DA-CLIP:开创视觉语言模型在图像恢复领域的新范式
在计算机视觉和自然语言处理的交叉领域,视觉语言模型(Vision-Language Models, VLMs)近年来取得了巨大的进展。其中,CLIP(Contrastive Language-Image Pre-training)模型因其强大的零样本学习和跨模态理解能力而备受关注。然而,当面对低层视觉任务,特别是图像恢复这类挑战性任务时,CLIP等传统VLMs的表现却不尽如人意。这主要是因为这些模型在处理退化图像时,其性能会大幅下降。
为了解决这一问题,来自瑞典乌普萨拉大学信息技术系的研究团队提出了一种创新的方法 - DA-CLIP(Degradation-Aware CLIP)。这项研究不仅在学术界引起了广泛关注,还在2024年的国际学习表示会议(ICLR)上获得了认可。DA-CLIP的核心思想是通过引入一个可训练的控制器,来适应固定的CLIP图像编码器,使其能够更好地处理退化图像,从而在图像恢复任务中发挥出色的性能。
DA-CLIP的创新设计
DA-CLIP的设计巧妙地保留了CLIP模型的文本和图像编码器,同时引入了一个创新的图像控制器。这个控制器通过对比学习的方式进行训练,能够准确预测图像的退化特征,并引导图像编码器输出高质量的内容特征。这种设计使得DA-CLIP能够同时处理图像退化分类和图像恢复两个任务,实现了多任务学习的目标。
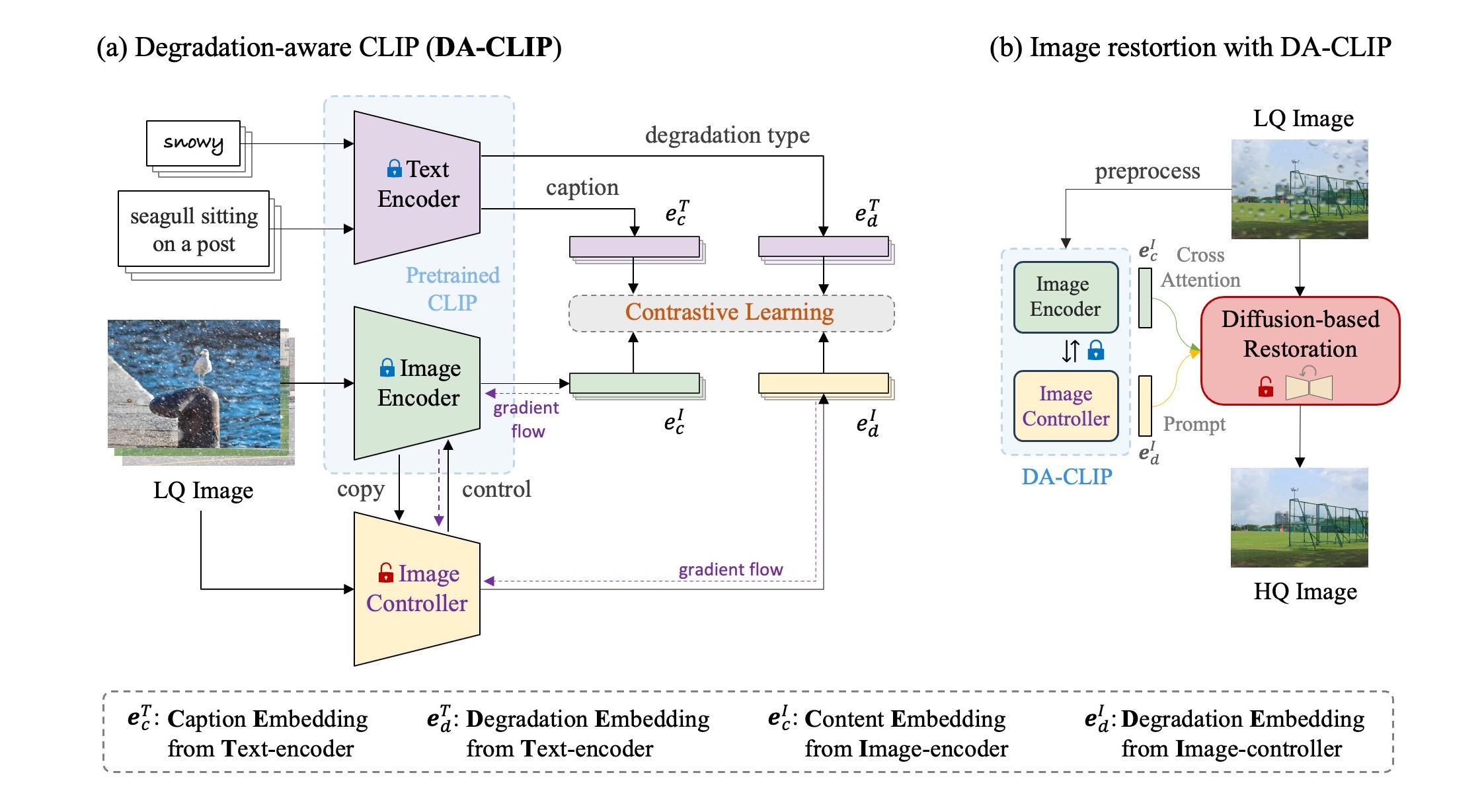
如上图所示,DA-CLIP的整体框架包括以下几个关键组件:
-
预训练CLIP模型: 保持文本和图像编码器不变,为后续任务提供基础特征提取能力。
-
图像控制器: 通过可训练的控制器来适应固定的图像编码器,使其能够更好地处理退化图像。
-
退化特征预测: 控制器能够准确预测图像的退化特征,为后续的图像恢复任务提供重要信息。
-
高质量内容特征: 通过控制器的引导,图像编码器能够输出更适合图像恢复任务的高质量内容特征。
-
多任务学习: DA-CLIP通过整合退化分类和图像恢复任务,实现了多任务学习的目标。
控制器设计的精妙之处
DA-CLIP的控制器设计是其成功的关键。研究团队采用了基于ViT(Vision Transformer)的图像编码器,并通过密集连接层将控制器与图像编码器相连。这些连接层初始化为零,允许模型在训练过程中逐步学习最优的控制策略。
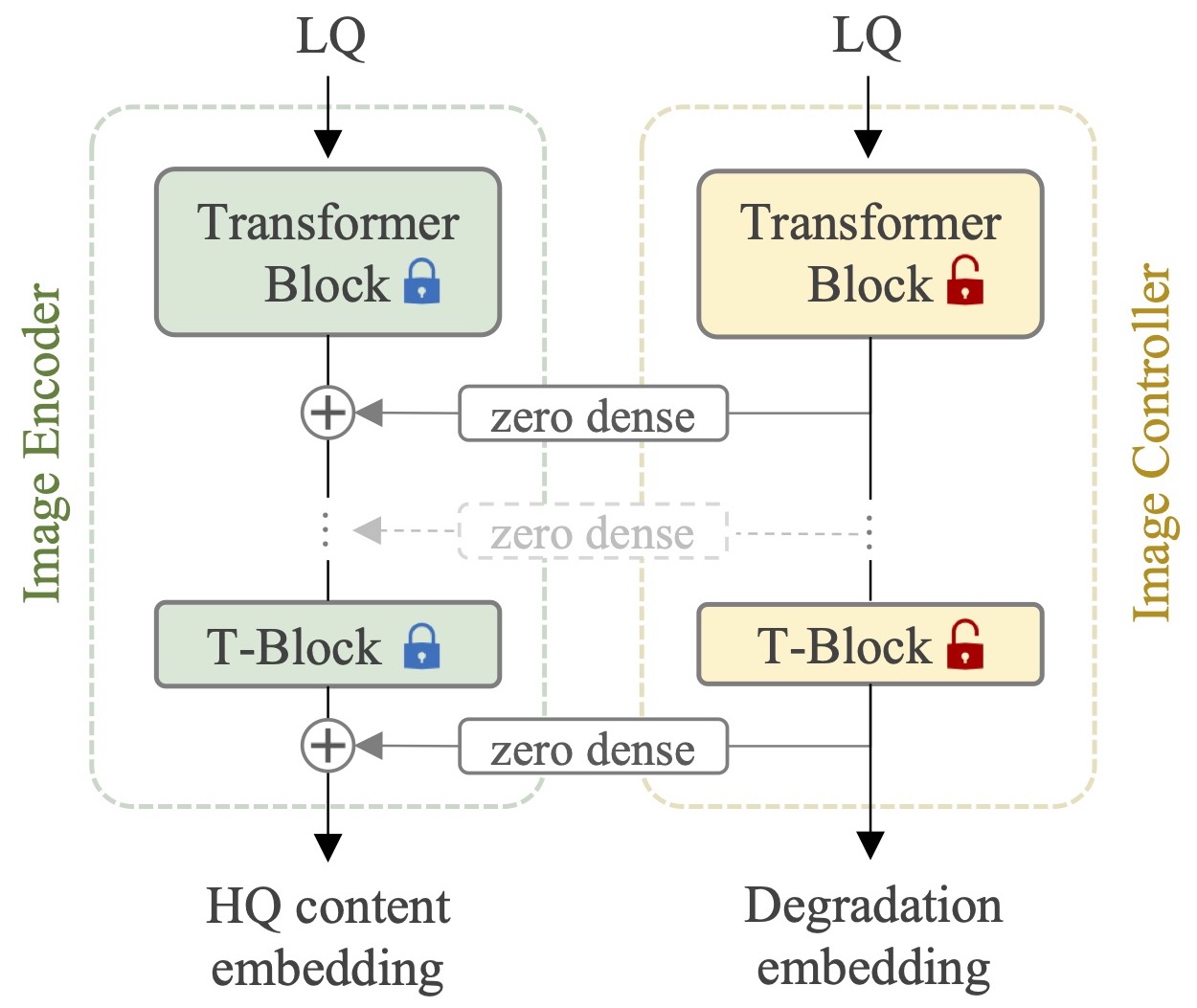
控制器的主要功能包括:
-
退化特征预测: 通过分析输入图像,控制器能够准确预测图像的退化类型和程度。
-
图像编码器调控: 控制器通过学习到的参数,引导图像编码器生成更适合图像恢复任务的特征表示。
-
多尺度特征融合: 控制器能够整合不同层级的特征,提供更全面的图像表示。
提示学习模块的创新
为了进一步提高DA-CLIP在统一图像恢复任务中的性能,研究团队引入了提示学习模块。这个模块利用控制器预测的退化嵌入来学习任务相关的提示,从而增强了模型在退化分类任务上的表现。
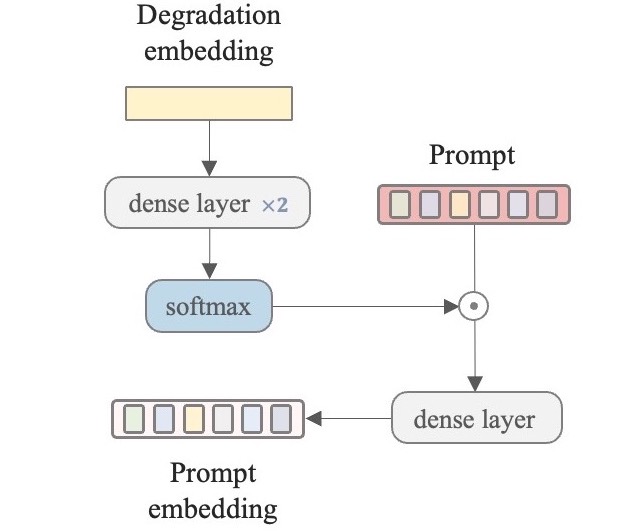
提示学习模块的主要特点包括:
-
退化嵌入利用: 直接利用控制器预测的退化嵌入作为提示学习的输入。
-
任务特定提示: 学习到的提示能够针对不同的退化类型提供特定的信息。
-
分类性能提升: 通过提示学习,模型在退化分类任务上的表现得到显著提升。
创新的数据生成策略
为了训练DA-CLIP模型,研究团队采用了一种创新的数据生成策略。他们利用BLIP(Bootstrapped Language-Image Pre-training)框架为所有高质量图像生成合成字幕。这种方法的优势在于,生成的字幕准确且不包含退化信息,为后续的图像-文本-退化三元组构建提供了理想的基础。
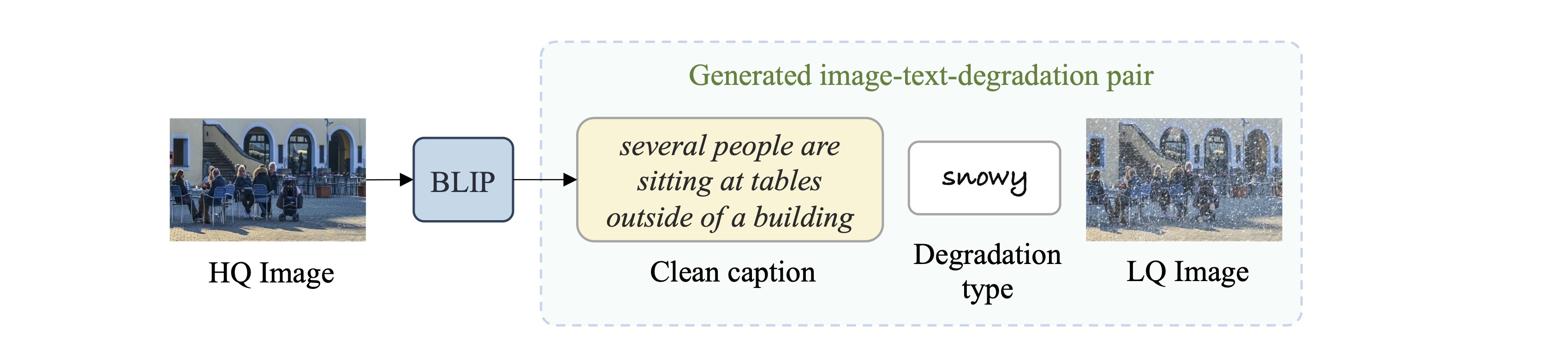
数据生成策略的主要步骤包括:
-
高质量图像字幕生成: 利用BLIP为清晰图像生成准确的描述性字幕。
-
退化图像生成: 对原始高质量图像应用不同类型的退化处理。
-
三元组构建: 将生成的字幕、退化图像和对应的退化类型组合成训练所需的三元组。
DA-CLIP的卓越性能
DA-CLIP在多项图像恢复任务中展现出了优异的性能。无论是在特定退化类型的图像恢复还是统一图像恢复任务中,DA-CLIP都取得了令人瞩目的成果。
在特定退化类型的图像恢复任务中,DA-CLIP在多个数据集上的表现如下图所示:

从上图可以看出,DA-CLIP在处理运动模糊、雾霾、JPEG压缩等多种退化类型时,都能有效地恢复图像质量,展现出强大的通用性。
在统一图像恢复任务中,DA-CLIP同样表现出色:
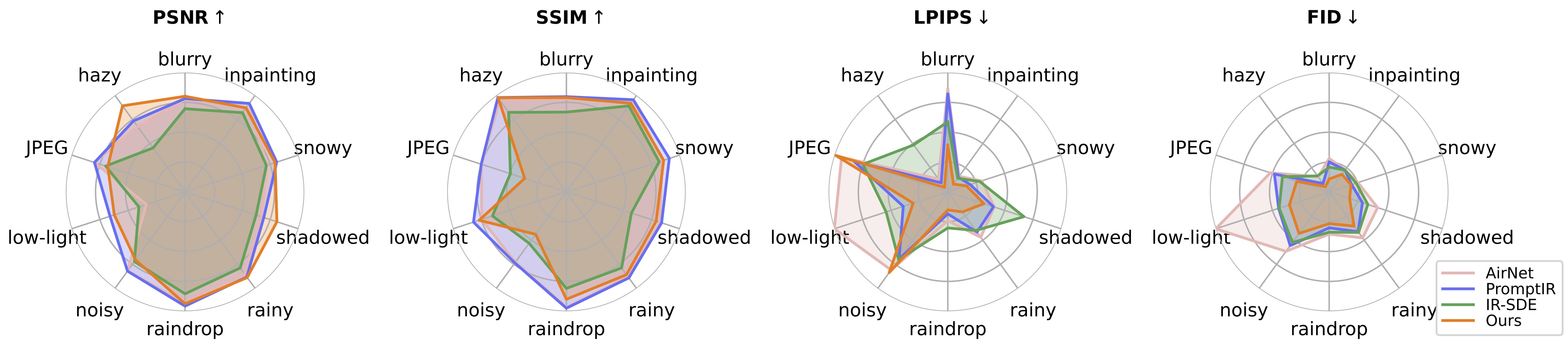
上图展示了DA-CLIP在多个评估指标上的表现,与其他先进方法相比,DA-CLIP在大多数指标上都取得了最佳或接近最佳的结果。
DA-CLIP的实际应用
DA-CLIP不仅在学术研究中表现出色,还展现了巨大的实际应用潜力。研究团队提供了多种方式供研究者和开发者使用DA-CLIP:
-
在线演示: 通过Hugging Face Spaces提供的在线演示,用户可以直接上传图像进行处理,体验DA-CLIP的强大功能。
-
Google Colab: 研究团队提供了Colab笔记本,允许用户在云端环境中运行DA-CLIP。
-
Replicate API: 通过Replicate平台,开发者可以轻松将DA-CLIP集成到自己的应用中。
-
本地部署: 研究团队在GitHub仓库中提供了完整的源代码和预训练模型,方便研究者进行本地部署和进一步研究。
未来展望与挑战
尽管DA-CLIP在图像恢复领域取得了显著成果,研究团队也坦承当前模型仍存在一些局限性:
-
真实世界图像处理: 当前模型在处理一些真实世界的图像时可能会遇到困难,特别是那些与训练数据集分布存在较大差异的图像。
-
图像尺寸敏感性: 直接调整输入图像的大小可能会导致大多数任务的性能下降。
-
修复任务局限性: 目前的模型在图像修复任务中仅支持面部修复,这主要是由于数据集的限制。
针对这些挑战,研究团队提出了几个未来研究方向:
-
扩大训练数据集: 收集更多样化的真实世界图像数据,提高模型的泛化能力。
-
改进图像预处理: 探索更适合的图像预处理方法,以适应不同尺寸和分辨率的输入图像。
-
扩展修复能力: 扩大修复任务的范围,使模型能够处理更多类型的图像修复任务。
-
结合最新AI技术: 探索将DA-CLIP与其他先进AI技术(如大型语言模型)结合,进一步提升模型的性能和应用范围。
结语
DA-CLIP的提出和成功实现,标志着视觉语言模型在低层视觉任务中应用的一个重要突破。它不仅展示了将预训练视觉语言模型迁移到图像恢复任务的可能性,还为多任务学习和跨模态理解开辟了新的研究方向。随着技术的不断发展和完善,我们有理由相信,DA-CLIP及其衍生技术将在计算机视觉、图像处理等领域发挥越来越重要的作用,为创造更智能、更高效的视觉系统贡献力量。
作为该领域的研究者和开发者,我们应该密切关注DA-CLIP的后续发展,积极参与到相关研究和应用中来。通过不断探索和创新,我们有望在不久的将来见证更多令人兴奋的突破,推动计算机视觉技术向更高水平迈进。









