
DeepRL: 模块化的深度强化学习算法实现
深度强化学习(Deep Reinforcement Learning, DRL)是人工智能领域一个备受关注的研究方向,它结合了深度学习和强化学习的优势,在游戏、机器人控制等领域取得了突破性进展。然而,实现和复现先进的DRL算法往往需要大量的工程工作。为了降低研究人员的门槛,GitHub上的DeepRL项目提供了一系列流行DRL算法的PyTorch实现,受到了广泛关注。本文将详细介绍DeepRL项目的特点、支持的算法以及使用方法。
项目概述
DeepRL是由Shangtong Zhang开发的开源项目,旨在提供模块化、易于使用和扩展的深度强化学习算法实现。该项目具有以下主要特点:
- 基于PyTorch框架实现,充分利用了GPU加速能力
- 支持多种流行的DRL算法,包括DQN、A2C、PPO等
- 模块化设计,便于研究人员快速实现新的算法
- 支持多种经典强化学习环境,如Atari游戏和MuJoCo物理仿真
- 提供了详细的文档和示例代码,降低了使用门槛
截至目前,DeepRL项目在GitHub上已获得超过3200个星标,显示了其在研究社区的受欢迎程度。
支持的算法
DeepRL项目实现了以下主流深度强化学习算法:
- Deep Q-Network (DQN)及其变种:
- Double DQN
- Dueling DQN
- Prioritized Experience Replay DQN
- Categorical DQN (C51)
- Quantile Regression DQN (QR-DQN)
- Advantage Actor-Critic (A2C),支持离散和连续动作空间
- Synchronous N-Step Q-Learning
- Deep Deterministic Policy Gradient (DDPG)
- Proximal Policy Optimization (PPO)
- The Option-Critic Architecture (OC)
- Twin Delayed DDPG (TD3)
此外,DeepRL还包含了作者一系列研究论文中提出的新算法实现,如Off-PAC-KL、TruncatedETD、DifferentialGQ等。这些算法涵盖了目前DRL研究的主要方向,为研究人员提供了丰富的基准实现。
项目架构与使用方法
DeepRL采用模块化的设计架构,主要包含以下几个核心组件:
- 智能体(Agent): 实现各种DRL算法的核心逻辑
- 网络(Network): 定义深度神经网络结构
- 任务(Task): 封装强化学习环境接口
- 回放缓冲区(Replay Buffer): 存储和采样训练数据
- 组件(Component): 提供通用功能模块
这种模块化设计使得用户可以方便地组合不同组件,快速实现和测试新的算法ideas。
要使用DeepRL,用户首先需要安装PyTorch和其他依赖库。项目提供了详细的安装说明和Docker环境配置。安装完成后,可以通过examples.py文件运行各种算法的示例:
from deep_rl import *
# 运行DQN算法
cfg = Config()
cfg.task_fn = lambda: Task('BreakoutNoFrameskip-v4')
cfg.network_fn = lambda: VanillaNet(cfg.action_dim, NatureConvBody())
ag = DQNAgent(cfg)
run_steps(agent)
DeepRL还提供了丰富的配置选项,用户可以方便地调整超参数、网络结构等。
性能评估
为了展示DeepRL实现的有效性,项目提供了在多个标准环境下的性能曲线。以下是在Atari Breakout游戏上的对比结果:
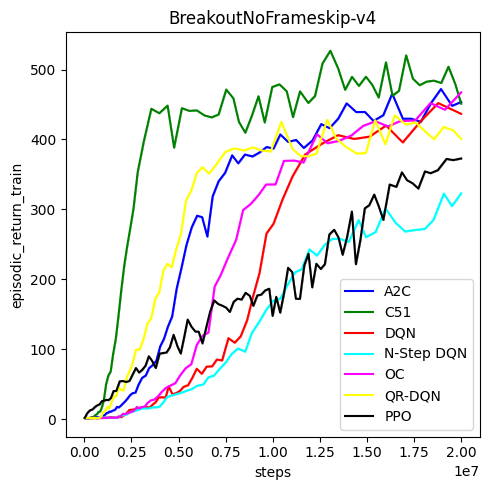
从图中可以看出,DeepRL实现的DQN、C51和QR-DQN算法都能在该环境中取得不错的学习效果。其中C51和QR-DQN的表现优于vanilla DQN,这与原论文的结果一致。
在连续控制任务MuJoCo环境中,DeepRL实现的DDPG和TD3算法也展现了良好的性能:

上图展示了DDPG和TD3在多个MuJoCo任务中的评估性能。可以看出TD3算法在大多数任务中都优于DDPG,这验证了原论文中的结论。
这些结果表明,DeepRL提供的算法实现是可靠和高效的,可以作为研究的基准。
项目贡献与未来发展
作为一个开源项目,DeepRL欢迎社区贡献。贡献的方式包括:
- 报告和修复bug
- 改进文档
- 添加新的算法实现
- 优化现有算法的性能
- 增加新的环境支持
未来,DeepRL计划继续跟进最新的DRL研究进展,实现更多前沿算法。同时,项目也将致力于提高代码的可读性和性能,使其更适合大规模实验。
结语
DeepRL项目为深度强化学习研究提供了一个valuable的工具。通过提供模块化、高效的算法实现,它大大降低了研究人员的工作量,加速了新ideas的验证过程。无论是初学者还是资深研究者,都可以从这个项目中受益。
对于有兴趣深入了解或使用DeepRL的读者,可以访问项目的GitHub仓库获取更多信息。同时,也欢迎大家为这个开源项目做出贡献,共同推动深度强化学习领域的发展。
深度强化学习是一个快速发展的领域,新的算法和应用不断涌现。DeepRL这样的开源项目,为整个研究社区提供了宝贵的资源,有望加速这一领域的创新步伐。让我们共同期待DeepRL以及整个DRL领域的美好未来! 🚀🤖









