
深度强化学习玩转Flappy Bird:深度Q网络算法详解
深度强化学习是人工智能领域一个令人兴奋的研究方向,它结合了深度学习和强化学习的优势,能够让AI系统在复杂的环境中学习决策。本文将以经典游戏Flappy Bird为例,详细介绍如何使用深度Q网络(Deep Q-Network, DQN)算法来训练AI玩游戏,让我们一起来探索这个有趣的AI应用吧!
Flappy Bird游戏简介
Flappy Bird是一款简单而富有挑战性的手机游戏,玩家需要控制一只小鸟,通过点击屏幕让小鸟向上飞行,穿过一系列垂直排列的管道。游戏的目标是尽可能长时间地生存下去,获得更高的分数。虽然游戏规则简单,但由于需要精确控制小鸟的高度,实际上相当具有挑战性。
这个游戏非常适合用来学习强化学习算法,因为:
- 状态空间相对简单,主要包括小鸟的位置、速度以及下一个管道的位置。
- 动作空间只有两个:拍打翅膀或不动。
- 奖励函数明确:每穿过一个管道得分,撞到管道或地面则游戏结束。
深度Q网络(DQN)算法原理
深度Q网络是将深度学习与Q学习相结合的算法,它使用神经网络来近似Q函数。DQN的核心思想包括:
-
经验回放(Experience Replay): 将智能体与环境交互的经验存储在一个回放缓冲区中,训练时随机抽取一批经验进行学习,这可以打破样本之间的相关性,提高学习的稳定性。
-
目标网络(Target Network): 使用一个单独的目标Q网络来生成目标Q值,这个网络的参数会定期从主Q网络复制过来,但在学习过程中保持固定,这可以减少目标的波动,提高训练的稳定性。
-
ε-贪心策略(ε-greedy Policy): 在选择动作时,以ε的概率随机选择动作,以1-ε的概率选择Q值最大的动作。这可以在探索和利用之间取得平衡。
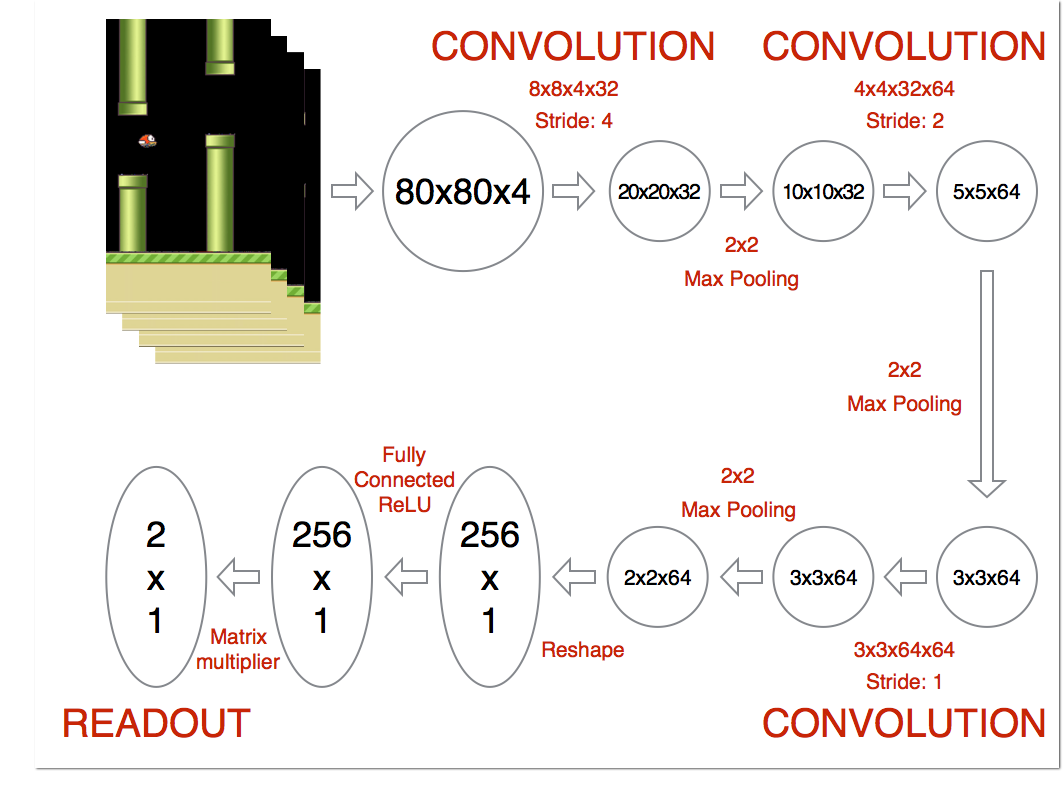
网络架构
本项目使用了一个卷积神经网络作为Q网络,其结构如下:
- 输入层: 80x80x4的图像,代表4帧连续的游戏画面
- 第一卷积层: 32个8x8卷积核,步长为4,激活函数为ReLU
- 第二卷积层: 64个4x4卷积核,步长为2,激活函数为ReLU
- 第三卷积层: 64个3x3卷积核,步长为1,激活函数为ReLU
- 全连接层: 512个神经元,激活函数为ReLU
- 输出层: 2个神经元,分别代表两个动作的Q值
实验过程
-
预处理: 将游戏画面转换为80x80的灰度图像,并将连续4帧堆叠作为网络输入。
-
初始化: 随机初始化Q网络参数,创建经验回放缓冲区。
-
训练循环:
- 使用ε-贪心策略选择动作
- 执行动作,观察奖励和下一个状态
- 将经验存入回放缓冲区
- 从缓冲区随机抽取一批经验进行学习
- 计算目标Q值和损失函数
- 使用梯度下降更新网络参数
-
参数调整:
- ε值从0.1线性衰减到0.0001
- 学习率设置为0.000001
- 每32步更新一次目标网络
实验结果
经过训练,DQN算法成功学会了玩Flappy Bird游戏。以下是一个训练好的智能体玩游戏的演示:

从演示中可以看到,AI控制的小鸟能够稳定地穿过管道,表现出了相当高的技巧水平。
结论与思考
通过这个项目,我们可以看到深度强化学习算法在游戏环境中的强大学习能力。DQN算法能够直接从原始像素输入中学习到有效的控制策略,这种端到端的学习方式展现了深度学习的巨大潜力。
然而,这个项目也存在一些局限性:
- 训练时间较长,需要大量的计算资源。
- DQN算法在一些更复杂的环境中可能表现不佳。
- 模型的可解释性较差,难以理解AI做出决策的具体原因。
未来的研究方向可以包括:
- 尝试更先进的强化学习算法,如PPO、SAC等。
- 探索如何将学到的策略迁移到其他类似的游戏中。
- 研究如何提高模型的可解释性和鲁棒性。
总的来说,这个项目为我们展示了深度强化学习的魅力,也为进一步探索AI在游戏和决策领域的应用奠定了基础。希望这个例子能激发你对深度强化学习的兴趣,鼓励你尝试将这些技术应用到更多有趣的问题中去!
参考资料
- Mnih V. et al. Human-level control through deep reinforcement learning. Nature, 2015.
- Mnih V. et al. Playing Atari with Deep Reinforcement Learning. NIPS Deep Learning Workshop, 2013.
- DeepLearningFlappyBird GitHub Repository
让我们一起期待AI在游戏和其他领域带来的更多惊喜吧! 🚀🎮🤖











