
DBRX简介
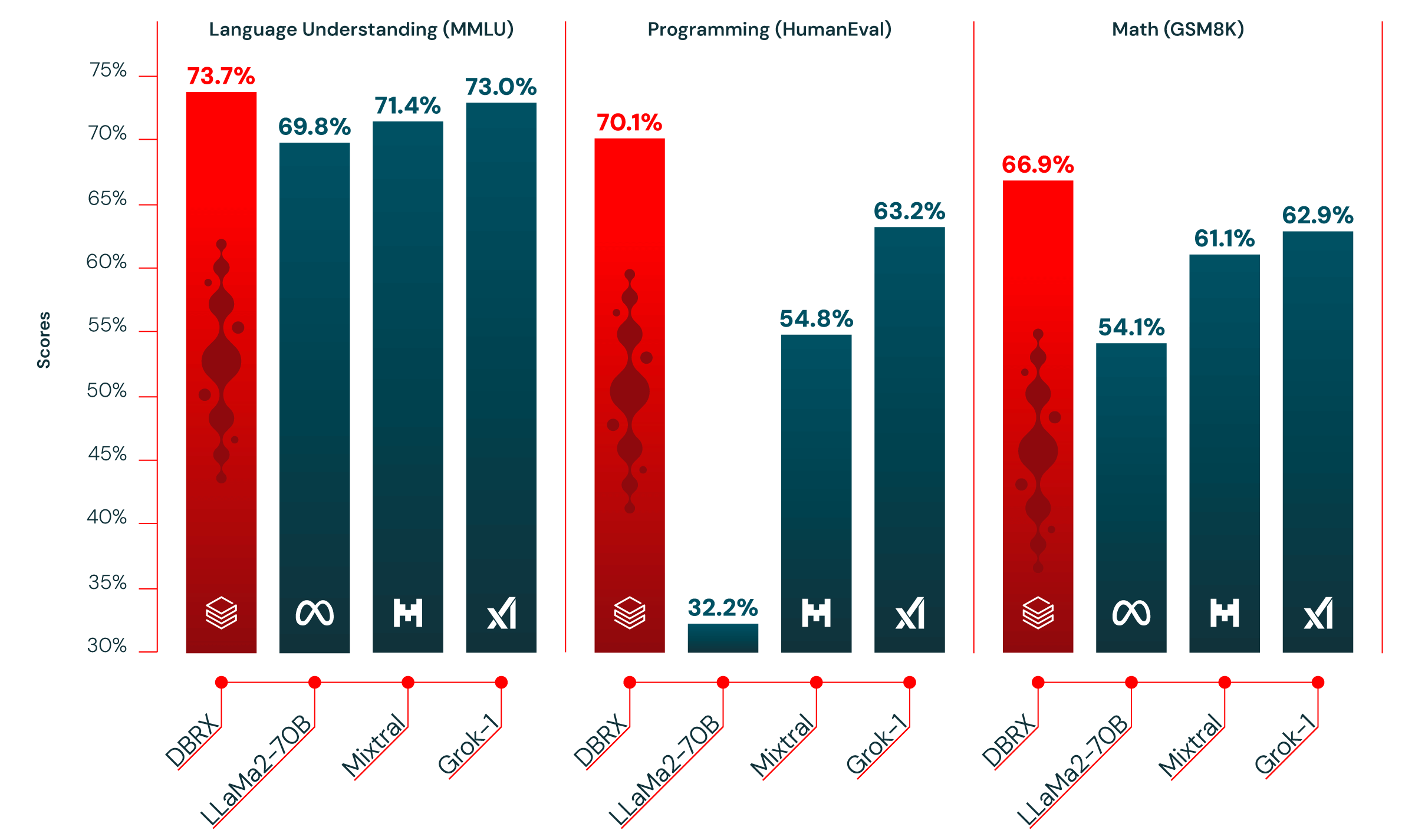
DBRX是Databricks公司开发并开源的大型语言模型(LLM),采用混合专家(MoE)架构,总参数量达132B,具有强大的自然语言处理和代码生成能力。DBRX在多项基准测试中超越了其他知名开源模型如LLaMA 2和Mistral,成为目前最强大的开源LLM之一。
官方资源
- GitHub代码仓库: 包含推理代码、示例和使用说明
- Hugging Face模型页面: 提供模型下载和在线体验
- DBRX技术博客: 详细介绍模型架构和性能
- Founder's Blog: 介绍开源DBRX的愿景
快速上手
- 访问Hugging Face页面并接受许可协议
- 安装依赖:
pip install -r requirements.txt
- 下载模型并运行:
huggingface-cli login
python generate.py
详细使用说明请参考GitHub README。
模型详情
- 总参数量: 132B
- 活跃参数: 36B (4/16专家激活)
- 训练数据: 12T tokens
- 上下文长度: 32K tokens
- 开源版本:
- DBRX Base: 预训练基础模型
- DBRX Instruct: 指令微调版本
推理加速
DBRX支持多种推理优化方案:
- TensorRT-LLM: 正在添加支持
- vLLM: 参考vLLM文档
- MLX: 适用于Apple M系列芯片
- LLama.cpp: 支持量化版本
模型微调
DBRX提供两种微调方式:
- 全参数微调: dbrx-full-ft.yaml
- LoRA微调: dbrx-lora-ft.yaml
微调指南见LLM Foundry文档。
集成与应用
DBRX已集成到多个平台:
- Databricks平台
- You.com
- Perplexity Labs
- LlamaIndex
社区交流
- 模型问题讨论: Hugging Face社区论坛
- 训练库问题: 在相应GitHub仓库提issue
DBRX作为最新的开源大模型,为AI研究和应用带来了新的可能。无论是学术研究还是商业应用,相信这些资源都能帮助你更好地了解和使用DBRX。欢迎深入探索这个强大的开源AI模型!










