
ChatGPT对比检测项目简介
在人工智能快速发展的今天,大型语言模型如ChatGPT的出现引发了广泛关注。为了深入研究ChatGPT与人类专家之间的差距,以及开发有效的AI生成内容检测工具,一个名为"ChatGPT对比检测"的开源项目应运而生。该项目由来自6所大学和公司的研究人员共同发起,旨在为学术界和产业界提供宝贵的研究资源。
项目背景与目标
2022年12月9日,也就是ChatGPT推出10天后,项目团队启动了这项研究。他们的主要目标包括:
- 创建开源模型,用于高效检测ChatGPT生成的内容
- 收集有价值的人类-ChatGPT对比问答语料库,以促进相关研究
这个项目不仅关注技术层面,更希望为开放学术研究做出贡献。团队成员虽然自称是"ChatGPT阴影下的渺小研究人员",但他们希望通过这个项目为社区做一些有意义的事情。
HC3语料库:首个人类vs ChatGPT对比语料
项目的一大亮点是提出了首个"人类vs ChatGPT"对比语料库,命名为HC3(Human ChatGPT Comparison Corpus)。这个语料库包含了多个领域的问答对,每个问题都有来自人类专家和ChatGPT的回答。
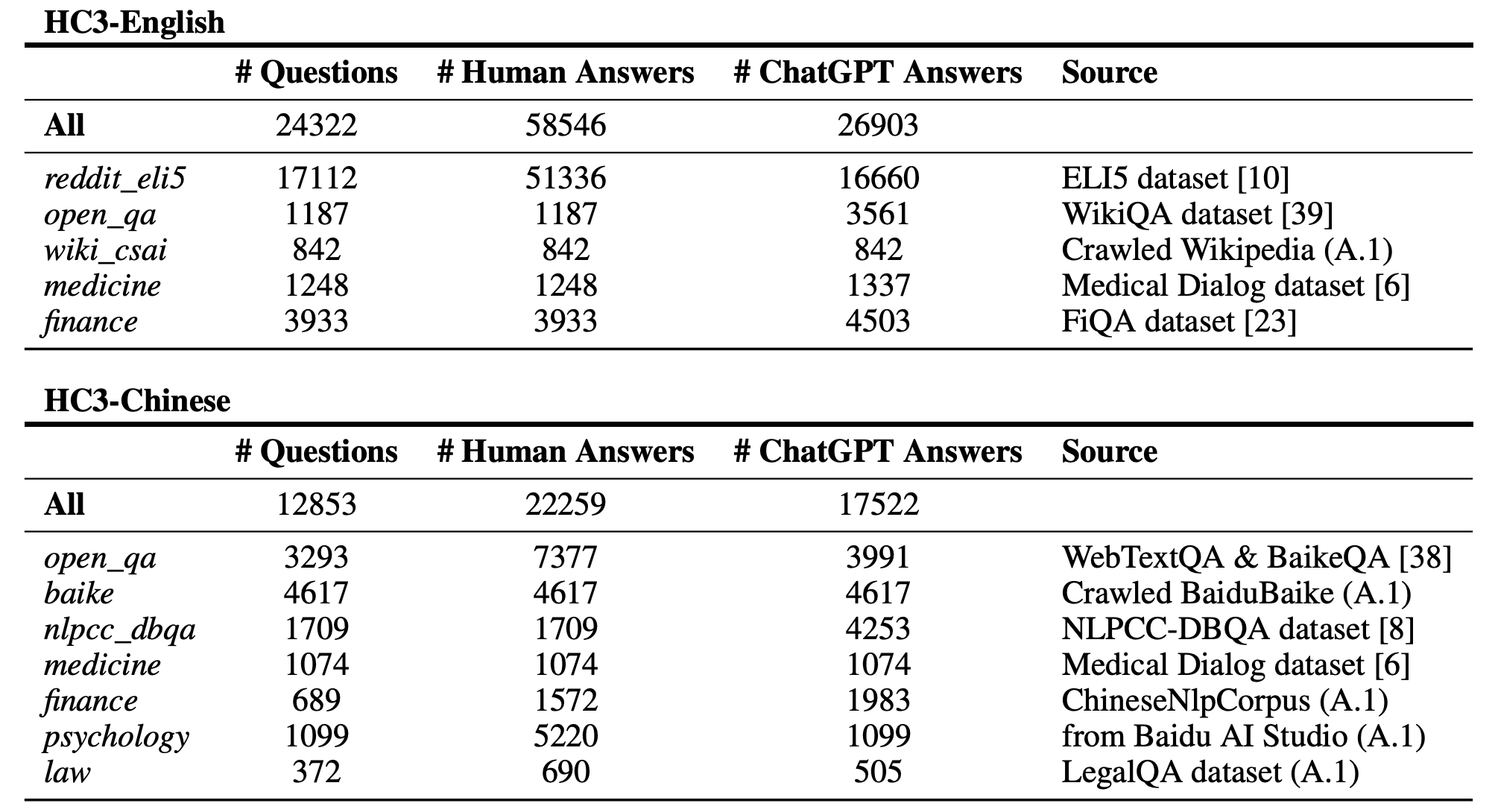
HC3语料库的特点包括:
- 支持中英双语
- 涵盖多个领域,如医疗、金融、心理学、法律等
- 数据来源多样,包括Reddit、Wikipedia、专业问答网站等
- 遵循严格的版权规定,确保数据使用合法性
研究者可以通过Hugging Face Datasets或ModelScope平台获取HC3数据集,这为后续的对比研究和模型训练提供了便利。
ChatGPT检测器:识别AI生成内容的利器
除了语料库,项目团队还开发了三种类型的ChatGPT检测器,均支持中英双语:
- 问答版:判断某个问题的回答是否由ChatGPT生成
- 独立文本版:判断单条文本是否由ChatGPT生成
- 语言学版:基于语言学特征判断文本是否由ChatGPT生成
这些检测器采用了不同的技术路线:
- 问答版和独立文本版使用基于预训练语言模型(PLM)的分类器
- 语言学版则利用语言学特征来进行判断
检测器的模型权重已在Hugging Face Models平台开源,方便研究者进行复现和改进。英文模型基于roberta-base,中文模型则基于hfl/chinese-roberta-wwm-ext。
检测器的应用场景
这些检测器的开发和开源,为学术界和产业界带来了多方面的价值:
- 学术研究:为研究人员提供了研究AI生成内容特征的工具
- 教育领域:帮助教育工作者识别学生作业中可能存在的AI生成内容
- 内容审核:为网站和平台提供了识别AI生成内容的技术支持
- 版权保护:协助创作者和出版商识别可能侵犯版权的AI生成内容
项目进展与未来展望
自2022年12月启动以来,项目已经取得了一系列重要进展:
- 2023年1月11日:发布ChatGPT检测器演示版
- 2023年1月18日:开源模型和对比语料库
- 2023年1月19日:发布研究论文

展望未来,项目团队计划继续完善HC3语料库,增加更多领域和语言的数据。同时,他们也将持续改进检测器的性能,以适应不断evolving的AI生成技术。
开源社区的力量
ChatGPT对比检测项目的成功,充分展现了开源社区的强大力量。项目团队不仅开源了数据集和模型,还积极邀请社区成员参与反馈和改进。这种开放合作的模式,为推动AI伦理和安全研究做出了重要贡献。
研究者和开发者可以通过以下方式参与项目:
- 在GitHub上star、watch和fork项目仓库
- 使用HC3数据集进行研究,并分享研究成果
- 尝试使用和改进检测器模型
- 在项目讨论区提供反馈和建议
结语
ChatGPT对比检测项目为我们提供了一个深入了解AI生成内容特征的窗口。通过HC3语料库和检测器工具,研究者可以更好地评估ChatGPT与人类专家之间的差距,同时也为应对AI生成内容带来的挑战提供了技术支持。
随着项目的不断发展,我们期待看到更多创新性的研究成果,以及AI生成内容检测技术的进步。这不仅有助于推动AI技术的健康发展,也将为构建更加安全、可信的AI生态系统做出贡献。
最后,让我们向这个项目的发起者和贡献者们致敬。正是他们的开放精神和不懈努力,才使得这样一个有意义的研究项目得以实现。我们也鼓励更多的研究者和开发者加入到这个开放的研究社区中来,共同探索AI技术的前沿,为人工智能的发展贡献自己的力量。


















