
DeepLearningFlappyBird项目介绍
DeepLearningFlappyBird是一个使用深度Q网络(Deep Q-Network, DQN)来学习玩Flappy Bird游戏的开源项目。该项目展示了如何将深度强化学习算法应用于经典的Flappy Bird游戏,让AI代理自主学习游戏策略。

主要特点
- 使用卷积神经网络作为Q函数逼近器
- 采用经验回放(Experience Replay)提高样本效率
- ε-贪婪策略平衡探索与利用
- 使用目标网络稳定训练过程
快速开始
环境依赖
- Python 2.7或3
- TensorFlow 0.7
- pygame
- OpenCV-Python
运行步骤
git clone https://github.com/yenchenlin1994/DeepLearningFlappyBird.git
cd DeepLearningFlappyBird
python deep_q_network.py
深度Q网络算法
深度Q网络(DQN)是一种将深度学习与Q学习相结合的强化学习算法。其核心思想是使用神经网络来近似动作价值函数(Q函数)。
算法流程
- 初始化经验回放缓冲区D
- 初始化动作价值函数Q,参数θ随机
- 对每个回合:
- 初始化状态s1
- 对每个时间步t:
- 以ε概率选择随机动作at,否则at = argmax Q(st,a;θ)
- 执行动作at,观察奖励rt和下一状态st+1
- 将(st,at,rt,st+1)存入D
- 从D中采样minibatch
- 设置目标yi = ri (终止状态) 或 ri + γ maxa' Q(si+1,a';θ) (非终止状态)
- 对(yi - Q(si,ai;θ))^2 关于θ进行梯度下降
网络结构
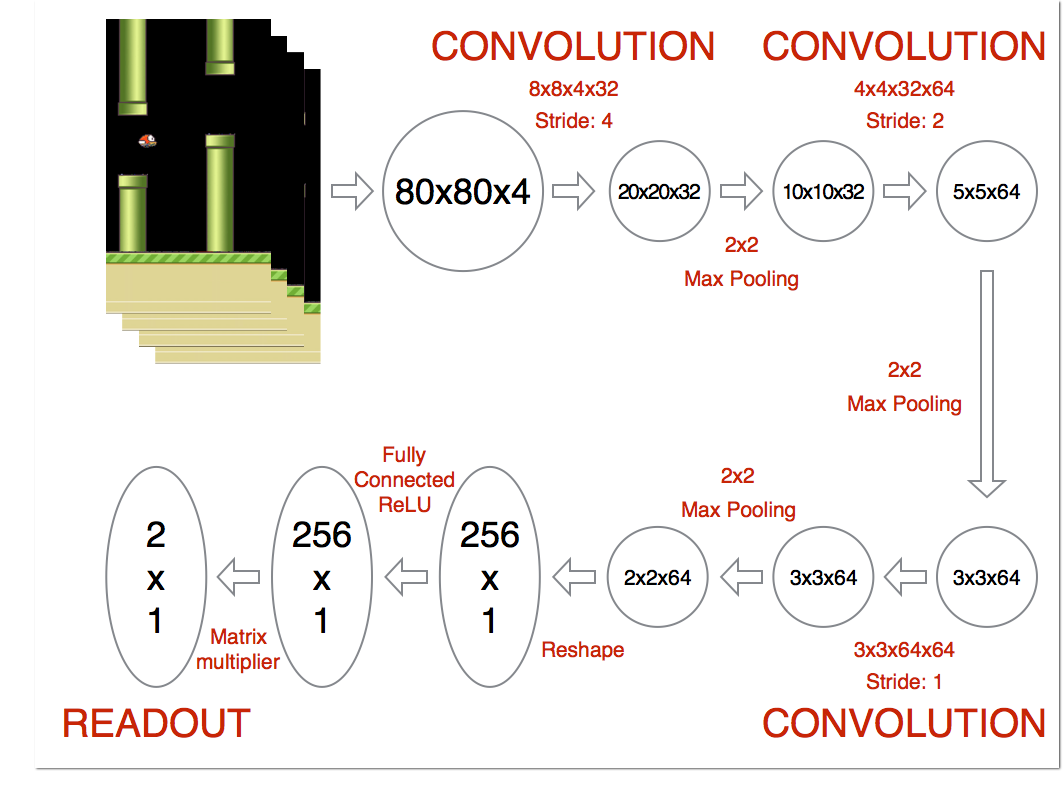
- 输入:4帧80x80灰度图像
- 3个卷积层 + 1个全连接层
- 输出:2个动作的Q值(不动/跳跃)
实验过程
- 预处理:去除背景,灰度化,调整大小至80x80
- 初始化:权重随机初始化,经验池大小50万
- 训练:
- ε从0.1线性衰减至0.0001
- 每步从经验池采样32个样本
- Adam优化器,学习率0.000001
经过训练,AI代理可以熟练地玩Flappy Bird游戏,展现出不亚于人类玩家的水平。
相关资源
希望这份学习资料可以帮助你快速入门DeepLearningFlappyBird项目,体验深度强化学习的魅力。如有任何问题,欢迎在GitHub上提issue讨论交流。











