- 灵活: 支持多种BM25变体,可自定义分词和评分过程
- 内存效率: 支持内存映射,可处理大规模语料库
安装和快速开始
通过pip即可轻松安装BM25S:
pip install bm25s[full]
下面是一个简单的使用示例:
import bm25s
corpus = [
"a cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
"a fish is a creature that lives in water and swims",
]
# 创建BM25模型并索引语料库
retriever = bm25s.BM25()
retriever.index(bm25s.tokenize(corpus))
# 查询语料库
query = "does the fish purr like a cat?"
results, scores = retriever.retrieve(bm25s.tokenize(query), k=2)
# 打印结果
for i in range(results.shape[1]):
doc, score = results[0, i], scores[0, i]
print(f"Rank {i+1} (score: {score:.2f}): {doc}")
高级特性
-
内存效率检索: BM25S支持内存映射,可以在不将整个索引加载到内存的情况下进行检索,非常适合处理大规模语料库。
-
自定义分词: 除了使用内置的
bm25s.tokenize函数,您还可以使用Tokenizer类来自定义分词过程。 -
多种BM25变体: BM25S支持多种BM25算法变体,如Robertson、ATIRE、BM25L、BM25+和Lucene等。
-
与Hugging Face集成: BM25S可以与Hugging Face Hub无缝集成,便于分享和使用社区模型。
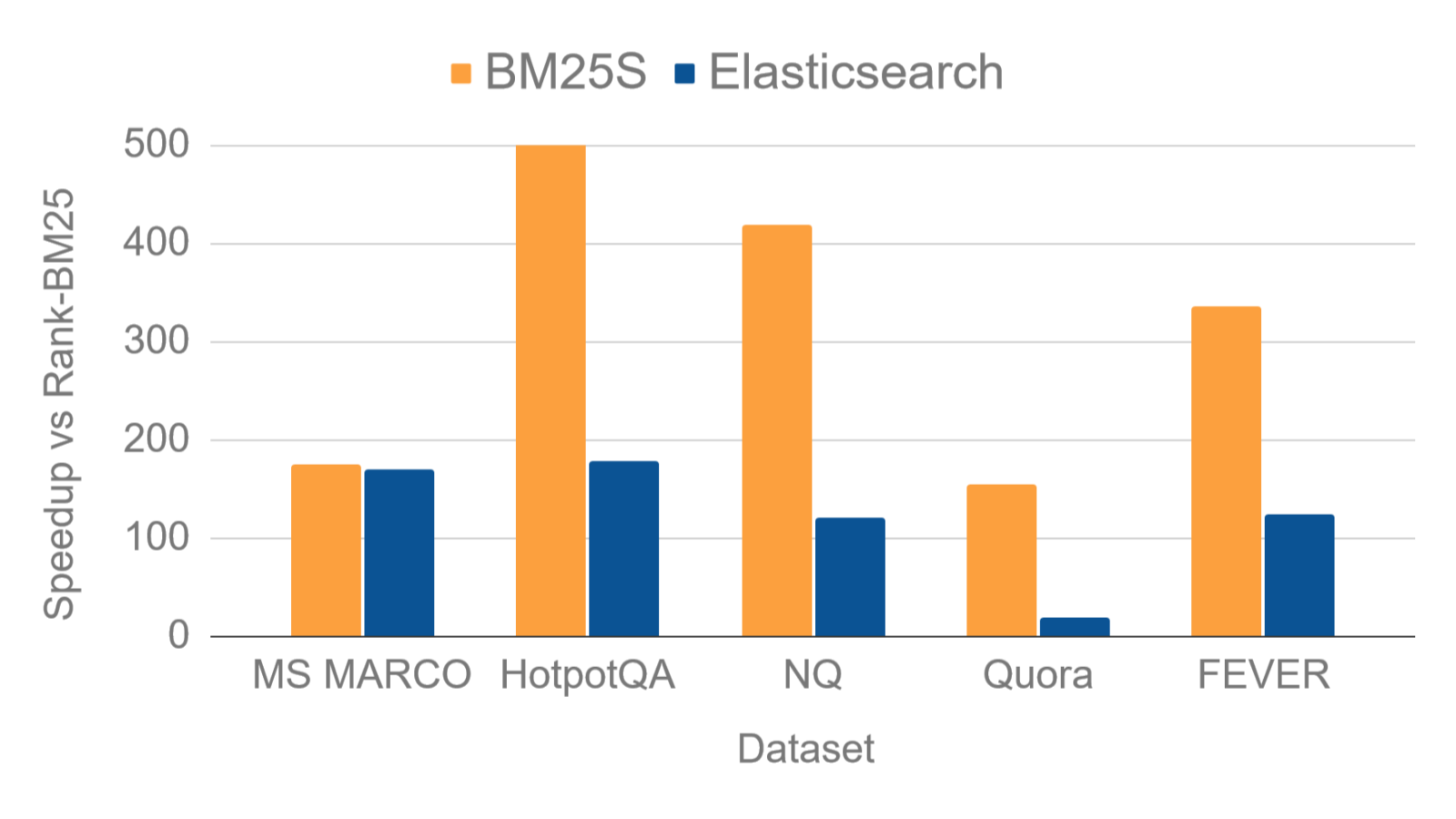
性能对比
在多个数据集上的基准测试中,BM25S展现出了显著的性能优势:
| 数据集 | BM25S | Elastic | BM25-PT | Rank-BM25 |
|---|---|---|---|---|
| msmarco | 12.20 | 11.88 | OOM | 0.07 |
| nq | 41.85 | 12.16 | OOM | 0.10 |
| quora | 183.53 | 21.80 | 6.49 | 1.18 |
(数据单位: 每秒查询次数,OOM表示内存不足)
结语
BM25S为Python开发者提供了一个高性能、易用的词法搜索解决方案。无论您是在构建搜索引擎、进行信息检索研究,还是需要在大规模文本数据中快速查找相关内容,BM25S都是一个值得考虑的强大工具。
欢迎访问BM25S GitHub仓库了解更多详情,或查看技术报告深入了解其实现原理。
让我们一起探索BM25S带来的高效词法搜索新体验吧! 🚀












