
Comprehensive-Transformer-TTS学习资料汇总
Comprehensive-Transformer-TTS是一个基于非自回归Transformer的文本转语音(TTS)项目,旨在实现最先进的TTS技术。该项目支持多种Transformer模型和有监督/无监督的时长建模方法,为研究人员和开发者提供了一个全面的TTS实验平台。本文将介绍该项目的相关学习资料,帮助读者快速上手使用。
项目简介
Comprehensive-Transformer-TTS是由GitHub用户keonlee9420开发的开源项目,主要特点包括:
- 基于非自回归Transformer架构,训练和推理速度快
- 支持多种先进的Transformer模型,如Fastformer、Long-Short Transformer等
- 实现了有监督和无监督的时长建模方法
- 支持单说话人和多说话人TTS
- 提供了详细的训练和推理指南
项目地址: https://github.com/keonlee9420/Comprehensive-Transformer-TTS
相关论文
该项目实现了多篇重要的TTS相关论文,包括:
- Fastformer: Additive Attention Can Be All You Need
- Long-Short Transformer: Efficient Transformers for Language and Vision
- FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
- One TTS Alignment To Rule Them All
阅读这些论文可以帮助读者深入理解项目的技术原理。
安装与使用
- 克隆项目并安装依赖:
git clone https://github.com/keonlee9420/Comprehensive-Transformer-TTS.git
cd Comprehensive-Transformer-TTS
pip install -r requirements.txt
- 下载预训练模型:
项目提供了在LJSpeech和VCTK数据集上训练的预训练模型,下载后放入output/ckpt/DATASET/目录。
- 运行推理:
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
更多详细用法请参考项目README。
数据集
项目支持以下数据集:
也可以按照项目说明添加自定义数据集。
模型训练
训练新模型的步骤:
- 准备数据集
- 修改配置文件
- 运行预处理脚本
- 训练对齐模型(可选)
- 训练TTS模型
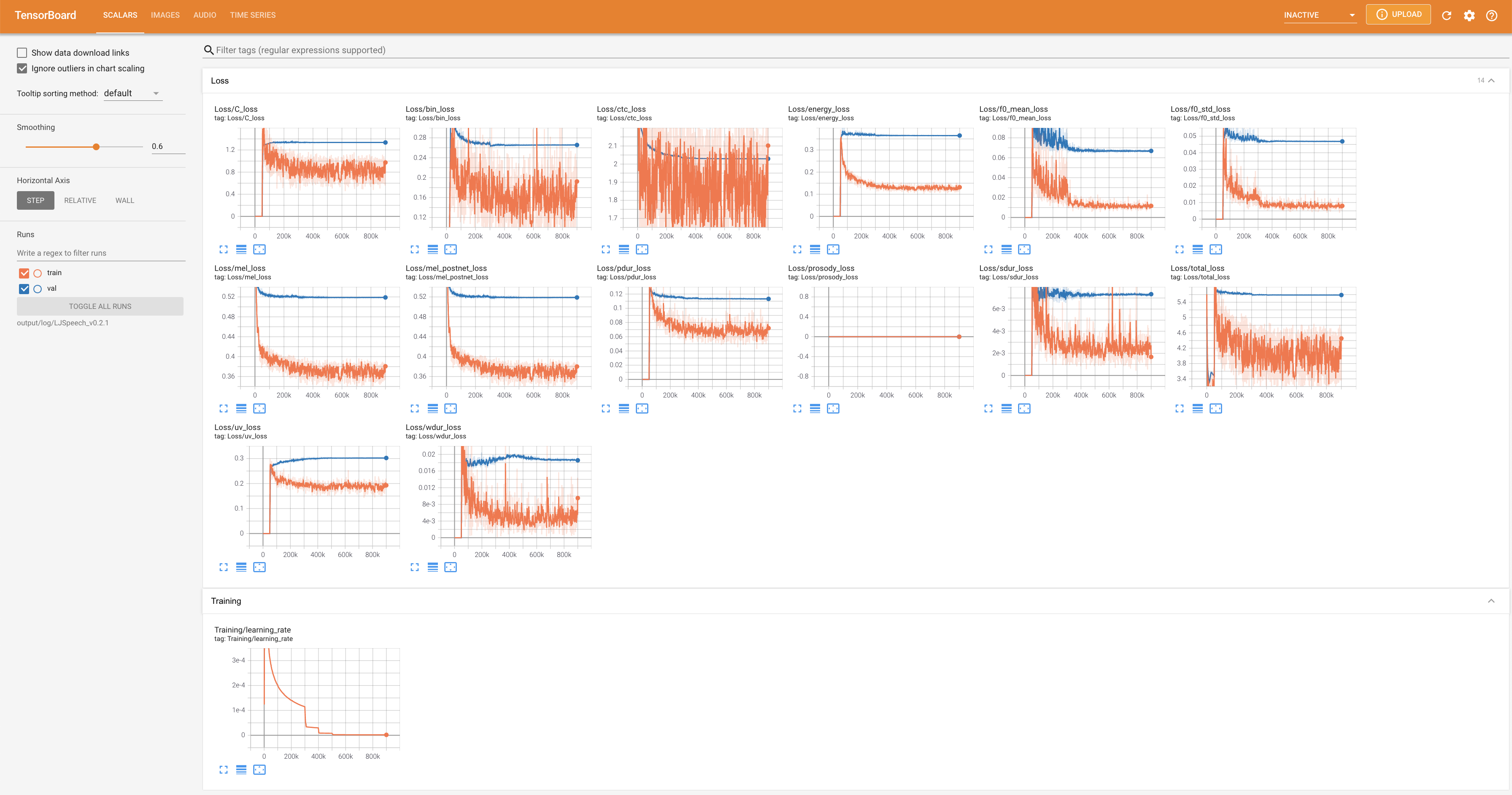
详细的训练流程请参考项目文档。
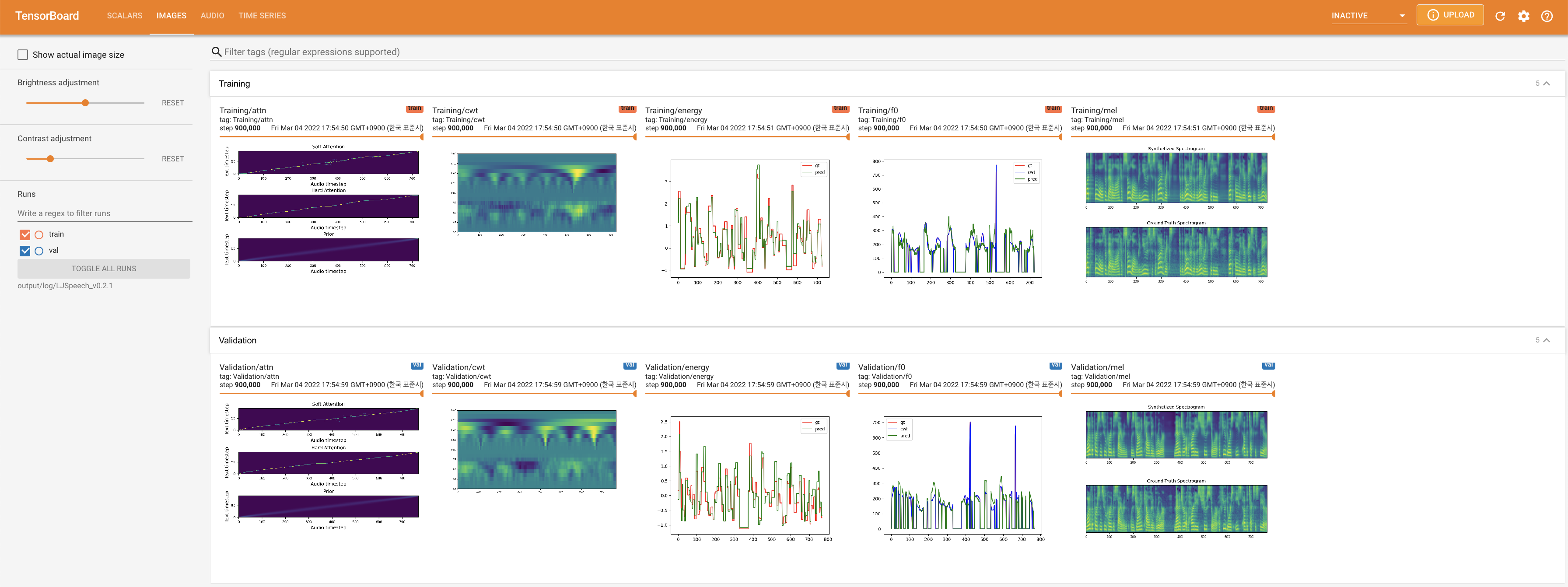
社区资源
总结
Comprehensive-Transformer-TTS为TTS研究提供了一个强大而灵活的框架。通过本文介绍的学习资料,相信读者可以快速上手使用该项目,并在此基础上进行更深入的TTS技术探索。欢迎对项目提出建议,共同推动TTS技术的发展!


















