
Chronon: 一个用于 AI/ML 的数据平台
Chronon 是一个平台,它抽象化了 AI/ML 应用程序的数据计算和服务的复杂性。用户将特征定义为原始数据的转换,然后 Chronon 可以执行批处理和流式计算、可扩展的回填、低延迟服务、保证正确性和一致性,以及一系列可观察性和监控工具。
它允许你利用组织内的所有数据,从批处理表、事件流或服务来支持你的 AI/ML 项目,而无需担心这通常需要的所有复杂编排。
有关 Chronon 的更多信息可以在 chronon.ai 找到。
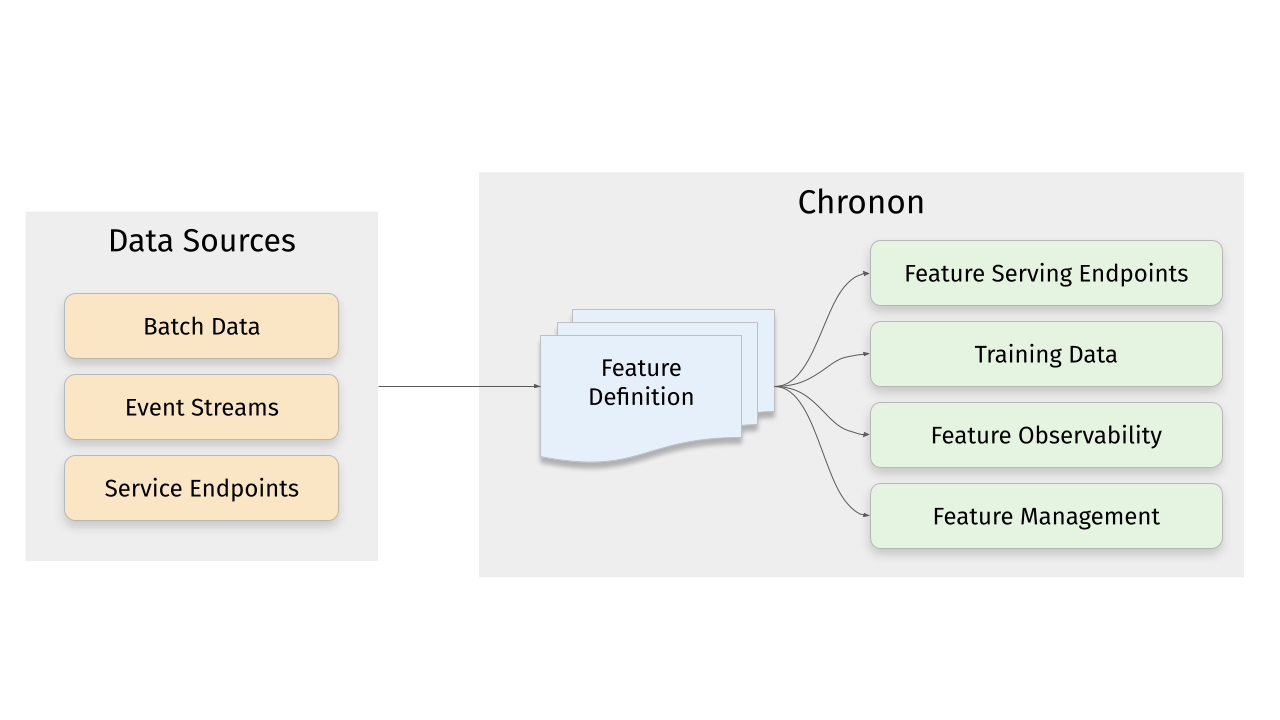
平台特性
在线服务
Chronon 提供了一个实时获取的 API,可返回特征的最新值。它支持:
- 用于批处理和实时特征计算以及更新到服务后端的托管管道
- 低延迟服务计算好的特征
- 可扩展以支持高扇出特征集
回填
ML 从业者经常需要特征值的历史视图来进行模型训练和评估。Chronon 的回填:
- 可扩展以支持大时间窗口
- 对高度倾斜的数据具有弹性
- 时间点准确,确保与在线服务保持一致
可观察性、监控和数据质量
Chronon 提供以下方面的可见性:
- 数据新鲜度 - 确保在线值正在实时更新
- 在线/离线一致性 - 确保用于模型训练和评估的回填数据与在线服务中观察到的一致
复杂转换和窗口聚合
Chronon 支持多种聚合类型。完整列表请参见此处的文档。
所有这些聚合都可以配置为在任意大小的窗口上计算。
快速入门
本节将引导你使用 Chronon 创建训练数据集,使用虚构的底层原始数据集。
包括:
- 定义特征的主要 API 组件的示例实现 -
GroupBy和Join。 - 编写这些实体的工作流程。
- 回填训练数据的工作流程。
- 上传和服务这些数据的工作流程。
- 测量回填训练数据与在线推理数据之间一致性的工作流程。
不包括:
- 对 Chronon 中各种概念和术语的深入探讨。有关这方面的内容,请参阅入门文档。
- 运行流式作业。
要求
- Docker
设置
要开始使用 Chronon,你只需下载 docker-compose.yml 文件并在本地运行:
curl -o docker-compose.yml https://chronon.ai/docker-compose.yml
docker-compose up
当你看到打印出一些数据并注明 only showing top 20 rows 时,就可以继续进行教程了。
简介
在这个例子中,假设我们是一家大型在线零售商,我们检测到一个基于用户购买后退货的欺诈途径。我们想训练一个模型,在结账流程开始时调用,预测这笔交易是否可能导致欺诈性退货。
原始数据源
虚构的原始数据包含在 data 目录中。它包括四个表:
- Users - 包括用户的基本信息,如账户创建日期;建模为每日更新的批处理数据源
- Purchases - 所有用户购买的日志;建模为具有流式(即 Kafka)事件总线对应项的日志表
- Returns - 用户所有退货的日志;建模为具有流式(即 Kafka)事件总线对应项的日志表
- Checkouts - 所有结账事件的日志;这是驱动我们模型预测的事件
在 Docker 容器中启动 shell 会话
在新的终端窗口中运行:
docker-compose exec main bash
这将在 chronon docker 容器内打开一个 shell。
Chronon 开发
现在设置步骤已完成,我们可以开始创建和测试各种 Chronon 对象来定义转换和聚合,并生成数据。
步骤 1 - 定义一些特征
让我们从三个特征集开始,这些特征集建立在我们的原始输入源之上。
注意:这些 Python 定义已经在你的 chronon 镜像中。在步骤 3 - 回填数据之前,你不需要运行任何内容,届时你将为这些定义运行计算。
特征集 1:购买数据特征
我们可以将购买日志数据聚合到用户级别,以便了解该用户在我们平台上的先前活动。具体来说,我们可以计算他们在各个时间窗口内的前期购买金额的 SUM、COUNT 和 AVERAGE。
由于此特征基于包含表和主题的源构建,因此可以在批处理和流式处理中计算其特征。
source = Source(
events=EventSource(
table="data.purchases", # 这指向包含历史购买事件的日志表
topic=None, # 流式处理目前不是快速入门的一部分,但这里会定义实时事件的主题
query=Query(
selects=select("user_id","purchase_price"), # 选择我们关心的字段
time_column="ts") # 事件时间
))
window_sizes = [Window(length=day, timeUnit=TimeUnit.DAYS) for day in [3, 14, 30]] # 定义一些要在下面使用的窗口大小
v1 = GroupBy(
sources=[source],
keys=["user_id"], # 我们按用户聚合
aggregations=[Aggregation(
input_column="purchase_price",
operation=Operation.SUM,
windows=window_sizes
), # 各种窗口内的购买价格总和
Aggregation(
input_column="purchase_price",
operation=Operation.COUNT,
windows=window_sizes
), # 各种窗口内的购买次数
Aggregation(
input_column="purchase_price",
operation=Operation.AVERAGE,
windows=window_sizes
) # 各种窗口内用户的平均购买
],
)
完整代码文件请参见:purchases GroupBy。这也在你的 docker 镜像中。我们将在步骤 3 - 回填数据中为它和其他 GroupBy 运行计算。
特征集 2:退货数据特征
我们在 returns GroupBy 中对退货数据执行类似的聚合。这里没有包含代码,因为它看起来与上面的例子相似。
特征集 3:用户数据特征
将用户数据转换为特征稍微简单一些,主要是因为没有需要包含的聚合。在这种情况下,源数据的主键与特征的主键相同,所以我们只是提取列值,而不是对行执行聚合:
source = Source(
entities=EntitySource(
snapshotTable="data.users", # 这指向包含整个产品目录每日快照的表
query=Query(
selects=select("user_id","account_created_ds","email_verified"), # 选择我们关心的字段
)
))
v1 = GroupBy(
sources=[source],
keys=["user_id"], # 主键与源表的主键相同
aggregations=None # 在这种情况下,没有需要定义的聚合或窗口
)
摘自 users GroupBy。
步骤 2 - 将特征连接在一起
接下来,我们需要将之前定义的特征回填到一个单一表中用于模型训练。这可以通过使用 Join API 来实现。
对于我们的用例来说,确保特征在正确的时间戳计算是非常重要的。由于我们的模型在结账流程开始时运行,我们需要确保在回填中使用相应的时间戳,这样模型训练的特征值在逻辑上与模型在在线推理中看到的匹配。
Join是驱动训练数据特征回填的API。它主要执行以下功能:
- 将多个特征组合成一个宽视图(因此命名为
Join)。 - 定义应执行特征回填的主键和时间戳。Chronon可以保证特征值在此时间戳时是正确的。
- 执行可扩展的回填。
以下是我们的join示例:
source = Source(
events=EventSource(
table="data.checkouts",
query=Query(
selects=select("user_id"), # 用于连接各个GroupBy的主键
time_column="ts",
) # 用于计算特征值的事件时间
))
v1 = Join(
left=source,
right_parts=[JoinPart(group_by=group_by) for group_by in [purchases_v1, refunds_v1, users]] # 包含三个GroupBy
)
join的left侧定义了回填的时间戳和主键(注意它是建立在checkout事件之上的,这由我们的用例决定)。
请注意,这个Join将上述三个GroupBy组合成一个数据定义。在下一步中,我们将运行命令来执行整个管道的计算。
第3步 - 回填数据
定义join后,我们使用以下命令编译它:
compile.py --conf=joins/quickstart/training_set.py
这将其转换为thrift定义,我们可以用以下命令提交给spark:
run.py --conf production/joins/quickstart/training_set.v1
回填的输出将包含左侧源的user_id和ts列,以及我们创建的三个GroupBy中的11个特征列。
特征值将为左侧的每个user_id和ts计算,并保证时间准确性。例如,如果左侧的一行是user_id = 123和ts = 2023-10-01 10:11:23.195,那么purchase_price_avg_30d特征将为该用户计算,精确的30天窗口截止于该时间戳。
现在你可以使用spark sql shell查询回填的数据:
spark-sql
然后:
spark-sql> SELECT user_id, quickstart_returns_v1_refund_amt_sum_30d, quickstart_purchases_v1_purchase_price_sum_14d, quickstart_users_v1_email_verified from default.quickstart_training_set_v1 limit 100;
注意,这只选择了几列。你也可以运行select * from default.quickstart_training_set_v1 limit 100来查看所有列,但请注意,该表非常宽,结果可能在你的屏幕上不太易读。
要退出sql shell,可以运行:
spark-sql> quit;
在线流程
现在我们已经创建了join并回填了数据,下一步将是训练模型。这不是本教程的一部分,但假设它已完成,之后的步骤就是将模型在线产品化。为此,我们需要能够获取用于模型推理的特征向量。这就是下一节要介绍的内容。
上传数据
为了服务在线流程,我们首先需要将数据上传到在线KV存储。这与我们在上一步中运行的回填有两点不同:
- 数据不是历史回填,而是每个主键最新的特征值。
- 数据存储是适用于点查询的事务性KV存储。我们在docker镜像中使用MongoDB,但你可以自由集成你选择的数据库。
上传purchases GroupBy:
run.py --mode upload --conf production/group_bys/quickstart/purchases.v1 --ds 2023-12-01
spark-submit --class ai.chronon.quickstart.online.Spark2MongoLoader --master local[*] /srv/onlineImpl/target/scala-2.12/mongo-online-impl-assembly-0.1.0-SNAPSHOT.jar default.quickstart_purchases_v1_upload mongodb://admin:admin@mongodb:27017/?authSource=admin
上传returns GroupBy:
run.py --mode upload --conf production/group_bys/quickstart/returns.v1 --ds 2023-12-01
spark-submit --class ai.chronon.quickstart.online.Spark2MongoLoader --master local[*] /srv/onlineImpl/target/scala-2.12/mongo-online-impl-assembly-0.1.0-SNAPSHOT.jar default.quickstart_returns_v1_upload mongodb://admin:admin@mongodb:27017/?authSource=admin
上传Join元数据
如果我们想使用FetchJoin API而不是FetchGroupby,那么我们还需要上传join元数据:
run.py --mode metadata-upload --conf production/joins/quickstart/training_set.v2
这使得在线获取器知道如何将对此join的请求分解为单独的GroupBy请求,返回统一的向量,类似于Join回填如何生成包含所有特征的宽视图表。
获取数据
通过定义上述实体,你现在可以通过简单的API调用轻松获取特征向量。
获取join:
run.py --mode fetch --type join --name quickstart/training_set.v2 -k '{"user_id":"5"}'
你也可以获取单个GroupBy(这不需要之前执行的Join元数据上传步骤):
run.py --mode fetch --type group-by --name quickstart/purchases.v1 -k '{"user_id":"5"}'
对于生产环境,Java客户端通常直接嵌入到服务中。
Map<String, String> keyMap = new HashMap<>();
keyMap.put("user_id", "123");
Fetcher.fetch_join(new Request("quickstart/training_set_v1", keyMap))
示例响应
> '{"purchase_price_avg_3d":14.3241, "purchase_price_avg_14d":11.89352, ...}'
注意:此Java代码在docker环境中不可运行,它只是一个说明性示例。
记录获取日志并测量在线/离线一致性
如本README的介绍部分所讨论的,Chronon的核心保证之一是在线/离线一致性。这意味着你用于训练模型的数据(离线)与模型在生产推理中看到的数据(在线)匹配。
其中一个关键要素是时间准确性。可以表述为:在回填特征时,为join左侧提供的任何给定timestamp产生的值应该与在那个特定timestamp在线获取该特征时返回的值相同。
Chronon不仅保证这种时间准确性,还提供了一种测量方法。
测量管道从在线获取请求的日志开始。这些日志包括请求的主键和时间戳,以及获取的特征值。然后,Chronon将键和时间戳传递给Join回填作为左侧,要求计算引擎回填特征值。然后它比较回填的值和实际获取的值以测量一致性。
第1步:记录获取
首先,确保你运行了几个获取请求。运行:
run.py --mode fetch --type join --name quickstart/training_set.v2 -k '{"user_id":"5"}'
多次运行以生成一些获取记录。
完成后,你可以运行以下命令来创建可用的日志表(这些命令生成具有正确模式的日志hive表):
spark-submit --class ai.chronon.quickstart.online.MongoLoggingDumper --master local[*] /srv/onlineImpl/target/scala-2.12/mongo-online-impl-assembly-0.1.0-SNAPSHOT.jar default.chronon_log_table mongodb://admin:admin@mongodb:27017/?authSource=admin
compile.py --conf group_bys/quickstart/schema.py
run.py --mode backfill --conf production/group_bys/quickstart/schema.v1
run.py --mode log-flattener --conf production/joins/quickstart/training_set.v2 --log-table default.chronon_log_table --schema-table default.quickstart_schema_v1
这将创建一个default.quickstart_training_set_v2_logged表,其中包含您之前进行的每个获取请求的结果,以及您发出请求的时间戳和您请求的user。
**注意:**一旦您运行上述命令,它将创建并"关闭"日志分区,这意味着如果您在同一天(UTC时间)进行额外的获取,它将不会追加。如果您想回去为在线/离线一致性生成更多请求,可以在重新运行上述命令之前删除该表(在spark-sqlshell中运行DROP TABLE default.quickstart_training_set_v2_logged)。
现在您可以使用以下命令计算一致性指标:
run.py --mode consistency-metrics-compute --conf production/joins/quickstart/training_set.v2
这个作业将从日志表(在本例中为default.quickstart_training_set_v2_logged)中获取主键和时间戳,并使用这些信息创建并运行一个连接回填。然后它将回填的结果与实际在线获取的记录值进行比较。
它会生成两个输出表:
default.quickstart_training_set_v2_consistency:一个人类可读的表,您可以查询它来查看一致性检查的结果。- 您可以通过在docker bash会话中运行
spark-sql来进入sql shell,然后查询该表。 - 请注意,它有许多列(每个特征有多个指标),因此您可能想先运行
DESC default.quickstart_training_set_v2_consistency,然后选择几个您关心的列进行查询。
- 您可以通过在docker bash会话中运行
default.quickstart_training_set_v2_consistency_upload:一个KV字节列表,上传到在线KV存储,可用于支持在线数据质量监控流程。不适合人类直接阅读。
结论
使用chronon进行特征工程工作可以在多个方面简化和改进您的机器学习工作流程:
- 您可以在一个地方定义特征,并将这些定义用于训练数据回填和在线服务。
- 回填自动保证时间点正确性,避免了标签泄露和训练数据与在线推理之间的不一致。
- 简化了批处理和流式处理管道的编排,以保持特征的最新状态。
- Chronon提供了简单的特征获取端点。
- 保证并可衡量一致性。
要更详细地了解使用Chronon的好处,请参阅Chronon优势文档。
Chronon相对于其他方法的优势
Chronon对试图构建"在线"模型(实时服务请求)而非批处理工作流的人工智能/机器学习从业者提供了最大的价值。
没有Chronon,从事这些项目的工程师需要弄清楚如何为他们的模型获取训练/评估以及生产推理的数据。随着进入这些模型的数据复杂性增加(多个来源、复杂的转换如窗口聚合等),支持这种数据管道的基础设施挑战也随之增加。
通常,我们观察到机器学习从业者采用以下两种方法之一:
记录和等待方法
在这种方法中,用户从模型推理将运行的在线服务环境中可用的数据开始。将相关特征记录到数据仓库。一旦积累了足够的数据,就在日志上训练模型,并使用相同的数据进行服务。
优点:
- 保证用于训练模型的特征在服务时可用
- 模型可以访问服务调用特征
- 模型可以访问请求上下文中的数据
缺点:
- 可能需要很长时间才能积累足够的数据来训练模型
- 并非总是可以执行窗口聚合(对生产数据库运行大范围查询不具有可扩展性,事件流也是如此)
- 无法利用数据仓库中已有的丰富数据
- 在应用层维护数据转换逻辑很混乱
复制离线-在线方法
在这种方法中,用户使用数据仓库中的数据训练模型,然后想办法在在线环境中复制这些特征。
优点:
- 您可以使用广泛的数据集进行训练
- 数据仓库非常适合进行大型聚合和其他计算密集型转换
缺点:
- 通常很容易出错,导致训练和服务之间的数据不一致
- 需要维护大量复杂的基础设施才能开始使用这种方法
- 提供实时更新的特征变得更加复杂,特别是对于大型窗口聚合
- 不太可能很好地扩展到多个模型
Chronon方法
使用Chronon,您可以使用组织中可用的任何数据,包括数据仓库中的所有内容、任何流式源、服务调用等,并保证在线和离线环境之间的一致性。它抽象出了编排和维护这种数据管道的基础设施复杂性,因此用户只需在简单的API中定义特征,并相信Chronon会处理好其余的部分。
贡献
我们欢迎对Chronon项目的贡献!请阅读CONTRIBUTING了解详情。
支持
使用GitHub问题追踪器报告错误或提出功能请求。 加入我们的社区Discord频道进行讨论、获取提示和支持。











