
CLAP模型简介
CLAP(Contrastive Language-Audio Pretraining)是由LAION开源的一个对比语言-音频预训练模型。该模型借鉴了CLIP(Contrastive Language-Image Pretraining)的思想,通过大规模的音频-文本对数据进行预训练,学习音频和语言的联合表征。CLAP的出现为音频理解任务带来了新的范式,为音频分类、检索、生成等下游任务提供了强大的基础模型支持。
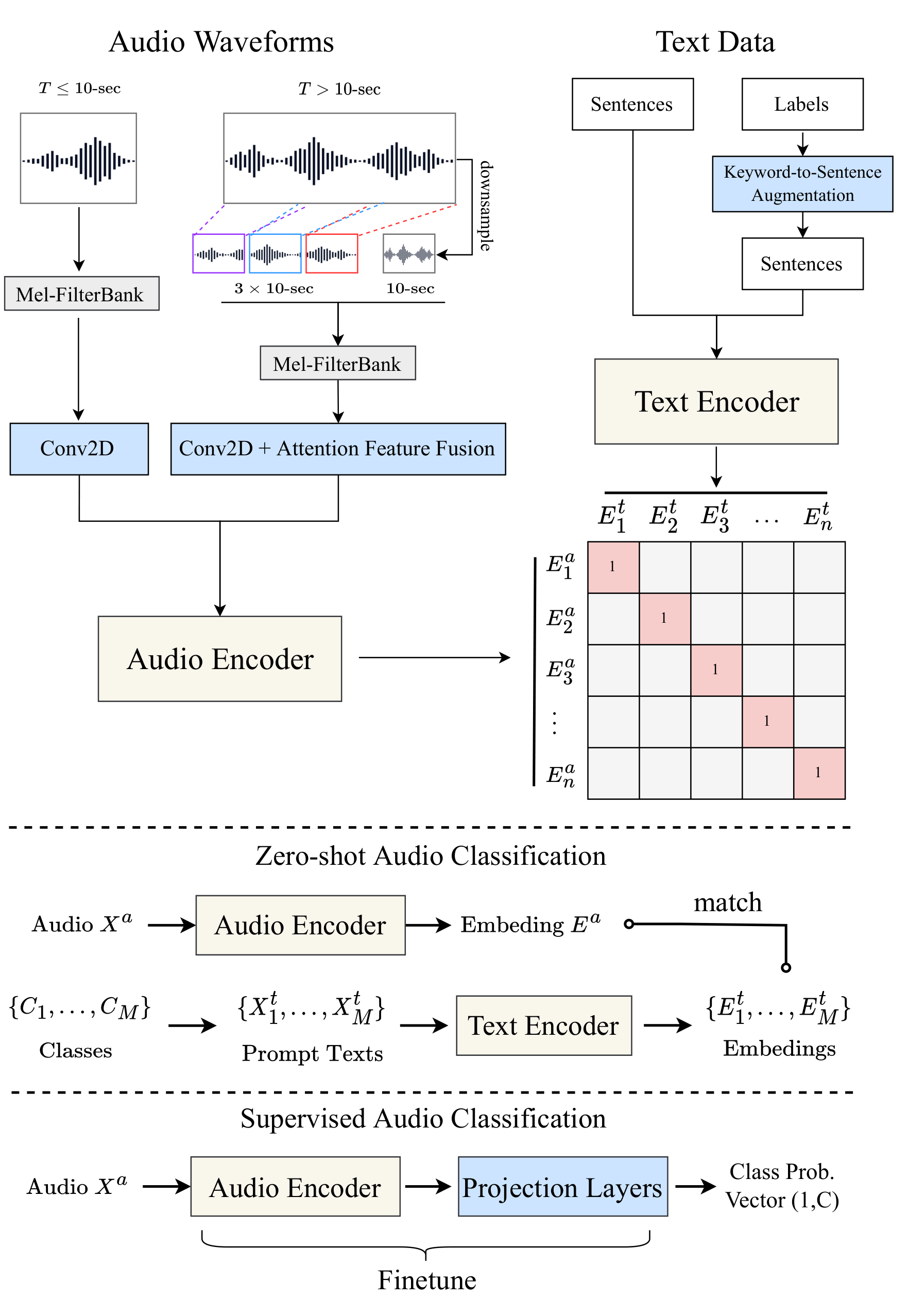
如上图所示,CLAP模型主要由音频编码器和文本编码器两部分组成。音频编码器负责将音频信号编码为固定维度的向量表示,文本编码器则将文本编码为相同维度的向量。在训练过程中,模型通过对比学习的方式,使得匹配的音频-文本对在向量空间中的距离更近,而不匹配的音频-文本对的距离则更远。这种训练方式使得模型能够学习到音频和语言之间的语义关联,从而为各种下游任务提供了良好的基础。
CLAP的关键特性
CLAP模型具有以下几个突出的特性:
-
大规模预训练:CLAP模型在包含630K音频-文本对的LAION-Audio-630K数据集上进行预训练,覆盖了广泛的音频类型和场景。
-
多模态融合:通过联合学习音频和文本表征,CLAP能够更好地理解音频内容的语义信息。
-
零样本迁移能力:预训练后的CLAP模型可以直接用于各种音频理解任务,无需在特定任务上fine-tuning。
-
灵活的架构:CLAP支持不同的音频编码器和文本编码器组合,可以根据具体需求进行选择和调整。
-
开源可用:CLAP模型及其训练代码已在GitHub上开源,便于研究者进行进一步的改进和应用。
CLAP的应用场景
CLAP模型为音频领域带来了新的可能性,其潜在的应用场景包括但不限于:
-
音频分类:利用CLAP的零样本能力,可以直接对未见过的音频类别进行分类。
-
音频-文本检索:可以根据文本描述检索相关的音频,或根据音频查找相关的文本描述。
-
音频标注:自动为音频生成文本描述或标签。
-
音频生成:结合生成模型,可以根据文本描述生成相应的音频内容。
-
跨模态学习:作为音频和文本之间的桥梁,为更复杂的跨模态任务提供基础。
CLAP的技术细节
模型架构
CLAP模型的核心是一个双塔结构,包括:
-
音频编码器:默认使用HTSAT(Hierarchical Token-Semantic Audio Transformer)作为音频编码器。HTSAT是一种层次化的音频Transformer模型,能够有效地处理不同长度的音频输入。
-
文本编码器:采用BERT或其变体作为文本编码器,将文本转换为固定维度的向量表示。
-
投影层:将音频和文本的特征映射到相同的潜在空间,便于计算相似度。
预训练方法
CLAP的预训练采用对比学习的方式:
-
数据准备:使用大规模的音频-文本对数据集,如LAION-Audio-630K。
-
批处理:每个批次包含N个音频-文本对。
-
特征提取:分别通过音频编码器和文本编码器提取特征。
-
相似度计算:计算批次内所有音频-文本对的相似度矩阵。
-
对比损失:使用InfoNCE损失函数,最大化匹配对的相似度,最小化不匹配对的相似度。
-
优化:使用Adam优化器进行模型参数更新。
模型变体
CLAP提供了多个预训练模型变体,以适应不同的应用场景:
- 基础版:适用于10秒以内的一般音频处理。
- 融合版:支持处理不定长音频。
- 音乐专用版:针对音乐任务优化。
- 音乐+语音版:同时支持音乐和语音处理。
- 通用版:涵盖音乐、语音和一般环境音。
用户可以根据具体需求选择合适的模型版本。
CLAP的使用方法
CLAP模型提供了简单易用的Python API,可以通过pip安装:
pip install laion-clap
使用示例:
import laion_clap
# 加载模型
model = laion_clap.CLAP_Module(enable_fusion=False)
model.load_ckpt()
# 获取音频嵌入
audio_files = ['sample1.wav', 'sample2.wav']
audio_embeds = model.get_audio_embedding_from_filelist(audio_files)
# 获取文本嵌入
texts = ["This is a dog barking", "This is a piano playing"]
text_embeds = model.get_text_embedding(texts)
# 计算相似度
similarity = audio_embeds @ text_embeds.T
这个简单的例子展示了如何使用CLAP模型获取音频和文本的嵌入表示,并计算它们之间的相似度。
CLAP的性能评估
CLAP模型在多个音频理解任务上展现出了优秀的性能。以ESC-50(Environmental Sound Classification)数据集为例,CLAP在零样本设置下的分类准确率达到了90%以上,这一结果远超传统的有监督学习方法。
在音频-文本检索任务中,CLAP同样表现出色。在AudioCaps和Clotho等数据集上,CLAP在Recall@10和mAP@10等指标上都取得了很高的分数,证明了其强大的跨模态理解能力。
CLAP的未来发展
尽管CLAP已经展现出了强大的能力,但仍有很多值得探索的方向:
- 进一步扩大预训练数据规模,提升模型的泛化能力。
- 探索更高效的模型架构,减少计算资源需求。
- 结合其他模态(如图像),实现更全面的多模态理解。
- 针对特定领域(如医疗、安防)进行优化,开发专用模型。
- 研究模型的可解释性,理解CLAP是如何学习音频-文本关联的。
结语
CLAP模型的出现为音频理解领域带来了新的机遇和挑战。它不仅提供了一种强大的预训练模型,还开启了音频-文本跨模态学习的新范式。随着研究的深入和应用的拓展,我们有理由相信CLAP及其衍生技术将在音频分析、多模态交互等领域发挥越来越重要的作用。
作为一个开源项目,CLAP的发展离不开社区的贡献。研究者和开发者可以通过以下方式参与到CLAP的改进中来:
- 在GitHub上提交issues或pull requests。
- 贡献新的预训练数据集或评估基准。
- 开发基于CLAP的创新应用,并分享使用经验。
- 参与LAION社区的讨论,提出新的想法和建议。
让我们共同期待CLAP模型在音频智能领域带来更多的突破和创新!
参考资源
- CLAP GitHub仓库: https://github.com/LAION-AI/CLAP
- LAION-Audio-630K数据集: https://github.com/LAION-AI/audio-dataset/tree/main/laion-audio-630k
- CLAP论文: Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
通过本文的介绍,我们深入了解了CLAP模型的原理、特性和应用。作为一个强大的音频-文本预训练模型,CLAP为音频理解和跨模态学习开辟了新的道路。随着技术的不断进步和应用场景的拓展,我们有理由相信CLAP将在音频智能领域发挥越来越重要的作用。











