
ChatTTS-Forge入门指南 - 开源TTS生成项目的全方位工具箱
ChatTTS-Forge是一个围绕TTS(文本转语音)生成模型开发的开源项目,为开发者和研究者提供了一个功能强大的TTS工具箱。本文将介绍ChatTTS-Forge的主要功能,并汇总相关的学习资源,帮助大家快速上手这个项目。
项目简介
ChatTTS-Forge实现了以下主要功能:
- API服务器:提供TTS生成的API接口
- 基于Gradio的WebUI:方便用户通过图形界面使用TTS功能
- 多模型支持:集成了ChatTTS、FishSpeech、CosyVoice等多个TTS模型
- 语音克隆:支持使用参考音频进行语音克隆
- 长文本生成:支持超长文本的TTS生成
- SSML支持:支持使用SSML标记语言控制语音合成
- 人声增强:内置人声增强模型提升音频质量
快速开始
你可以通过以下几种方式体验和部署ChatTTS-Forge:
-
在线体验: HuggingFace Spaces
-
一键启动Colab:
-
Docker部署:
# 下载模型
python -m scripts.download_models --source modelscope
# 启动WebUI
docker-compose -f ./docker-compose.webui.yml up -d
# 启动API服务
docker-compose -f ./docker-compose.api.yml up -d
- 本地部署:
# 克隆仓库
git clone https://github.com/lenML/ChatTTS-Forge.git
cd ChatTTS-Forge
# 安装依赖
pip install -r requirements.txt
# 下载模型
python -m scripts.download_models --source modelscope
# 启动WebUI
python webui.py
# 启动API服务
python launch.py
主要功能介绍
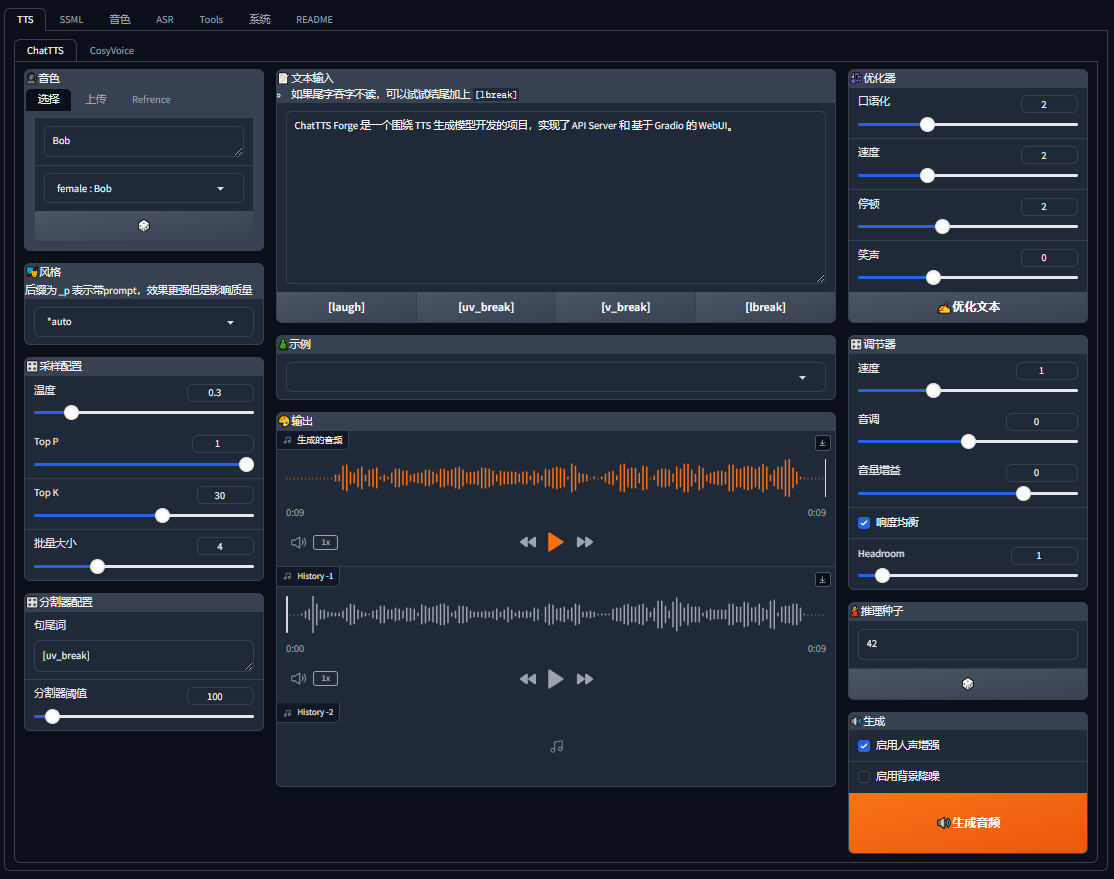
WebUI功能
ChatTTS-Forge的WebUI提供了丰富的功能:
- TTS生成:支持多种TTS模型,可切换音色、调整风格等
- 语音克隆:支持上传参考音频进行语音克隆
- 长文本生成:支持超长文本TTS,自动分割文本
- SSML编辑器:使用SSML标记语言精确控制语音合成
- 音色管理:创建、测试、调试自定义音色
- ASR转写:支持Whisper等ASR模型进行语音识别
- 音频处理:剪辑、调整、增强音频的后处理工具
API功能
除了WebUI,ChatTTS-Forge还提供了功能完善的API接口:
- TTS生成API:支持文本转语音、语音克隆等功能
- ASR转写API:支持语音识别转写
- 音色管理API:创建、获取音色信息
- 音频处理API:音频格式转换、增强等
API文档:API参考
学习资源
- 官方文档
- 安装教程
- 使用教程
- 模型下载
- 常见问题
- 社区讨论
总结
ChatTTS-Forge为TTS开发者和研究者提供了一个功能强大的工具箱,集成了多个主流TTS模型,并提供了便捷的WebUI和API接口。无论你是想快速体验最新的TTS技术,还是需要在项目中集成TTS功能,ChatTTS-Forge都是一个值得尝试的开源项目。欢迎访问GitHub仓库深入了解更多细节,并参与到项目的开发中来。










