
ChatGPT与人类专家的对比:HC3语料库、评估与检测
随着ChatGPT的问世,人工智能在自然语言处理领域取得了巨大突破。然而,ChatGPT与人类专家之间的差距到底有多大?为了回答这个问题,一个研究团队开发了名为HC3(Human ChatGPT Comparison Corpus)的对比语料库,并基于该语料库进行了一系列评估和检测工作。本文将详细介绍HC3项目的背景、内容和主要成果。
HC3语料库:首个人类-ChatGPT对比语料集
HC3是首个专门用于比较人类和ChatGPT回答的语料库。该语料库包含了数万条人类专家和ChatGPT针对相同问题的回答,涵盖了开放域、金融、医疗、法律和心理学等多个领域。
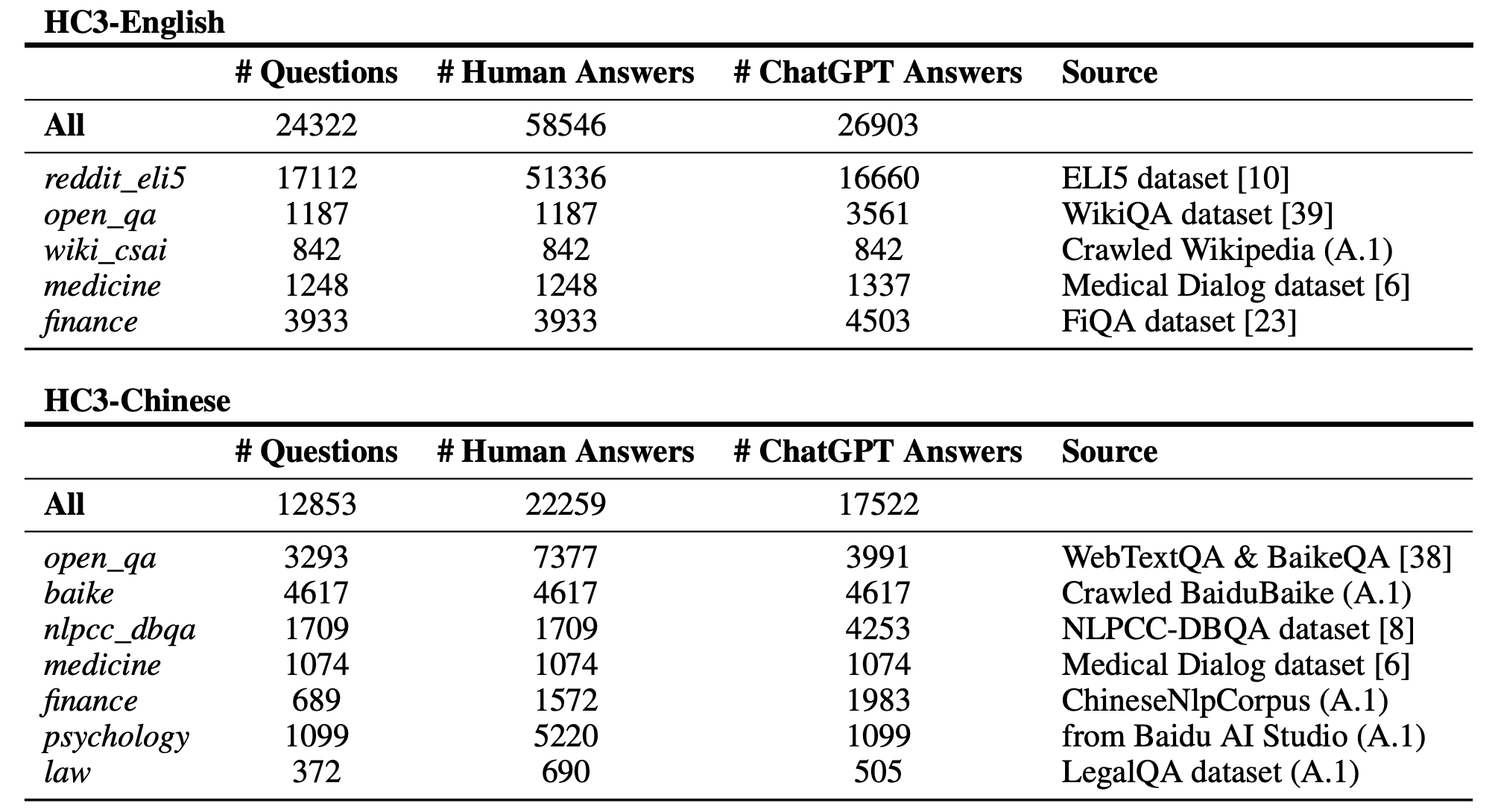
HC3语料库的主要特点包括:
- 双语支持:提供英文和中文两个版本
- 多领域覆盖:包含开放域问答、专业领域问答等
- 高质量数据:人类回答来自专业人士,确保对比的可靠性
- 开源可用:在Hugging Face和ModelScope平台上公开发布
研究者们希望通过HC3语料库,为学术界和工业界提供一个可靠的基准,用于评估ChatGPT与人类专家之间的差距,并推动相关研究的发展。
ChatGPT内容检测器:多角度识别AI生成文本
基于HC3语料库,研究团队开发了三种不同类型的ChatGPT内容检测器:
- 问答版:判断某个问题的回答是否由ChatGPT生成
- 独立文本版:判断单条文本是否由ChatGPT生成
- 语言学版:使用语言学特征来判断文本是否由ChatGPT生成
这些检测器都支持中英双语,并在Hugging Face Spaces和ModelScope平台上提供了在线演示。研究者们还开源了相关模型权重,方便其他研究者进行二次开发和改进。

研究发现:ChatGPT与人类专家的差距
通过对HC3语料库的分析和评估,研究者们发现了一些有趣的结果:
- ChatGPT在回答开放域问题时表现出色,但在专业领域仍有不足
- ChatGPT生成的文本往往更加流畅和结构化,但可能缺乏人类专家的深度洞察
- 在某些情况下,ChatGPT的回答难以与人类专家区分,这凸显了AI检测的重要性
这些发现不仅有助于我们理解ChatGPT的能力和局限性,也为未来大型语言模型的改进指明了方向。
项目背景与团队介绍
HC3项目始于2022年12月9日,正值ChatGPT发布10天后。项目团队由来自6所大学和公司的博士生和工程师组成,他们希望通过这个项目为学术界和工业界做出贡献。
项目的两个主要目标是:
- 创建开源模型,用于高效检测ChatGPT生成的内容
- 收集有价值的人类-ChatGPT对比问答语料,促进相关研究
研究团队表示:"我们是一群在ChatGPT阴影下的渺小研究者,但希望为社区做一些有意义的事。"这种谦逊而又充满热情的态度,正是推动AI领域不断进步的动力。
结语
HC3项目为我们提供了一个宝贵的资源,用于比较和评估ChatGPT与人类专家之间的差距。通过开源语料库和检测工具,该项目不仅推动了学术研究,也为解决AI生成内容带来的社会问题提供了可能的解决方案。
随着大型语言模型技术的不断发展,我们需要更多类似HC3这样的项目来帮助我们理解和应对AI带来的挑战与机遇。让我们共同期待AI技术的进步,同时也不忘思考如何让AI更好地服务于人类社会。


















