
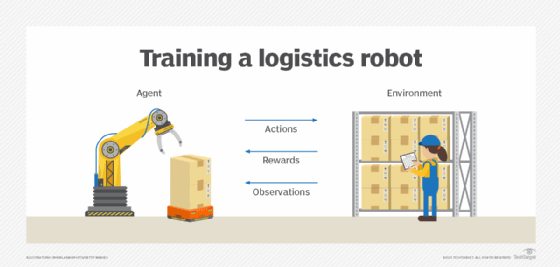
强化学习的基本概念与框架
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,其核心思想是通过与环境的交互来学习最优策略。在强化学习中,智能体(agent)通过在环境中采取行动并观察结果来学习如何最大化累积奖励。这种学习方式模仿了人类和动物通过试错来学习的过程,具有很强的普适性。
强化学习的基本框架包括以下几个关键要素:
-
智能体(Agent):学习和决策的主体,可以感知环境状态并采取行动。
-
环境(Environment):智能体所处的外部世界,会根据智能体的行为产生新的状态和奖励。
-
状态(State):环境在某一时刻的描述。
-
行动(Action):智能体可以采取的操作。
-
奖励(Reward):环境对智能体行为的反馈,用于评价行为的好坏。
-
策略(Policy):智能体的行为准则,决定在什么状态下采取什么行动。
-
价值函数(Value Function):评估某个状态或某个状态-动作对的长期价值。
-
模型(Model):智能体对环境动态的理解,用于预测环境的变化。
强化学习的目标是找到一个最优策略,使得从任何初始状态开始,智能体获得的期望累积奖励最大化。这个过程通常被建模为马尔可夫决策过程(Markov Decision Process, MDP).
强化学习的核心算法
1. 动态规划方法
动态规划是最早用于求解MDP问题的方法之一,它假设环境模型已知,通过迭代计算来找到最优策略。主要包括:
- 策略迭代(Policy Iteration):交替进行策略评估和策略改进,直到收敛到最优策略。
- 价值迭代(Value Iteration):直接迭代计算最优价值函数,然后导出最优策略。
动态规划方法计算效率高,但要求完全了解环境模型,在实际应用中受到限制。
2. 蒙特卡洛方法
蒙特卡洛方法不需要完整的环境模型,而是通过采样多个完整的轨迹来估计价值函数。它特别适用于回合制任务,但对于连续任务效率较低。
3. 时序差分学习
时序差分(TD)学习结合了动态规划和蒙特卡洛方法的优点。它可以在线学习,利用当前估计来更新先前的估计,不需要等待整个回合结束。典型的TD学习算法包括Q-learning和SARSA。
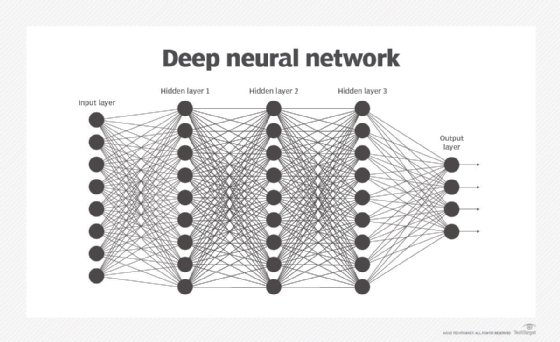
4. 深度Q网络(DQN)
DQN将深度神经网络与Q-learning相结合,能够处理高维状态空间。它引入了经验回放和目标网络等技术来提高学习的稳定性。
5. 策略梯度方法
策略梯度方法直接对策略进行优化,而不是通过价值函数间接优化。这类方法包括REINFORCE算法、Actor-Critic方法等,特别适合于连续动作空间。
6. 高级策略优化算法
为了提高策略梯度方法的稳定性和样本效率,研究人员提出了一系列改进算法:
- 信任区域策略优化(TRPO)
- 近端策略优化(PPO)
- 软演员评论家(SAC)
这些算法在各种任务中都表现出色,特别是在机器人控制等复杂环境中。
模型相关与模型无关方法
强化学习算法可以分为模型相关(Model-based)和模型无关(Model-free)两大类:
-
模型无关方法:直接从经验中学习,不需要显式建立环境模型。这类方法包括Q-learning、策略梯度等,具有通用性强、易于实现的优点。
-
模型相关方法:通过学习或已知的环境模型来进行规划和决策。这类方法可以更有效地利用数据,但对模型准确性要求较高。
近年来,结合模型相关和模型无关方法的混合算法也取得了很好的效果,如Dyna算法、基于想象的强化学习等。
探索与利用
在强化学习中,平衡探索(Exploration)和利用(Exploitation)是一个核心问题。智能体需要在尝试新的、可能有更高回报的行动(探索)和选择当前已知的最佳行动(利用)之间取得平衡。常用的探索策略包括:
- ε-贪心策略
- 玻尔兹曼探索
- UCB(Upper Confidence Bound)算法
- Thompson采样
强化学习的前沿发展
1. 多智能体强化学习
研究多个智能体如何在共享环境中学习和协作,应用于交通控制、机器人集群等领域。
2. 分层强化学习
通过分层结构来处理长期规划和复杂任务分解,提高学习效率和泛化能力。
3. 元强化学习
旨在学习学习的算法,使智能体能够快速适应新任务。
4. 离线强化学习
研究如何从固定的数据集中学习策略,而不需要与环境进行实时交互。
强化学习的应用
强化学习在众多领域都有广泛应用,以下是一些典型例子:
-
游戏AI:如AlphaGo在围棋领域的突破性成就。
-
机器人控制:用于开发能适应复杂环境的灵活机器人。
-
自动驾驶:用于车辆路径规划和决策制定。
-
推荐系统:优化用户体验和平台收益。
-
金融交易:开发自动交易策略。
-
医疗健康:个性化治疗方案制定,如动态给药策略。
-
能源管理:优化能源分配和使用。

挑战与未来展望
尽管强化学习取得了显著进展,但仍面临一些重要挑战:
-
样本效率:如何用更少的数据学到好的策略。
-
泛化能力:如何将学到的知识迁移到新的任务和环境。
-
安全性和鲁棒性:如何确保强化学习系统在现实世界中的可靠性。
-
可解释性:如何理解和解释强化学习模型的决策过程。
-
长期规划:如何有效处理具有长期依赖性的任务。
未来,强化学习有望在以下方向取得突破:
- 与其他AI技术的深度融合,如自然语言处理、计算机视觉等。
- 在更复杂的现实世界问题中的应用,如气候变化应对、城市规划等。
- 向通用人工智能(AGI)迈进,开发具有类人学习能力的AI系统。
结语
强化学习作为一种powerful的学习范式,正在深刻改变人工智能的发展轨迹。它不仅在学术界引发了广泛研究,也在工业界找到了越来越多的应用场景。随着算法的不断进步和计算能力的提升,我们有理由相信,强化学习将在未来的智能系统中扮演更加重要的角色,为解决复杂的实际问题提供强大工具。
作为一个快速发展的领域,强化学习还有很多未知待我们去探索。无论你是研究人员、工程师,还是对AI感兴趣的学习者,投身强化学习研究都将是一个充满挑战和机遇的选择。让我们共同期待强化学习带来的更多突破和创新。


















