Chronon简介:AI/ML数据管理的未来
在当今数据驱动的人工智能和机器学习时代,如何高效管理和利用大规模数据成为了每个AI/ML团队面临的关键挑战。Chronon应运而生,为这一难题提供了创新解决方案。作为一个开源的端到端特征平台,Chronon让机器学习团队能够轻松构建、部署、管理和监控用于机器学习的数据管道。
Chronon目前被广泛应用于Airbnb和Stripe等科技巨头的主要ML应用中。这个由Airbnb和Stripe联合管理和维护的项目,正在为更多企业和开发者提供强大的数据管理能力。
Chronon的核心优势
Chronon的设计理念是抽象化数据计算和服务的复杂性,为AI/ML应用提供一站式解决方案。它的主要优势包括:
-
多源数据整合: Chronon可以从各种数据源获取数据,包括事件流、数据库快照、变更数据流、服务端点和数据仓库表等。这使得ML团队能够充分利用组织内的所有数据资源。
-
在线和离线双重服务: Chronon不仅支持低延迟的在线特征服务,还能生成用于训练的离线Hive表。这种灵活性让模型开发和部署变得更加高效。
-
实时或批量精确性: 用户可以根据需求配置结果为"时间精确"或"快照精确"。前者确保在线环境中的实时更新和离线环境中的时间点准确性,后者则每天午夜更新一次特征值。
-
历史数据回填: Chronon允许从原始数据回填训练集,无需等待数月积累特征日志即可训练模型。这大大加快了模型迭代和优化的速度。
-
强大的Python API: Chronon提供直观的Python API,将数据源类型、新鲜度和上下文作为API级别的抽象,并与SQL原语无缝集成。这使得特征工程变得简单而强大。
-
自动化特征监控: Chronon自动生成监控管道,帮助用户了解训练数据质量、衡量训练-服务偏差并监控特征漂移。这确保了模型在生产环境中的稳定性和可靠性。
Chronon的工作流程
为了更好地理解Chronon的强大功能,让我们深入探讨其核心工作流程:
1. 定义特征
Chronon使用GroupBy API来定义特征。以下是一个简单的示例,展示了如何聚合用户的购买数据:
source = Source(
events=EventSource(
table="data.purchases",
topic= "events/purchases",
query=Query(
selects=select(
user="user_id",
price="purchase_price * (1 - merchant_fee_percent/100)"
),
time_column="ts"
)
)
)
window_sizes = [Window(length=day, timeUnit=TimeUnit.DAYS) for day in [3, 14, 30]]
v1 = GroupBy(
sources=[source],
keys=["user_id"],
online=True,
aggregations=[
Aggregation(
input_column="price",
operation=Operation.SUM,
windows=window_sizes
),
Aggregation(
input_column="price",
operation=Operation.COUNT,
windows=window_sizes
),
Aggregation(
input_column="price",
operation=Operation.AVERAGE,
windows=window_sizes
),
Aggregation(
input_column="price",
operation=Operation.LAST_K(10),
),
],
)
这段代码定义了一个特征集,它从原始购买事件数据中提取信息,并为每个用户计算了各种时间窗口内的购买总额、次数和平均值。
2. 特征回填
定义好特征后,Chronon可以自动进行历史数据的回填。这个过程保证了时间点准确性,避免了数据泄露问题。例如:
run.py --conf production/joins/quickstart/training_set.v1
这个命令会触发Chronon执行回填任务,生成包含所有定义特征的宽表。
3. 在线服务
对于实时推理,Chronon提供了简单的API来获取特征向量:
run.py --mode fetch --type join --name quickstart/training_set.v2 -k '{"user_id":"5"}'
这个命令可以实时获取指定用户的所有特征值,用于模型推理。
4. 一致性监控
Chronon的一个重要特性是保证线上线下数据的一致性。它提供了专门的工具来测量这种一致性:
run.py --mode consistency-metrics-compute --conf production/joins/quickstart/training_set.v2
这个命令会比较回填数据和在线获取的数据,生成一致性报告,帮助团队及时发现和解决潜在问题。
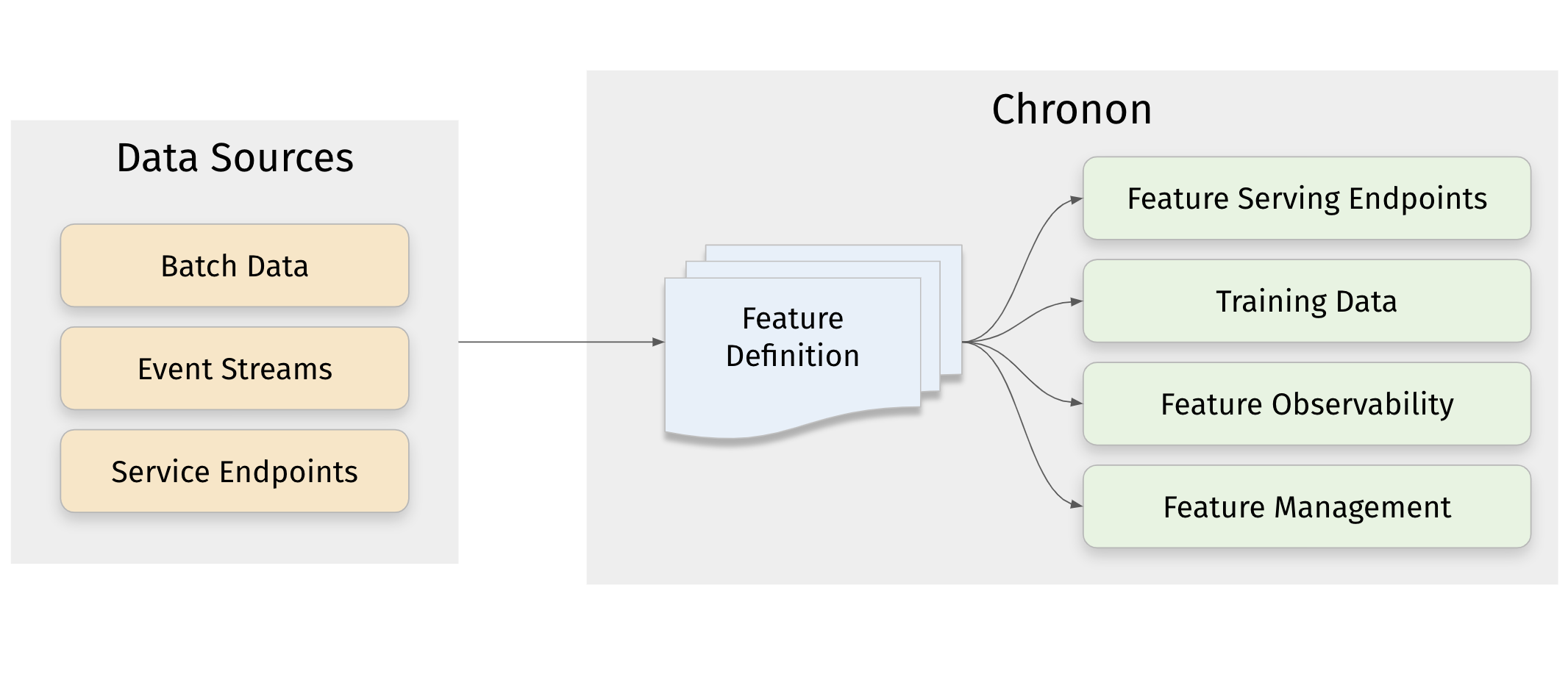
Chronon vs 传统方法
相比传统的ML特征工程方法,Chronon提供了显著的优势:
-
统一定义: 在Chronon中,特征只需定义一次,就可以用于训练数据回填和在线服务。这极大地减少了代码重复和潜在的不一致性。
-
自动化时间点准确性: Chronon的回填机制自动保证了时间点准确性,避免了常见的标签泄露问题。
-
简化的管道编排: 批处理和流处理管道的编排变得简单直观,大大减少了维护成本。
-
一致性保证: Chronon不仅保证了线上线下数据的一致性,还提供了测量和监控这种一致性的工具。
-
可扩展性: 无论是处理大规模历史数据还是高并发的实时请求,Chronon都能轻松应对。
结语
Chronon为AI/ML团队提供了一个强大而灵活的数据管理平台。通过简化特征工程、确保数据一致性、提供实时服务能力,Chronon让数据科学家和工程师能够更专注于模型开发和优化,而不是被繁琐的数据处理任务所困扰。
随着AI/ML在各行各业的深入应用,像Chronon这样的工具将在提升模型开发效率、保证数据质量方面发挥越来越重要的作用。无论您是在构建推荐系统、欺诈检测还是预测分析模型,Chronon都能为您的ML工作流程带来显著的改进。
欢迎访问Chronon官方网站了解更多信息,或加入Chronon社区Discord频道与其他开发者交流经验。让我们一起探索AI/ML数据管理的未来!









