
 Github
Github Huggingface
Huggingface 论文
论文

大型语言模型的无需训练的长上下文扩展
概述
双重分块注意力是一种无需训练且有效的方法,可以将大型语言模型(LLMs)的上下文窗口扩展到原始预训练长度的8倍以上。我们将基于Llama的双重分块注意力模型称为ChunkLlama。DCA可以无缝集成(1)流行的外推方法,如位置插值(PI)、NTK感知RoPE和YaRN;(2)广泛使用的内存高效推理库,如FlashAttention和vLLM。
由于在更长序列上进行持续预训练的高成本,此前发布的长上下文模型通常限制在7B/13B的规模。我们证明,通过将DCA应用于Llama-2/3 70B,该模型表现出惊人的外推能力(10万上下文长度),并对实际长上下文任务有很强的理解能力。
更新
- 我们添加了Flash Decoding以实现带KV缓存的高效推理。单个80G A100 GPU可以支持Llama2 7B在9万输入长度下的KV缓存推理,Llama3 8B则可支持16万。标准注意力模型的Flash解码也可在此处获得。
(标准自注意力的使用方法)
from flash_decoding_llama import replace_with_flashdecoding
replace_with_flashdecoding(max_prompt_length) # max_prompt_length是最大输入长度,例如131072
- 我们添加了ChunkLlama3的结果。Llama3使用8k预训练上下文,与Llama2具有相同的架构,因此无需更改代码。以下是在PG19上的语言建模结果:
| 模型 | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k |
|---|---|---|---|---|---|---|---|---|
| ChunkLlama3-8b | 9.04 | 8.71 | 8.61 | 8.62 | 8.95 | 9.43 | 10.04 | 10.66 |
| ChunkLlama3-70b | 5.36 | 5.16 | 5.14 | 5.14 | 5.21 | 5.32 | 5.40 | 5.45 |
ChunkLlama3-8b在所有文档深度上都达到了100%的检索准确率。我们在基础模型上的少样本结果和对话模型上的零样本结果显示,ChunkLlama3-70b的性能与GPT-4(2023/06/13)和Llama2 Long 70b相当(详细结果)。
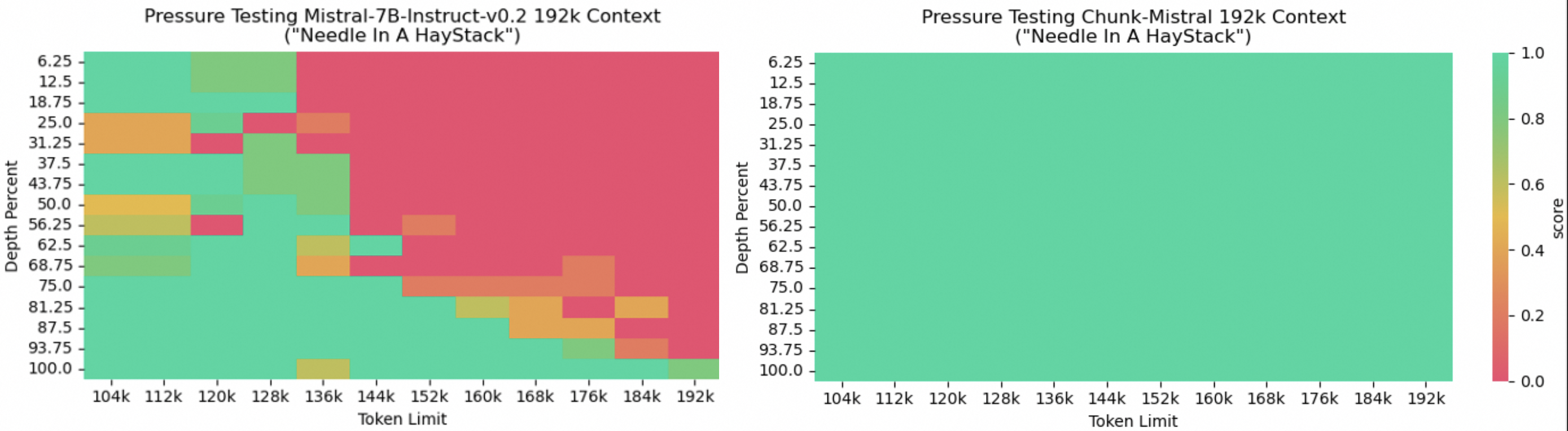
- 我们添加了可扩展到20万+上下文的Mistral/Mixtral和Qwen
🚀快速开始
作为一种无需训练的方法,只需在原有的Llama2模型推理代码中添加一行:
# `transformers==4.37.2`
from chunkllama_attn_replace import replace_with_chunkllama
# flash解码:flash_decoding_chunkllama import replace_with_chunkllama
replace_with_chunkllama(pretraining_length=4096) # 如果使用Llama3,则pretraining_length=8192
对于其他基础模型:
from chunkllama_attn_replace import replace_with_chunkmistral, replace_with_chunkmixtral
from chunkqwen_attn_replace import replace_with_chunkqwen
replace_with_chunkmistral(pretraining_length=32768) # Mistral-v0.2
replace_with_chunkmixtral(pretraining_length=32768) # Mixtral MOE模型
replace_with_chunkqwen(pretraining_length=32768) # Qwen 1.5
完整推理代码
from transformers import AutoTokenizer, AutoModelForCausalLM
from flash_decoding_chunkllama import replace_with_chunkllama
# flash解码:from chunkllama_attn_replace import replace_with_chunkllama
##### 添加此行 #####
replace_with_chunkllama(pretraining_length=4096)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", attn_implementation="flash_attention_2", trust_remote_code=True, torch_dtype=torch.bfloat16)
inputs = tokenizer("长...文档\n 问:如何扩展LLMs的上下文窗口?", return_tensors="pt")
output_ids = model.generate(**inputs, max_length=128)[0]
print(tokenizer.decode(output_ids))
与长篇PDF文件对话
我们在Popular_PDFs目录中提供了一系列关于LLMs长上下文扩展的有影响力论文。通过使用--pdf参数,您可以通过ChunkLlama⭐了解该领域的最新进展。

使用要求
- 准备环境。
pip install -r requirements.txt
pip install flash-attn --no-build-isolation (FlashAttention >= 2.5.0)
-
下载预训练权重(Extended ctx表示DCA启用的上下文长度)。 | 支持的模型 | 扩展上下文 | |:-----------------------------------------------------------------------------------|:----------:| | 基础模型 | | | Llama-2-7b-hf (4k) | 32k | | Llama-2-13b-hf (4k) | 32k | | Llama-2-70b-hf (4k) | 128k | | Meta-Llama-3-8B (8k) | 96k | | Meta-Llama-3-70B (8k) | 200k+ | | Together的LLaMA-2-7b-32k | 200k | | SFT模型 | | | Llama-2-7b-chat-hf (4k) | 32k | | Llama-2-13b-chat-hf (4k) | 32k | | Llama-2-70b-chat-hf (4k) | 128k | | Meta-Llama-3-8B-Instruct (8k) | 96k | | Meta-Llama-3-70B-Instruct (8k) | 200k+ | | Vicuna-1.5-7b-16k | 200k | | Vicuna-1.5-13b-16k | 200k | | Mixtral 8x7b & Mistral 7b | 200k+ | | Qwen1.5 中文 | 200k |
-
部署您自己的演示。 我们在
run_chunkllama_100k.py、run_together_200k.py和run_vicuna_200k.py中提供了三个如何在流行的LLM上使用DCA的示例。
运行演示:
python run_chunkllama_100k.py --max_length 16000 --scale 13b (7b/13b/70b) --pdf Popular_PDFs/longlora.pdf
如果在处理更长的输入或更大的模型时遇到OOM问题,我们建议使用张量并行:
deepspeed run_chunkllama_100k_ds.py --max_length 64000 --scale 13b (7b/13b/70b) --pdf Popular_PDFs/longlora.pdf
📌 注意:我们发现,尽管7B模型在长上下文上可以达到较低的困惑度,但它们在实际任务中经常会犯错,包括那些经过微调的版本。因此,我们建议使用更大的13B(ChunkLlama-13b,Chunk-Vicuna-13b)或70B(ChunkLlama-70B)模型以获得更高的准确性。
微调
ChunkLlama可以通过在长对话上进行微调来进一步改进。我们在16k的上下文窗口上,使用之前SFT数据集ShareGPT和AlpacaGPT4的连接对话,对ChunkLlama进行了进一步训练。 我们使用的数据可在这里获得。
cd fine-tune
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export WANDB_MODE=dryrun
python -m torch.distributed.run --nproc_per_node=8 \
train_chunkllama_16k.py \
--model_name_or_path meta-llama/llama-2-7b-chat-hf \
--bf16 \
--output_dir checkpoints/chunkllama-7b-release \
--max_steps 1600 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 2 \
--evaluation_strategy no \
--save_strategy steps \
--save_steps 400 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True \
--model_max_length 16384 \
--gradient_checkpointing True \
--lazy_preprocess True \
--pretraining_length 4096
您可以更改--model_name_or_path、--output_dir为您自己的目录。在我们的实验中,我们直接训练了Llama2的聊天版本,您也可以使用其基础版本。
实验
本节包含在不同类型的长上下文任务上验证ChunkLlama的数据和代码。
在PG19上的困惑度验证
cd ppl
python test_ppl.py --seq_len 16384 --scale 13b (7b/13b/70b) --data_path pg19_llama2.validation.bin
其中--seq_len 16384表示输入提示的长度。我们使用了由longlora处理的PG19验证集的标记化版本。原始数据和标记化数据在ppl文件夹中。
密钥检索
我们提供了一种测试密钥检索准确性的方法。例如,
cd passkey
python test_passkey.py --seq_len 16384 --scale 13b (7b/13b/70b)
大海捞针
我们提供了一种测试大海捞针准确性的方法。例如,
cd need_in_a_haystack
# 以下命令将生成一个jsonl文件
python retrieve_needle.py --max_length 192k --model mistral --pretraining_length 32384
# 对于Llama:python retrieve_needle.py --max_length 192k --model Llama2 --pretraining_length 4096
# 生成图表
python draw.py
少样本学习
少样本学习的实验设置与Llama2 Long相同。我们使用4个流行的长文本基准测试:NarrativeQA、QMSum、Qasper和Quality。 我们还发布了包含上下文示例的数据集few-shot-data。我们报告了它们在验证集上的结果。上下文示例是从训练集中随机选择的。
cd few-shot
python test_few_shot.py --data_path data/few_shot_quality.jsonl --max_length 16k --scale 13b
其中--data_path表示数据集的路径,假设数据保存在few-shot/data/中。
生成结果将保存到Predictions/Chunkllama-13b16k/few_shot_quality.json
我们使用Scrolls提供的验证脚本来获取结果:
python auto_eval.py --dataset_name quality --metrics_output_dir ./ --predictions Predictions/Chunkllama-13b16k/few_shot_quality.json --test_data_file data/few_shot_quality.jsonl
零样本学习
我们还在零样本学习任务上测试了我们的方法在Llama2对话版本上的表现。 考虑到公平评估开放式任务的挑战,我们从L-Eval中选择了4个封闭式任务,输入长度范围从3k到27个标记不等。
cd zero-shot
python test_zero_shot.py --task_path Closed-ended-tasks/coursera.jsonl --max_length 16k --scale 13b
实验设置和评估脚本与L-Eval官方仓库中的相同。
python Evaluation/auto_eval.py --pred_file Predictions/Chunkllama-13b16k/coursera.jsonl
ChunkLlama3
PG19验证集上的困惑度:
| 模型 | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k |
|---|---|---|---|---|---|---|---|---|
| Llama3-8b | 9.04 | 8.71 | 78.88 | >100 | >100 | >100 | >100 | >100 |
| ChunkLlama3-8b | 9.04 | 8.71 | 8.61 | 8.62 | 8.95 | 9.43 | 10.04 | 10.66 |
| Llama3-70b | 5.36 | 5.16 | >100 | >100 | >100 | >100 | >100 | >100 |
| ChunkLlama3-70b | 5.36 | 5.16 | 5.14 | 5.14 | 5.21 | 5.32 | 5.40 | 5.45 |
4个研究基准测试上的少样本结果:
| 模型 | NarrativeQA(0-shot) | Qasper(2-shot) | QuALITY(2-shot) | QMSum(1-shot) |
|---|---|---|---|---|
| ChunkLlama3-8b | 27.4 | 30.5 | 52.6 | 15.4 |
| Llama2 Long-7b | 21.9 | 27.8 | 43.2 | 14.9 |
| ChunkLlama3-70b | 33.7 | 33.1 | 75.4 | 16.0 |
| Llama2 Long-70b | 30.9 | 35.7 | 79.7 | 16.5 |
L-Eval上的零样本结果(使用对话模型):
| 模型 | TOEFL | QuALITY | Coursera | SFiction |
|---|---|---|---|---|
| ChunkLlama3-8b | 83.27 | 63.86 | 56.24 | 70.31 |
| ChunkLlama3-70b | 84.75 | 82.17 | 76.88 | 75.78 |
| GPT4-32k (2023) | 84.38 | 82.17 | 75.58 | 74.99 |
致谢
我们衷心感谢以下人士(作品)为ChunkLlama提供的帮助:
- 我们从苏剑林的博客中获得了有用的背景知识和见解。我们建议感兴趣的研究人员阅读他的博客,以更好地理解大语言模型的长文本扩展。
- 本工作基于LLaMA2作为预训练模型。我们还使用了Vicuna、Together的Llama2分支和CodeLlama。
- 我们使用了LongChat的代码进行微调过程,并使用了longlora的代码验证我们的方法。
- 我们感谢陈昱康的帮助和宝贵讨论。
- 我们感谢闫航对本工作的宝贵意见。
引用
@misc{an2024trainingfree,
title={Training-Free Long-Context Scaling of Large Language Models},
author={Chenxin An and Fei Huang and Jun Zhang and Shansan Gong and Xipeng Qiu and Chang Zhou and Lingpeng Kong},
year={2024},
eprint={2402.17463},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
许可证
- ChunkLlama根据Apache License 2.0获得许可。这意味着它要求保留版权和许可声明。
- 数据和权重根据CC-BY-NC 4.0许可证提供。它们仅被许可用于研究目的,并且仅允许非商业用途。使用该数据集训练的模型不应用于研究目的以外的用途。











