
 Github
Github Huggingface
Huggingfacecn | en | Discord Server
🍦 ChatTTS-Forge
ChatTTS-Forge 是一个围绕 TTS 生成模型开发的项目,实现了 API Server 和基于 Gradio 的 WebUI。
你可以通过以下几种方式体验和部署 ChatTTS-Forge:
| - | 描述 | 链接 |
|---|---|---|
| 在线体验 | 部署于 HuggingFace 中 | HuggingFace Spaces |
| 一键启动 | 点击按钮,一键启动 Colab | |
| 容器部署 | 查看 docker 部分 | Docker |
| 本地部署 | 查看环境准备部分 | 本地部署 |
1. 目录
-
- 2.1. 加载模型显存要求
- 2.2. Batch Size 显存要求
-
- 3.1. webui 特性
- 3.2.
launch.py: API 服务- 3.2.1. 如何连接到 SillyTavern?
-
- 7.1. 什么是 Prompt1 和 Prompt2?
- 7.2. 什么是 Prefix?
- 7.3. Style 中
_p的区别是什么? - 7.4. 为什么开启了
--compile很慢? - 7.5. 为什么 colab 里面非常慢只有 2 it/s ?
2. GPU 显存要求
2.1. 模型加载显存需求
| 精度 | ChatTTS 模型 | Enhancer 模型 |
|---|---|---|
| 全精度 | 2GB | 3GB |
| 半精度 | 1GB | 1.5GB |
注:半精度为默认设置,全精度可通过 --no_half 参数启用。
2.2. 推理过程显存需求
| 精度 | Batch Size | 不使用 Enhancer | 使用 Enhancer |
|---|---|---|---|
| 全精度 | ≤ 4 | 2GB | 4GB |
| 全精度 | 8 | 4-10GB | 6-14GB |
| 半精度 | ≤ 4 | 1GB | 2GB |
| 半精度 | 8 | 2-6GB | 4-8GB |
注意事项:
- 显存需求与上下文长度相关,因此呈现为一个范围。
- 半精度(默认)的显存需求约为全精度的一半。
- 对于 Batch Size ≤ 4,4GB 显存通常足够进行推理。
- Batch Size 为 8 时,可能需要 6-14GB 显存,具体取决于精度和是否使用 Enhancer。
3. 安装与运行
- 确保 相关依赖 已经正确安装,
- 根据你的需求启动需要的服务。
- webui:
python webui.py - api:
python launch.py
3.1. webui 特性
- ChatTTS 模型原生功能 Refiner/Generate
- 原生 Batch 合成,高效合成超长文本
- 风格控制
- SSML
- 编辑器: 简单的 SSML 编辑,配合其他功能使用
- 分割器:超长文本分割预处理
- 播客: 支持创建编辑播客脚本
- 说话人
- 内置音色:内置众多说话人可以使用
- 说话人创建器: 支持试音抽卡,创建说话人
- 嵌入: 支持上传说话人嵌入,可复用保存下来的说话人
- 说话人合并: 支持合并说话人,微调说话人
- 提示槽
- 文字规范化
- 音质增强:
- 增强: 音质增强提高输出质量
- 降噪: 去除噪音
- 实验性功能
- 微调
- 说话人嵌入
- [WIP] GPT lora
- [WIP] AE
- [WIP] ASR
- [WIP] 修复
- 微调
3.2. launch.py: API 服务
某些情况,你并不需要 webui,那么可以使用这个脚本启动单纯的 api 服务。
launch.py 脚本启动成功后,你可以在 /docs 下检查 api 是否开启。
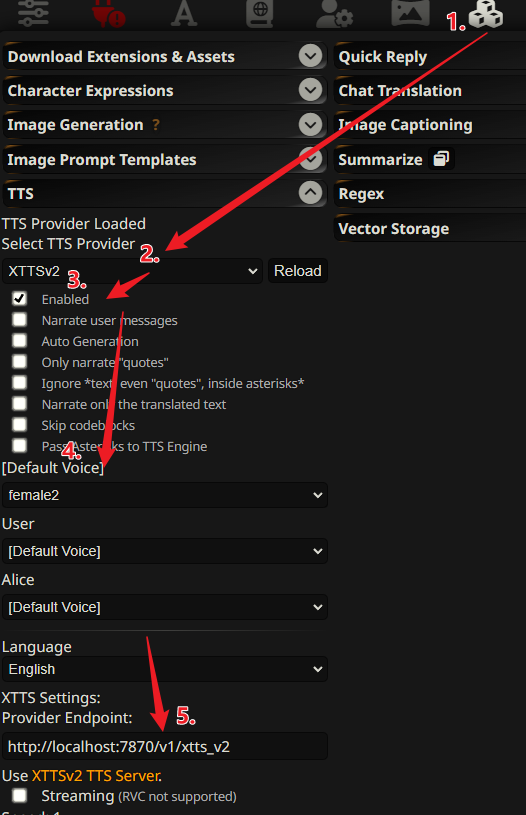
3.2.1. 如何连接到 SillyTavern?
通过 /v1/xtts_v2 系列 api,你可以方便的将 ChatTTS-Forge 连接到你的 SillyTavern 中。
下面是一个简单的配置指南:
- 点开 插件拓展
- 点开
TTS插件配置部分 - 切换
TTS Provider为XTTSv2 - 勾选
启用 - 选择/配置
声音 - [关键] 设置
Provider Endpoint到http://localhost:7870/v1/xtts_v2
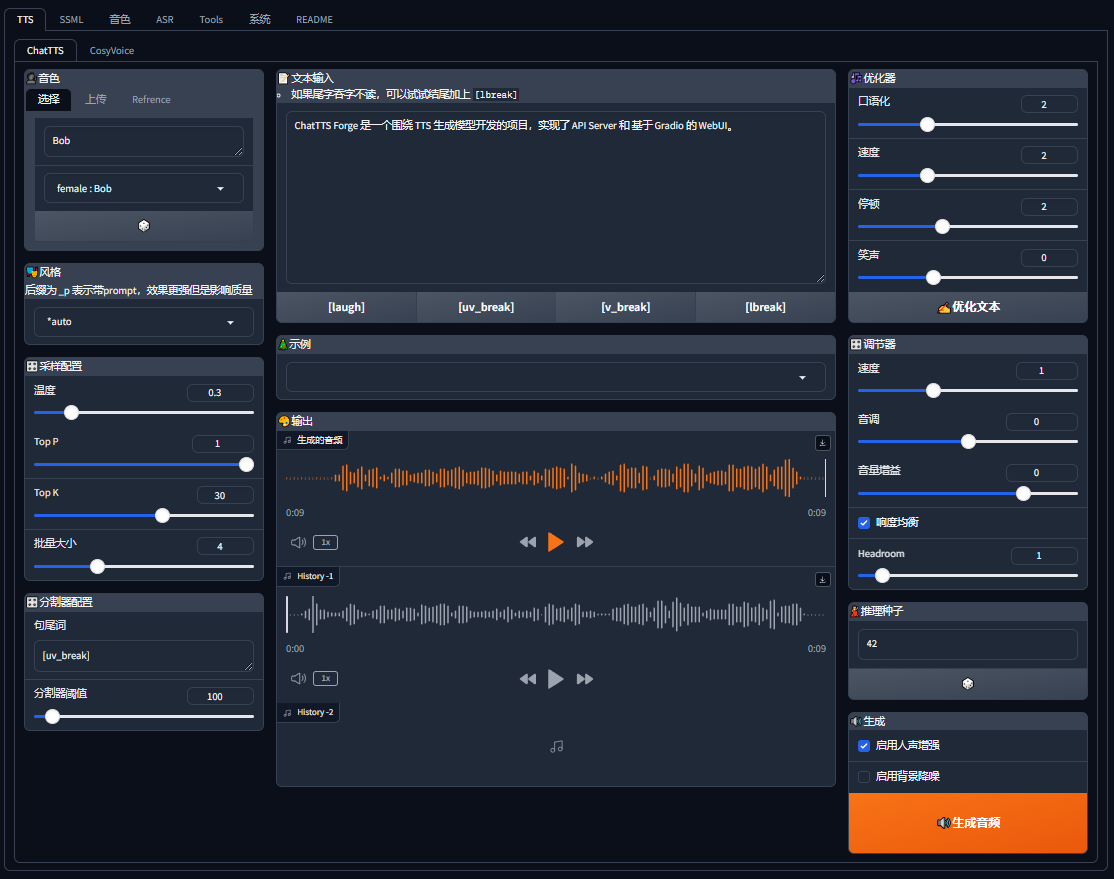
4. 演示
4.1. 风格化控制
输入
<speak version="0.1">
<voice spk="Bob" seed="42" style="narration-relaxed">
下面是一个 ChatTTS 用于合成多角色多情感的有声书示例[lbreak]
</voice>
<voice spk="Bob" seed="42" style="narration-relaxed">
黛玉冷笑道:[lbreak]
</voice>
<voice spk="female2" seed="42" style="angry">
我说呢 [uv_break] ,亏了绊住,不然,早就飞起来了[lbreak]
</voice>
<voice spk="Bob" seed="42" style="narration-relaxed">
宝玉道:[lbreak]
</voice>
<voice spk="Alice" seed="42" style="unfriendly">
“只许和你玩 [uv_break] ,替你解闷。不过偶然到他那里,就说这些闲话。”[lbreak]
</voice>
<voice spk="female2" seed="42" style="angry">
“好没意思的话![uv_break] 去不去,关我什么事儿? 又没叫你替我解闷儿 [uv_break],还许你不理我
中华美食不仅仅是食物,更是一种文化的传承。每一道菜背后都有着深厚的历史背景和文化故事。比如,北京的烤鸭,代表着皇家气派;而西安的羊肉泡馍,则体现了浓郁的地方风情。中华美食的精髓在于它追求的“天人合一”,讲究食材的自然性和烹饪过程中的和谐。
总之,中华美食博大精深,其丰富的口感和多样的烹饪技艺,构成了一个充满魅力和无限可能的美食世界。无论你来自哪里,都会被这独特的美食文化所吸引和感动。
Docker
镜像
WIP 开发中
手动 build
下载模型: `python -m scripts.download_models --source modelscope`
- webui: `docker-compose -f ./docker-compose.webui.yml up -d`
- api: `docker-compose -f ./docker-compose.api.yml up -d`
环境变量配置
- webui: [.env.webui](./.env.webui)
- api: [.env.api](./.env.api)
Roadmap
Model Supports
TTS
| 模型名称 | 流式级别 | 支持复刻 | 支持训练 | 支持 prompt | 实现情况 |
| ---------- | -------- | -------- | -------- | ----------- | ---------------------- |
| ChatTTS | token 级 | ✅ | ❓ | ❓ | ✅ |
| FishSpeech | 句子级 | ✅ | ❓ | ❓ | ✅ (SFT 版本开发中 🚧) |
| CosyVoice | 句子级 | ✅ | ❓ | ✅ | ✅ |
ASR
| 模型名称 | 流式识别 | 支持训练 | 支持多语言 | 实现情况 |
| ---------- | -------- | -------- | ---------- | -------- |
| Whisper | ✅ | ❓ | ✅ | ✅ |
| SenseVoice | ✅ | ❓ | ✅ | 🚧 |
Voice Clone
| 模型名称 | 实现情况 |
| --------- | -------- |
| OpenVoice | 🚧 |
| RVC | 🚧 |
Enhancer
| 模型名称 | 实现情况 |
| --------------- | -------- |
| ResembleEnhance | ✅ |
FAQ
Prompt1 和 Prompt2
Prompt1 和 Prompt2 都是系统提示(system prompt),区别在于插入点不同。因为测试发现当前模型对第一个 [Stts] token 非常敏感,所以需要两个提示。
- Prompt1 插入到第一个 [Stts] 之前
- Prompt2 插入到第一个 [Stts] 之后
Prefix
Prefix 主要用于控制模型的生成能力,类似于官方示例中的 refine prompt。这个 prefix 中应该只包含特殊的非语素 token,如 `[laugh_0]`、`[oral_0]`、`[speed_0]`、`[break_0]` 等。
Style 中 `_p` 的区别
Style 中带有 `_p` 的使用了 prompt + prefix,而不带 `_p` 的则只使用 prefix。
为什么开启了 `--compile` 很慢
由于还未实现推理 padding 所以如果每次推理 shape 改变都可能触发 torch 进行 compile
> 暂时不建议开启
为什么 colab 里面非常慢只有 2 it/s
请确保使用 gpu 而非 cpu。
- 点击菜单栏 【修改】
- 点击 【笔记本设置】
- 选择 【硬件加速器】 => T4 GPU
离线整合包
感谢 @Phrixus2023 提供的整合包:
https://pan.baidu.com/s/1Q1vQV5Gs0VhU5J76dZBK4Q?pwd=d7xu
相关讨论:
https://github.com/lenML/ChatTTS-Forge/discussions/65
Documents
在这里可以找到 [更多文档](./docs/readme.md)
Contributing
To contribute, clone the repository, make your changes, commit and push to your clone, and submit a pull request.
References
- ChatTTS: https://github.com/2noise/ChatTTS
- PaddleSpeech: https://github.com/PaddlePaddle/PaddleSpeech
- resemble-enhance: https://github.com/resemble-ai/resemble-enhance
- OpenVoice: https://github.com/myshell-ai/OpenVoice
- FishSpeech: https://github.com/fishaudio/fish-speech
- SenseVoice: https://github.com/FunAudioLLM/SenseVoice
- CosyVoice: https://github.com/FunAudioLLM/CosyVoice
- Whisper: https://github.com/openai/whisper
- ChatTTS 默认说话人: https://github.com/2noise/ChatTTS/issues/238











