
DC-TTS模型简介
DC-TTS(Deep Convolutional Text-to-Speech)是由Kyubyong Park等人在2017年提出的一种新型文本转语音(TTS)模型。该模型基于深度卷积神经网络架构,通过引入引导注意力机制,实现了高效的端到端训练。相比传统的RNN-based模型如Tacotron,DC-TTS具有更快的训练和推理速度,同时保持了较高的合成语音质量。

DC-TTS模型主要由两个子网络组成:
- Text2Mel网络:将输入文本转换为梅尔频谱图
- SSRN(Spectrogram Super-resolution Network)网络:将梅尔频谱图转换为线性频谱图
这种模块化的设计使得模型训练更加灵活,可以分别优化两个子网络。同时,DC-TTS还引入了引导注意力机制,通过在训练过程中给予注意力权重一定的约束,使得模型能够更快地学习到文本和语音之间的对齐关系。
模型实现与训练
Kyubyong Park在GitHub上开源了DC-TTS的TensorFlow实现[1],为研究人员提供了可复现的代码基础。该实现主要包含以下几个关键文件:
hyperparams.py: 定义模型超参数data_load.py: 数据加载和预处理modules.py: 实现各种神经网络层networks.py: 定义Text2Mel和SSRN网络结构train.py: 模型训练脚本
模型训练分为两个阶段:
- 训练Text2Mel网络:
python train.py 1
- 训练SSRN网络:
python train.py 2
如果有多个GPU,可以同时训练这两个网络以加快训练速度。
训练过程中,可以通过TensorBoard观察loss曲线和注意力权重的变化:
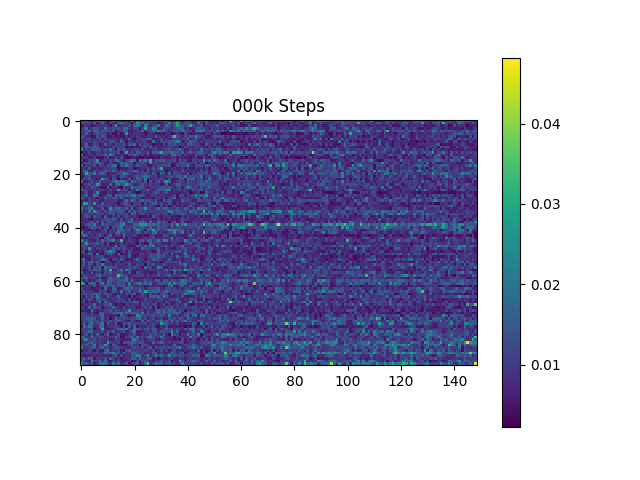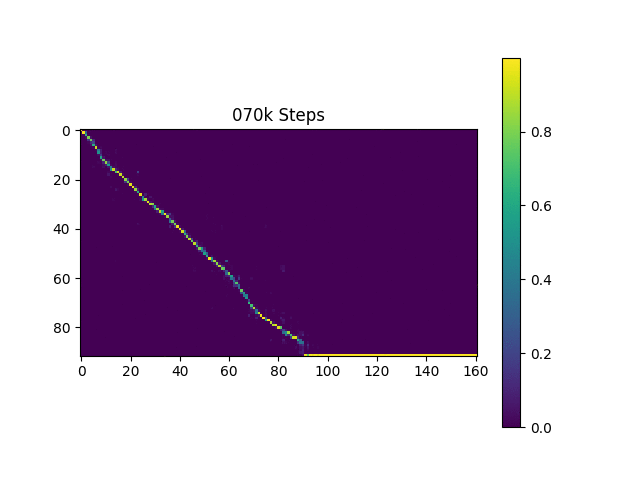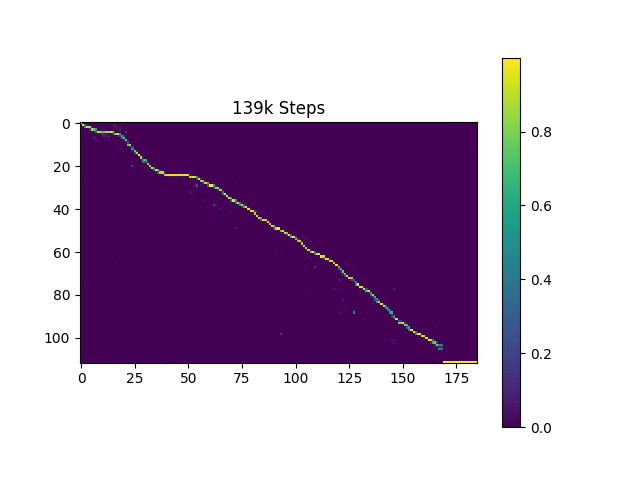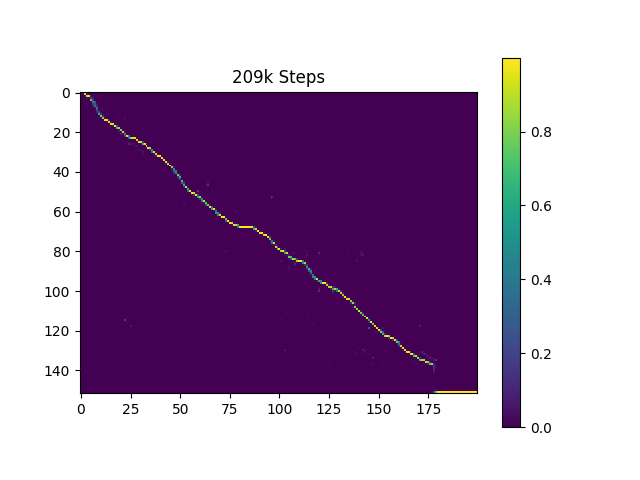
从上图可以看出,随着训练的进行,注意力权重逐渐呈现出单调的对角线分布,说明模型成功学习到了文本和语音之间的对齐关系。
数据集与实验结果
为了验证DC-TTS模型的性能,作者在多个英语和韩语数据集上进行了实验:
- LJ Speech Dataset: 24小时英语单发音人数据集
- Nick Offerman's Audiobooks: 18小时英语有声书数据集
- Kate Winslet's Audiobook: 5小时英语有声书数据集
- KSS Dataset: 12小时韩语单发音人数据集
实验结果表明,DC-TTS在各个数据集上都能够生成高质量的合成语音。即使在数据量较少的Kate Winslet数据集(5小时)上,模型也能学习到说话人的声音特征。这说明DC-TTS具有较强的泛化能力和数据效率。
作者还提供了不同训练步数下的合成语音样本[2],可以直观地感受模型的训练过程。随着训练的进行,合成语音的质量逐步提高,音色和韵律也越来越接近真实语音。
DC-TTS的优势与局限性
相比其他TTS模型,DC-TTS具有以下优势:
- 训练速度快:仅使用卷积层,避免了RNN的串行计算,可以充分利用GPU并行加速
- 合成速度快:推理时无需自回归,可以并行生成整个语音序列
- 样本效率高:在较小的数据集上也能取得不错的效果
- 稳定性好:引导注意力机制使得训练更加稳定,不易出现对齐错误
当然,DC-TTS也存在一些局限性:
- 合成音质略逊于一些更复杂的模型(如Tacotron 2)
- 难以控制韵律、重音等细节特征
- 不支持端到端的字符级输入,需要额外的文本前端处理
未来研究方向
尽管DC-TTS取得了不错的效果,但在TTS领域仍有很多值得探索的方向:
- 结合自注意力机制,进一步提升长句的建模能力
- 引入更强的声码器(如WaveNet),提升音质
- 探索多说话人、跨语言的迁移学习方法
- 增强对韵律、情感等细粒度特征的建模能力
- 研究更高效的网络结构,进一步提升训练和推理速度
结语
DC-TTS作为一种高效的端到端TTS模型,在学术界和工业界都引起了广泛关注。它不仅推动了TTS技术的发展,也为语音合成在更多场景下的应用提供了可能。相信在未来,我们会看到更多基于DC-TTS思想的改进模型,为人机交互带来更自然、更个性化的语音体验。
如果你对DC-TTS感兴趣,可以访问项目的GitHub仓库[3]获取更多信息,并尝试复现实验结果。同时,也欢迎关注最新的TTS研究进展,如Tacotron系列[4]和FastSpeech系列[5]等工作,它们都在不同方面对DC-TTS进行了改进和扩展。
[1] https://github.com/Kyubyong/dc_tts [2] https://soundcloud.com/kyubyong-park/sets/dc_tts [3] https://github.com/Kyubyong/dc_tts [4] https://github.com/kyubyong/tacotron [5] https://github.com/kyubyong/deepvoice3










