
ChunkLlama:无需训练即可扩展大语言模型长上下文能力
大语言模型(LLMs)在处理和生成连贯文本方面表现出色,但当输入token数量超过其预训练长度时,其能力会显著削弱。考虑到微调大规模模型的高昂成本,香港大学自然语言处理实验室(HKUNLP)提出了一种名为双重块注意力(Dual Chunk Attention, DCA)的创新技术,可以将Llama2 70B等模型的上下文窗口扩展至10万个以上token,而无需任何额外训练。这项技术被命名为ChunkLlama,为解决长文本理解难题提供了全新思路。
双重块注意力:巧妙拆解长序列注意力计算
DCA的核心思想是将长序列的注意力计算拆解为基于块的模块,有效捕获同一块内(Intra-Chunk)和不同块之间(Inter-Chunk)token的相对位置信息。这种设计不仅保留了原始预训练模型的能力,还能无缝集成FlashAttention等主流高效推理库,实现长上下文与高效计算的完美结合。
通过对Llama2/3 70B模型应用DCA技术,ChunkLlama展现出惊人的外推能力,可以处理长达10万token的上下文,并在实际长文本任务中取得与微调模型相当甚至更优的性能。值得一提的是,相比闭源的GPT-3.5-16k模型,ChunkLlama-70B在各项任务上已达到其94%的性能水平,成为一个极具潜力的开源替代方案。

轻松集成,快速上手
作为一种无需训练的方法,ChunkLlama的使用异常简单。只需在原有Llama2模型的推理代码中添加一行代码即可:
from chunkllama_attn_replace import replace_with_chunkllama
replace_with_chunkllama(pretraining_length=4096) # Llama3使用8192
对于其他基础模型,ChunkLlama同样提供了便捷的接口:
from chunkllama_attn_replace import replace_with_chunkmistral, replace_with_chunkmixtral
from chunkqwen_attn_replace import replace_with_chunkqwen
replace_with_chunkmistral(pretraining_length=32768) # Mistral-v0.2
replace_with_chunkmixtral(pretraining_length=32768) # Mixtral MOE model
replace_with_chunkqwen(pretraining_length=32768) # Qwen 1.5
强大的长文本处理能力
ChunkLlama在多个长文本任务上展现出色性能:
-
语言建模: 在PG19验证集上,ChunkLlama3-70b在4k到160k的不同长度输入下均保持较低困惑度,而原始Llama3-70b在16k以上输入时困惑度急剧上升。
-
少样本学习: 在NarrativeQA、Qasper、QuALITY和QMSum四个长文本基准测试中,ChunkLlama3-70b的表现与Llama2 Long-70b相当或更优。
-
零样本学习: 在L-Eval的四个封闭式任务上,ChunkLlama3-70b甚至超越了GPT4-32k(2023版本)的表现。
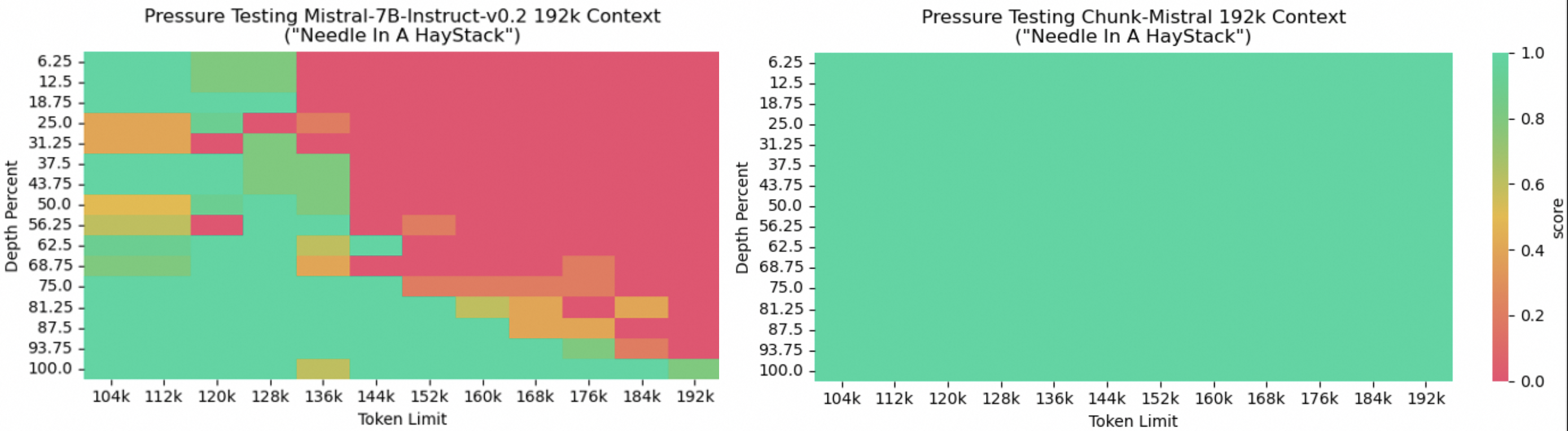
实验与验证
研究团队提供了丰富的实验代码和数据,方便其他研究者复现结果并进行进一步探索:
-
困惑度验证: 使用PG19数据集评估模型在不同长度输入下的语言建模能力。
-
密钥检索: 测试模型从长文本中准确检索特定信息的能力。
-
大海捞针: 评估模型在冗长无关文本中定位关键信息的能力。
-
少样本和零样本学习: 使用多个长文本基准数据集,如NarrativeQA、QMSum等,全面评估模型的泛化能力。
开源与合作
ChunkLlama项目采用Apache License 2.0许可证,鼓励学术研究和开源合作。项目源代码、数据集和预训练权重均可在GitHub仓库中获取。研究团队诚挚感谢社区贡献者的支持,并欢迎更多研究者加入,共同推动大语言模型长上下文处理能力的进步。
结语
ChunkLlama为解决大语言模型长上下文处理难题提供了一种简单有效的方案。通过巧妙的注意力机制设计,它不仅大幅提升了模型的长文本理解能力,还保持了高效的计算性能。作为一种无需训练的方法,ChunkLlama降低了研究和应用的门槛,有望在学术界和工业界产生广泛影响。未来,随着更多研究者的参与和改进,我们有理由期待ChunkLlama能够在更多领域发挥重要作用,推动大语言模型在长文本处理方面取得新的突破。









