
DashInfer: 为大语言模型打造的高性能推理引擎
在人工智能和自然语言处理领域,大语言模型(Large Language Models, LLMs)的发展日新月异。然而,如何高效地部署和推理这些模型一直是一个挑战。为了解决这个问题,ModelScope团队开发了DashInfer - 一个专为LLM推理优化的高性能原生引擎。本文将深入介绍DashInfer的特性、架构以及它如何在各种硬件平台上实现卓越的性能。
DashInfer的核心特性
DashInfer是用C++编写的运行时,旨在为各种硬件架构(包括x86和ARMv9)提供高度优化的实现。它的主要特性包括:
-
轻量级架构: DashInfer对第三方依赖要求极低,并使用静态链接依赖库。它提供C++和Python接口,可以轻松集成到现有系统中。
-
高精度: 经过严格测试,DashInfer能够提供与PyTorch和其他GPU引擎(如vLLM)一致的推理精度。
-
标准LLM推理技术: DashInfer采用了连续批处理(Continuous Batching)等标准LLM推理技术,支持即时插入新请求和流式输出。
-
灵活的请求控制: 提供基于请求的异步接口,允许对每个请求的生成参数和状态进行单独控制。
-
广泛的模型支持: 支持主流开源LLM,如Qwen、LLaMA、ChatGLM等,可加载Huggingface格式的模型。
-
即时量化(InstantQuant): 使用DashInfer的InstantQuant(IQ)技术,可以实现无需微调的权重量化加速,提高部署效率。目前支持ARM CPU上的权重8位量化。
-
优化的计算内核: 通过OneDNN和自研汇编内核,DashInfer能够在ARM和x86上最大化硬件性能。
-
Flash Attention支持: 显著加速长序列的注意力计算,大幅降低首token延迟。
-
NUMA感知设计: 支持跨多个NUMA节点的张量并行推理,充分利用服务器CPU的计算能力。
-
长上下文支持: 当前版本支持高达32k的上下文长度,未来计划扩展到更长的上下文。
-
多语言API接口: 支持C++和Python接口,可以通过标准跨语言接口扩展到Java、Rust等其他编程语言。
-
广泛的操作系统支持: 支持主流Linux服务器操作系统如Centos7和Ubuntu22.04,并提供相应的Docker镜像。
DashInfer的软件架构
DashInfer的软件架构设计得非常精巧,主要包括两个阶段:模型加载和序列化、模型推理。
-
模型加载和序列化:
- 通过Python接口加载模型权重、设置转换参数和量化设置。
- 将模型序列化并转换为DashInfer格式(.dimodel, .ditensors)。
- 这一步依赖PyTorch和transformers库来访问权重。
-
模型推理:
- 使用序列化后的DashInfer格式模型执行推理。
- 不依赖PyTorch等组件,可独立运行。
- 使用DLPack格式张量与外部框架(如PyTorch)交互。
- C++接口通过静态链接大部分依赖,主要依赖OpenMP运行时库和C++系统库。
DashInfer支持单NUMA和多NUMA两种架构:
-
单NUMA架构:
- 使用多线程和线程池进行调度。
- 通过
StartRequest传入输入token和生成参数来发起推理请求。 - 返回
ResultQueue用于获取输出token和生成状态,支持异步操作。 - 提供
RequestHandle用于管理请求,支持同步、停止和释放等操作。
-
多NUMA架构:
- 采用多进程客户端-服务器架构实现张量并行模型推理。
- 每个NUMA节点上运行独立进程,处理部分张量并行推理。
- 进程间使用OpenMPI协作。
- 客户端通过gRPC与服务器交互,提供统一的外部接口。
DashInfer的性能表现
DashInfer在各种硬件平台上都展现出了卓越的性能。以下是一些性能测试结果:
-
推理精度:
- 在MMLU、C-Eval、GSM8K和HumanEval等多个基准测试上,DashInfer的A16W8(8位量化)模型与transformers的BF16模型性能相当,甚至在某些测试中略有超越。
-
吞吐量和延迟:
- 在x86平台上,DashInfer在多种模型尺寸(1.8B到14B参数)和批处理大小下都表现出色。
- 在ARM平台上,DashInfer的8位量化模型展现出显著的性能提升。
-
多NUMA扩展性:
- DashInfer展示了良好的多NUMA扩展性,能够有效利用多节点CPU的计算能力。
DashInfer的应用场景
DashInfer的高性能和灵活性使其适用于多种应用场景:
-
边缘计算: 凭借其轻量级架构和对ARM平台的优化,DashInfer非常适合在资源受限的边缘设备上部署LLM。
-
企业级服务器部署: 支持多NUMA架构,能够充分利用高端服务器的计算能力,适合大规模LLM服务部署。
-
实时对话系统: 连续批处理和流式输出支持使DashInfer成为构建实时对话系统的理想选择。
-
AI助手集成: 易于集成的特性使DashInfer可以轻松嵌入到各种应用中,为AI助手提供强大的推理能力。
-
定制化LLM服务: 支持多种开源模型,可以根据特定需求选择和部署合适的模型。
未来展望
DashInfer团队对该项目的未来发展有着明确的规划:
- 加速Flash-Attention以进一步提升性能。
- 扩展上下文长度至32k以上,以支持更长的对话和文档处理。
- 支持4位量化,进一步压缩模型大小和提高推理速度。
- 支持使用GPTQ微调的量化模型。
- 支持MoE(Mixture of Experts)架构,以适应更复杂的模型结构。
结语
DashInfer作为一个高性能的原生LLM推理引擎,展现了强大的性能和灵活性。它不仅在各种硬件平台上实现了卓越的推理速度,还提供了丰富的功能和易用的接口。随着AI技术的不断发展,DashInfer无疑将在大语言模型的实际应用中发挥越来越重要的作用,为AI应用的落地提供强有力的支持。
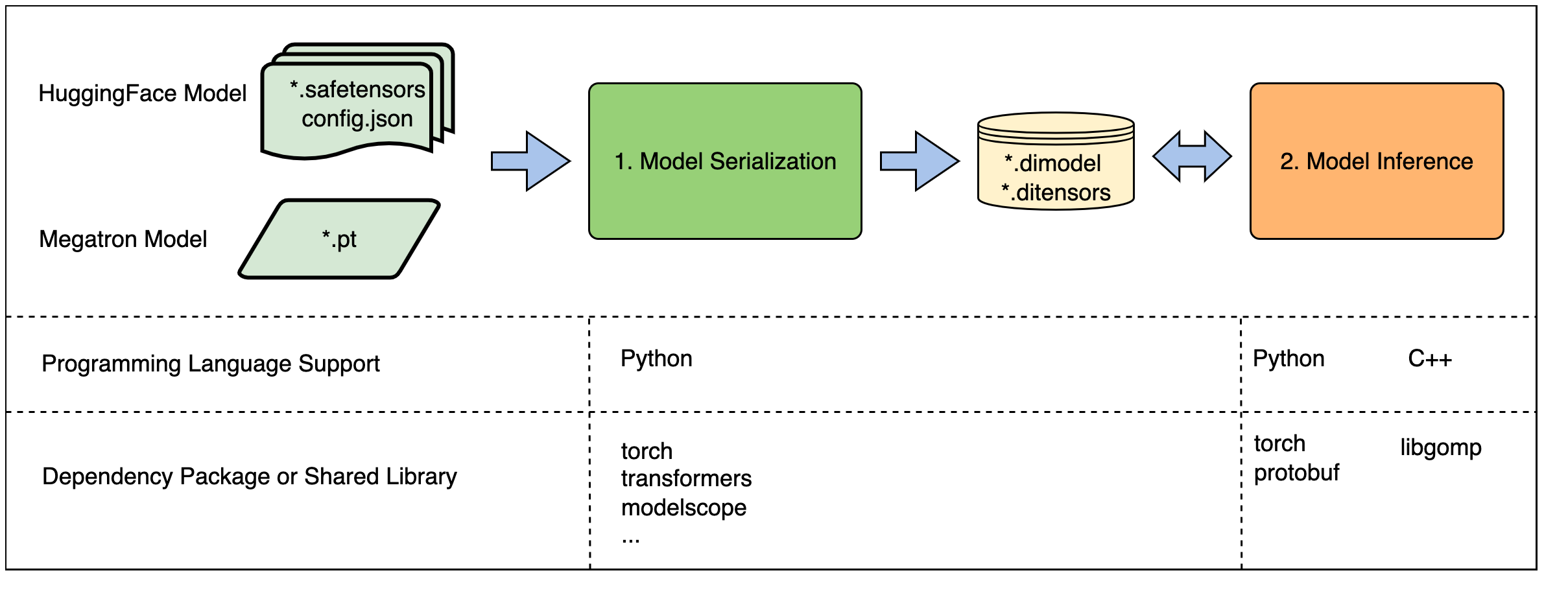
DashInfer的工作流程和依赖关系如上图所示。它清晰地展示了从模型加载到推理的整个过程,以及各个组件之间的交互。这种设计不仅保证了高效的推理性能,还提供了灵活的扩展性,使DashInfer能够适应各种复杂的应用场景。
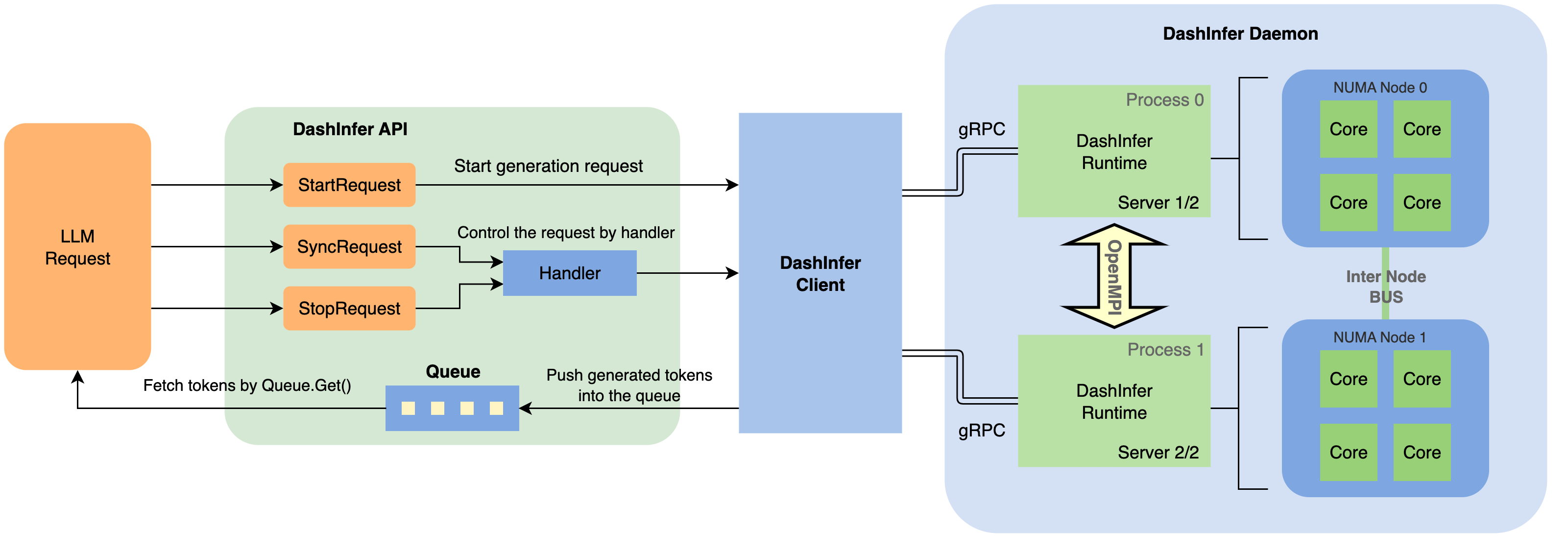
多NUMA架构是DashInfer的一大亮点,如上图所示。这种设计充分利用了现代服务器的多核心多节点特性,通过精确控制线程的CPU亲和性,避免了远程内存节点访问导致的性能下降。这使得DashInfer能够在大规模服务器上实现卓越的性能表现,为企业级LLM部署提供了理想的解决方案。
总的来说,DashInfer为大语言模型的高效推理提供了一个强大而灵活的平台。无论是在边缘设备还是高性能服务器上,DashInfer都能充分发挥硬件潜力,为各种AI应用场景提供强大的支持。随着持续的开发和优化,我们可以期待DashInfer在未来为更多创新AI应用赋能,推动大语言模型技术的广泛应用和发展。









