
日本语言模型(LLM)的蓬勃发展
近年来,随着人工智能技术的快速进步,大型语言模型(Large Language Model, LLM)在自然语言处理领域取得了突破性进展。作为全球第三大经济体和科技强国,日本在LLM领域也不甘落后,多个研究机构和企业纷纷投入资源开发适合日语的大型语言模型。本文将全面介绍日本语言模型的发展现状,包括各类模型的特点、应用场景及评估基准,并对未来发展趋势进行展望。
日本语言模型的分类
根据训练方式的不同,日本语言模型可以大致分为以下几类:
-
从头训练的模型:这类模型完全使用日语语料从头进行预训练,代表模型包括LLM-jp、PLaMo等。
-
在英语模型基础上继续预训练的模型:这类模型以英语LLM为基础,使用日语语料进行继续预训练,如Rinna等。
-
仅进行指令微调的模型:这类模型直接在英语LLM上使用日语指令数据进行微调,如OpenCALM等。
-
多模型融合的模型:将多个LLM进行融合得到的模型,如Megumi等。
-
以API形式提供的模型:一些公司提供基于自有LLM的API服务,如LINE等。
代表性模型介绍
1. LLM-jp系列
LLM-jp是由日本国立情报学研究所(NII)主导开发的开源日语大型语言模型。其最新版本LLM-jp-13B v2.0于2024年4月发布,采用Llama架构,参数规模为130亿。该模型在2万亿个日语token上进行了预训练,并使用多个指令数据集进行了微调。LLM-jp系列模型在多项日语NLP任务上表现出色,是目前最具代表性的日语开源LLM之一。
2. PLaMo系列
PLaMo是由Preferred Networks公司开发的日语大型语言模型。其最新版本PLaMo-13B同样采用Llama架构,参数规模为130亿。该模型在1.5万亿个多语言token上进行了预训练,其中包含大量日语语料。PLaMo-13B在多项日语基准测试中表现优异,特别是在长文本理解方面具有优势。
3. Stockmark-100b
Stockmark-100b是由Stockmark公司开发的超大规模日语语言模型,参数规模高达1000亿,是目前公开的最大日语LLM。该模型在9100亿个token上进行了预训练,包括多种日语语料。尽管参数规模庞大,但Stockmark-100b采用了高效的训练策略,使其能够在有限的计算资源下完成训练。
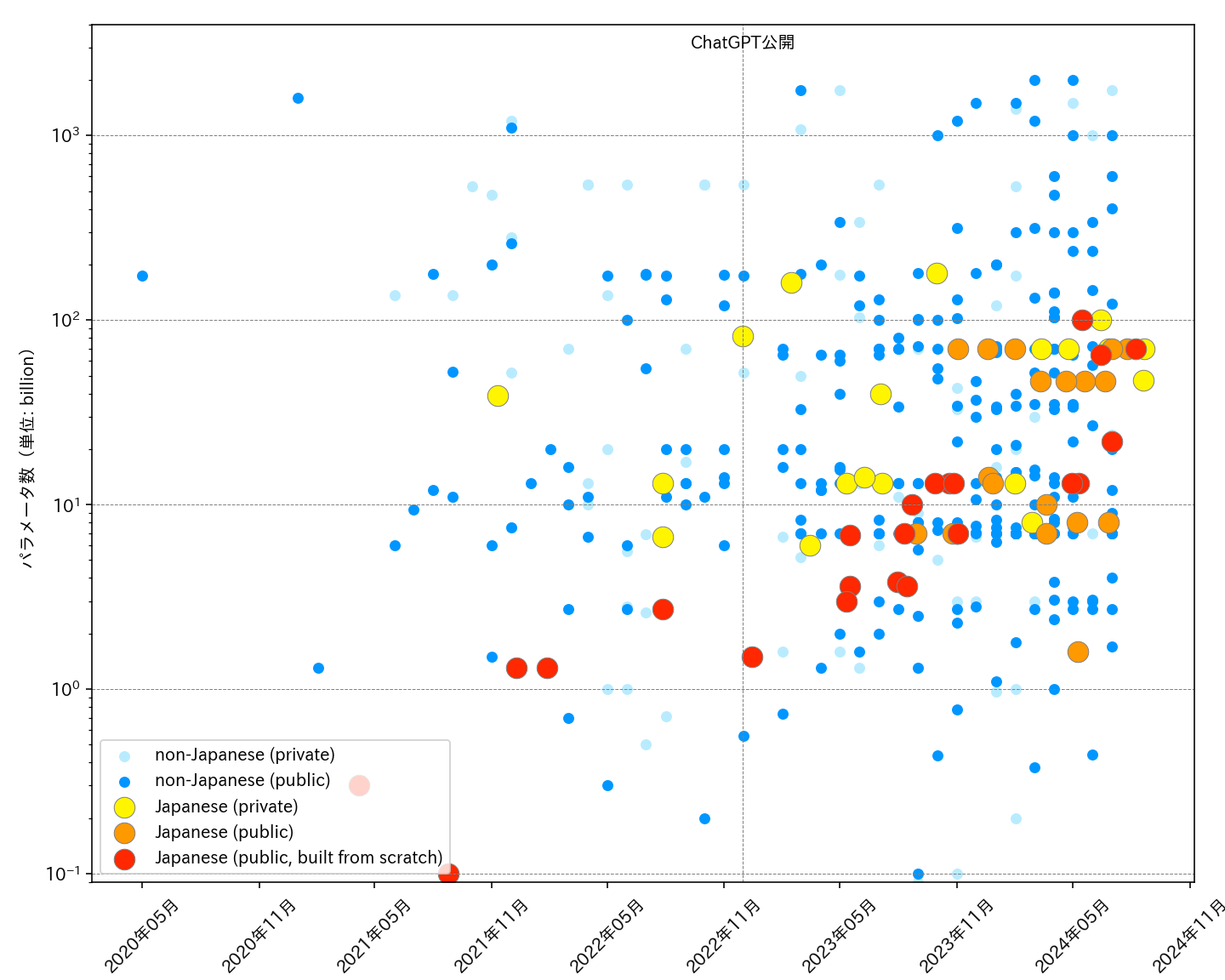
日语LLM的应用场景
日语LLM在多个领域展现出巨大的应用潜力:
-
智能客服:能够理解复杂的用户询问并给出准确回复,提高客户服务效率。
-
内容创作:协助撰写文章、报告、广告文案等,提高创作效率。
-
代码生成:根据自然语言描述生成日语注释的代码,提高开发效率。
-
教育辅助:为学生提供个性化的学习辅导和答疑。
-
医疗诊断:辅助医生进行初步诊断,提供参考意见。
-
法律咨询:解答基本法律问题,协助律师进行案件分析。
日语LLM评估基准
为了客观评估日语LLM的性能,研究人员开发了多种评估基准:
-
JGLUE:日语通用语言理解评估基准,包含多个NLU任务。
-
JCommonsenseQA:测评模型的日语常识推理能力。
-
JNLI:日语自然语言推理数据集,评估模型的逻辑推理能力。
-
JCoLA:日语语言可接受性判断数据集,测试模型对语法的理解。
-
JFEVER:日语事实验证数据集,评估模型的事实核查能力。
这些评估基准从不同角度对日语LLM的能力进行全面测试,为模型的改进提供了重要参考。
日语LLM的未来展望
尽管日语LLM取得了显著进展,但仍面临一些挑战和机遇:
-
参数规模进一步扩大:随着计算资源的增加,预计将出现更大规模的日语LLM。
-
多模态融合:结合图像、音频等多模态信息,提升模型的理解和生成能力。
-
领域适应:针对特定领域进行微调,开发更多垂直领域应用。
-
伦理和安全:加强模型的事实性、安全性和公平性,减少有害输出。
-
效率优化:探索更高效的训练和推理方法,降低资源消耗。
-
跨语言能力:增强日语LLM的多语言处理能力,促进国际交流。
总的来说,日语LLM的发展正处于蓬勃上升期。随着技术的不断进步和应用场景的拓展,日语LLM有望在推动日本AI产业发展、提升社会生产效率等方面发挥越来越重要的作用。研究人员、企业和政府需要携手合作,共同推动日语LLM的创新与应用,为日本的AI事业贡献力量。










