DBRX:开创高效开源大语言模型的新标准
在人工智能领域,大语言模型(LLM)的发展一直备受关注。近日,数据科学和AI公司Databricks推出了一款全新的开源大语言模型DBRX,在多项基准测试中展现出卓越的性能,为开源AI模型树立了新的标杆。本文将深入介绍DBRX的特点、性能表现以及其对AI领域的重要意义。
DBRX模型概述
DBRX是由Databricks公司的Mosaic Research团队开发的通用大语言模型。作为一个混合专家(Mixture-of-Experts, MoE)模型,DBRX拥有1320亿个总参数,其中360亿个参数在训练或推理过程中处于活跃状态。该模型采用了16个专家,每次激活4个,这种设计使得DBRX在保持强大性能的同时,大幅提高了计算效率。
DBRX经过了12万亿个token的预训练,具有32K tokens的上下文长度。Databricks公司开源了两个版本的DBRX模型:
- DBRX Base:预训练的基础模型
- DBRX Instruct:经过指令微调的模型
这两个版本都可以在Hugging Face平台上获取,为研究人员和开发者提供了强大的工具。
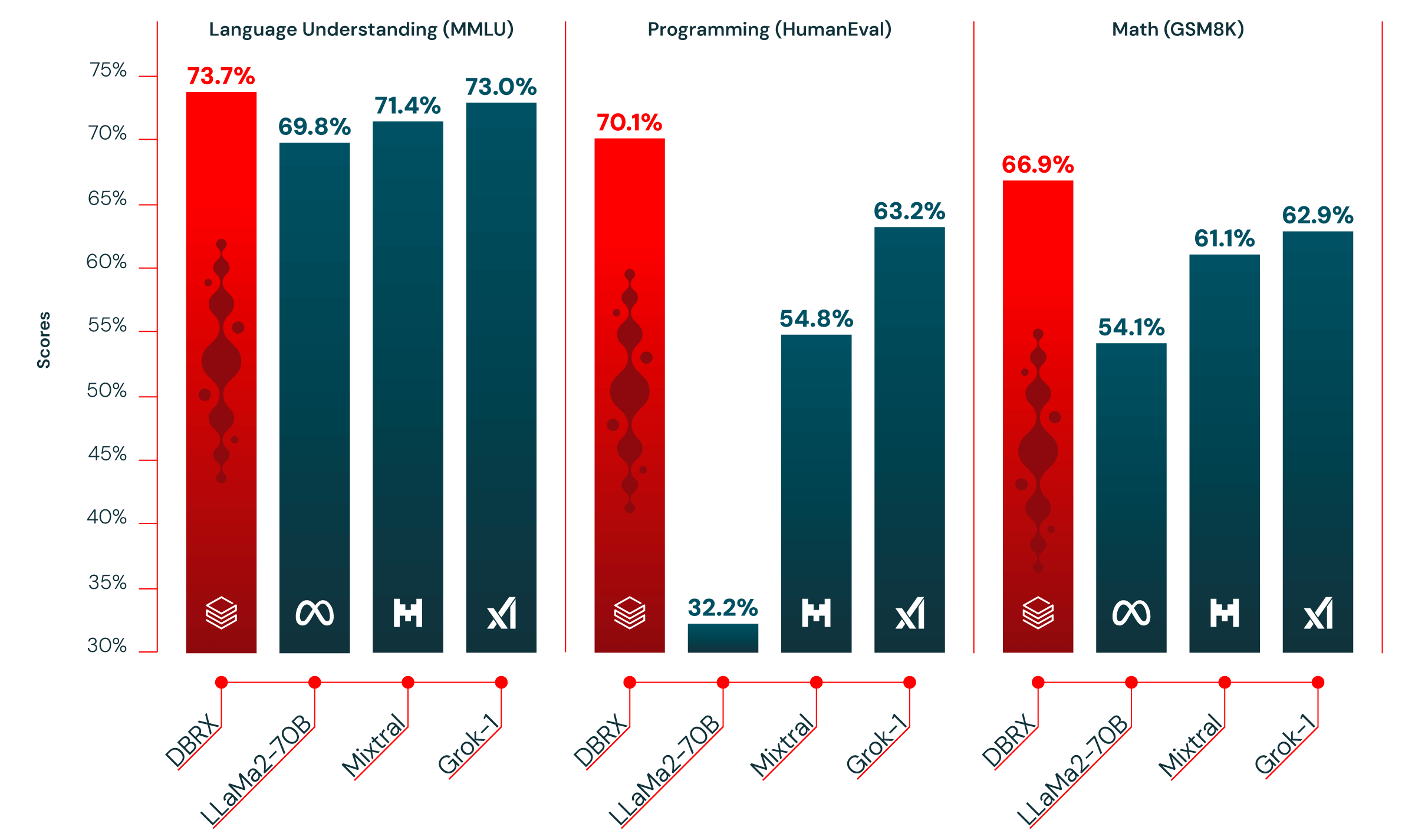
卓越的性能表现
DBRX在多项标准基准测试中展现出了优异的性能,超越了包括Meta的LLaMA 2、Mistral AI的Mixtral和xAI的Grok在内的多个知名开源模型。具体表现如下:
-
语言理解:在MMLU(Massive Multitask Language Understanding)测试中,DBRX Instruct得分73.7%,领先其他开源模型。
-
编程能力:在HumanEval基准测试中,DBRX Instruct得分70.1%,不仅超越了通用模型,甚至超过了专门为编程设计的CodeLLaMA-70B Instruct(67.8%)。
-
数学推理:在GSM8k测试中,DBRX Instruct得分66.9%,同样优于其他开源模型。
-
综合能力:在Hugging Face开源LLM排行榜和Databricks Model Gauntlet等综合基准测试中,DBRX Instruct均取得了最高分。
值得注意的是,DBRX不仅超越了其他开源模型,在某些测试中甚至接近或超过了GPT-3.5等闭源商业模型的表现。这一成就充分展示了开源AI模型的巨大潜力。
高效的模型架构
DBRX采用了先进的混合专家(MoE)架构,这种设计使得模型在保持强大性能的同时,大幅提高了训练和推理效率:
-
训练效率:与传统密集模型相比,MoE架构的训练效率提高了约2倍。
-
推理速度:DBRX的推理速度最高可达每秒150个token/用户,比LLaMA2-70B快2倍。
-
模型规模:DBRX的总参数量和活跃参数量仅为Grok-1的40%左右。
这种高效的架构设计不仅降低了模型的训练和部署成本,还为实际应用提供了更好的响应速度。
开源与定制化
DBRX的开源发布为AI研究和应用带来了新的机遇:
-
开放访问:研究人员和开发者可以自由访问和使用DBRX模型,促进AI技术的创新和发展。
-
定制化能力:企业可以基于DBRX进行进一步微调,打造适合自身业务需求的AI应用。
-
透明度:Databricks公司公开了DBRX的训练过程和技术细节,有助于推动AI领域的知识共享。
DBRX的应用前景
DBRX的强大性能和灵活性为多个领域的AI应用开辟了新的可能:
-
智能客服:利用DBRX的自然语言理解能力,企业可以构建更智能、更人性化的客户服务系统。
-
代码辅助:DBRX在编程方面的出色表现使其成为理想的代码生成和辅助工具。
-
数据分析:模型的数学推理能力可用于复杂的数据分析和预测任务。
-
内容创作:DBRX可以辅助文案写作、报告生成等创意工作。
-
教育辅助:利用模型的知识库,可以开发个性化的学习助手和答疑系统。
结语
DBRX的发布标志着开源大语言模型进入了一个新的阶段。它不仅在性能上达到了新的高度,还通过高效的架构设计降低了AI应用的门槛。随着更多研究者和开发者加入DBRX的生态系统,我们有理由期待看到更多创新的AI应用涌现。
DBRX的成功也再次证明,开源模式在推动AI技术进步方面发挥着不可或缺的作用。通过开放合作,我们能够更快地突破AI的边界,为人类社会带来更多益处。
未来,随着DBRX及其衍生模型的不断优化和应用,我们可能会看到更多领域被AI赋能,推动各行各业的数字化转型。对于企业和开发者而言,现在正是深入探索和利用DBRX潜力的最佳时机。










