CAIL2019-SCM数据集简介
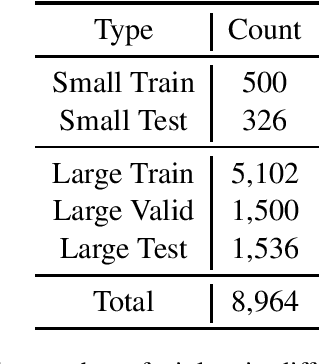
CAIL2019-SCM (Chinese AI and Law 2019 Similar Case Matching)是由中国最高人民法院发布的一个大规模中文法律相似案例匹配数据集。该数据集包含8,964个案例三元组,每个三元组由两个相似度较高的案例和一个相似度较低的案例组成。参赛者需要判断哪两个案例更相似。
CAIL2019-SCM数据集的发布旨在推动法律人工智能领域的研究,特别是在案例检索和相似度匹配方面。相似案例匹配对于法律实践具有重要意义,可以帮助法官和律师快速找到与当前案件相关的先例,从而提高司法效率和公正性。
数据集特点
CAIL2019-SCM数据集具有以下特点:
-
规模大:包含近9000个案例三元组,覆盖面广。
-
来源权威:案例均来自最高人民法院公开发布的裁判文书。
-
标注质量高:由专业法律人士进行人工标注。
-
难度适中:相似案例的判断需要综合考虑多方面因素,具有一定挑战性。
-
应用价值高:对推动法律AI技术发展具有重要意义。
研究进展
自CAIL2019-SCM数据集发布以来,学术界和产业界围绕该数据集开展了大量研究工作。主要研究方向包括:
- 基于深度学习的相似案例匹配模型
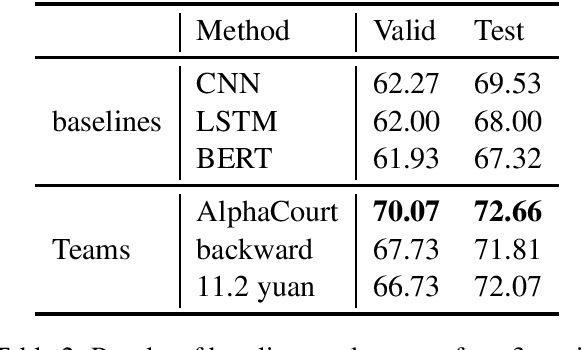
研究人员尝试了多种深度学习模型,如BERT、RoBERTa等,并针对法律文本特点进行了优化。例如,Hong等人提出了Legal Feature Enhanced Semantic Matching Network,在BERT的基础上引入法律特征向量,取得了不错的效果。
- 多任务学习
一些研究将相似案例匹配与其他法律NLP任务(如要素识别、罪名预测等)结合,采用多任务学习的方式提升模型性能。Liu等人提出的模型就同时考虑了案例相似度匹配和判决预测两个任务。
- 可解释性研究
为了提高模型的可信度,研究人员也在探索如何提升相似案例匹配模型的可解释性。Shi等人提出的MESCM框架就采用了多阶段的可解释匹配方法。
- 数据增强
由于标注高质量的法律数据集成本较高,一些研究尝试通过数据增强的方式扩充训练数据。常用的方法包括回译、同义词替换等。
- 预训练语言模型
针对法律领域的特点,一些研究者尝试在法律语料上进行预训练,以获得更适合法律任务的语言模型。例如,清华大学发布的基于大规模法律文书预训练的BERT模型。
应用前景
CAIL2019-SCM数据集的发布为法律人工智能领域带来了新的机遇。基于该数据集开发的技术可以应用于多个方面:
- 智能案例检索系统
通过相似案例匹配技术,可以构建更加智能的案例检索系统,帮助法律工作者快速找到相关先例。
- 辅助裁判系统
相似案例匹配可以为法官提供参考案例,辅助司法决策,提高判决的一致性和公正性。
- 法律咨询机器人
结合相似案例匹配和问答技术,可以开发更加智能的法律咨询机器人,为公众提供初步的法律建议。
- 法律文书智能生成
通过分析相似案例,可以辅助法律文书的智能生成,提高文书撰写效率。
- 法学教育与研究
该数据集为法学教育和研究提供了宝贵的资源,可用于案例教学、判例分析等多个方面。
未来展望
尽管CAIL2019-SCM数据集推动了相关研究的发展,但在法律人工智能领域仍有许多挑战待解决:
-
如何更好地利用法律领域知识,提升模型性能。
-
如何提高模型的鲁棒性,应对各种复杂的法律案例。
-
如何进一步提升模型的可解释性,增强其在实际应用中的可信度。
-
如何处理法律文本中的歧义和模糊性。
-
如何在保护隐私的前提下,扩大数据规模,提升模型效果。
随着大语言模型技术的发展,未来可能会出现更加强大的法律人工智能系统。但与此同时,我们也要警惕AI在法律领域应用可能带来的伦理风险,确保技术发展与法治精神相契合。
CAIL2019-SCM数据集的发布为法律人工智能的发展提供了重要支撑。期待未来会有更多创新性的研究成果,推动法律科技的进步,为建设智慧法治贡献力量。
结语
CAIL2019-SCM数据集的发布是中国法律人工智能领域的一个重要里程碑。它不仅推动了学术研究的进展,也为法律科技的产业化应用奠定了基础。未来,随着技术的不断进步,我们有理由相信,人工智能将在法律领域发挥越来越重要的作用,为推动法治中国建设做出贡献。











