
DiT-MoE:扩展扩散变换器到160亿参数
近年来,扩散模型在图像生成领域取得了巨大成功。然而,随着模型规模的不断增大,如何高效地扩展模型参数成为一个重要挑战。为了解决这个问题,研究人员提出了DiT-MoE(Diffusion Transformer with Mixture of Experts),这是一种新型的扩散变换器架构,可以将模型规模扩展到160亿参数,同时保持高效的推理性能。
DiT-MoE的核心思想
DiT-MoE的核心思想是将传统的密集扩散变换器改造为稀疏版本。具体来说,它引入了混合专家(Mixture of Experts, MoE)机制,将每个变换器层分解为多个专家子网络。在推理过程中,只有部分专家会被激活,从而大大减少了计算量和内存消耗。
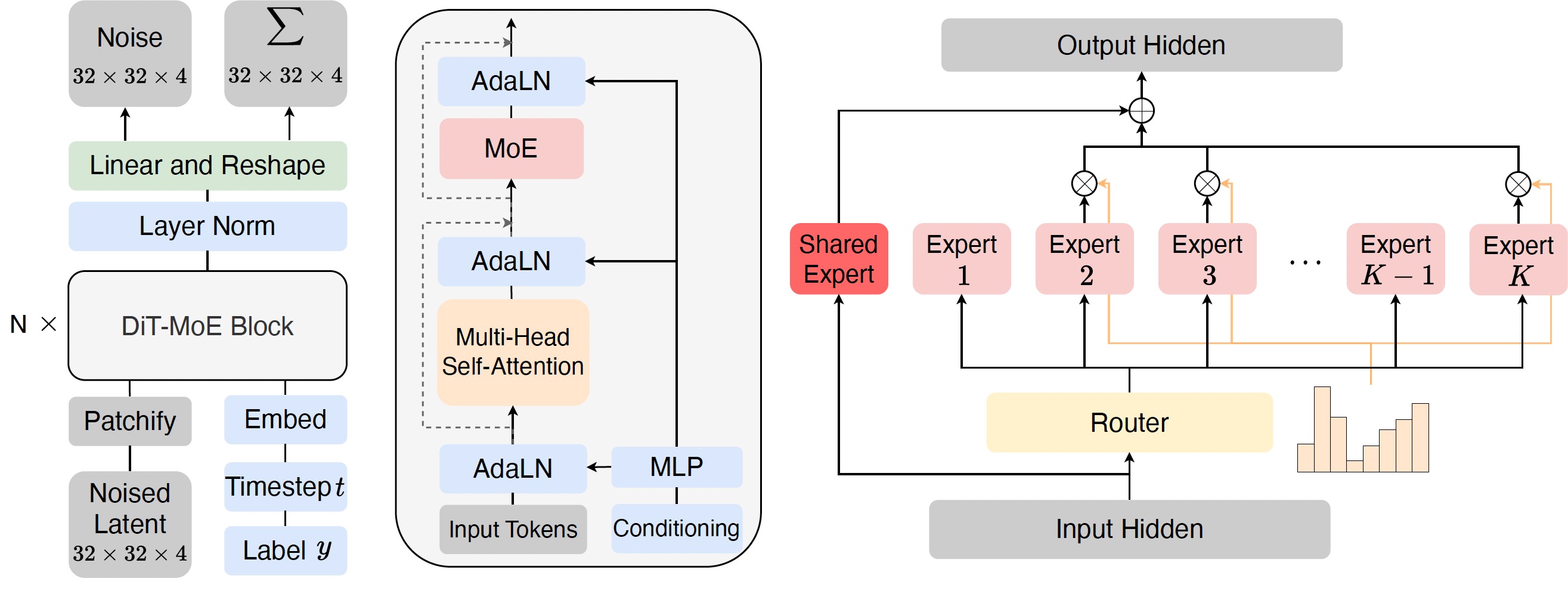
如上图所示,DiT-MoE的架构包含以下关键组件:
-
共享专家路由:所有层共享同一个路由网络,减少了额外的计算开销。
-
专家级平衡损失:引入新的损失函数来平衡不同专家的使用频率,避免出现"专家崩溃"问题。
-
整流流训练:采用整流流(Rectified Flow)方法进行训练,提高模型性能和收敛速度。
模型训练
DiT-MoE的训练过程涉及多个创新点:
-
分布式训练:支持多节点训练,解决了原始DiT存在的bug。
-
DeepSpeed优化:对于大规模模型,推荐使用DeepSpeed配合Flash Attention进行训练。
-
整流流训练:相比传统的扩散过程,整流流训练可以带来更好的性能和更快的收敛速度。
训练命令示例:
python -m torch.distributed.launch --nnodes=1 --nproc_per_node=8 train_deepspeed.py \
--deepspeed_config config/zero2.json \
--model DiT-XL/2 \
--rf True \
--num_experts 8 \
--num_experts_per_tok 2 \
--data-path /path/to/imagenet/train \
--vae-path /path/to/vae \
--train_batch_size 32
模型推理
DiT-MoE提供了方便的推理脚本sample.py,可以从预训练模型中采样生成图像。值得注意的是,对于大规模模型,推理时使用了torch.float16以提高效率。
推理命令示例:
python sample.py \
--model DiT-XL/2 \
--ckpt /path/to/model \
--vae-path /path/to/vae \
--image-size 256 \
--cfg-scale 1.5
预训练模型
DiT-MoE提供了多个预训练模型,涵盖了不同的参数规模和图像分辨率:
| 模型 | 图像分辨率 | 参数链接 | 训练方法 |
|---|---|---|---|
| DiT-MoE-S/2-8E2A | 256x256 | 链接 | DDIM |
| DiT-MoE-S/2-16E2A | 256x256 | 链接 | DDIM |
| DiT-MoE-B/2-8E2A | 256x256 | 链接 | DDIM |
| DiT-MoE-XL/2-8E2A | 256x256 | 链接 | RF |
| DiT-MoE-G/2-16E2A | 256x256 | 链接 | RF |
这些预训练模型为研究人员和开发者提供了便利,可以直接用于图像生成或进一步微调。
专家特化分析
为了深入理解DiT-MoE中专家网络的行为,研究人员提供了一系列分析工具:
expert_data.py: 用于采样不同条件下专家的激活情况。heatmap_xx.py: 可视化不同场景下专家选择的频率。
这些工具有助于研究人员分析模型内部的工作机制,为进一步改进模型提供了重要依据。
结论与展望
DiT-MoE成功将扩散变换器扩展到了160亿参数,同时保持了高效的推理性能。这一成果为大规模图像生成模型的发展开辟了新的方向。未来的研究方向可能包括:
- 进一步优化训练和推理脚本,提高模型效率。
- 深入分析专家路由机制,探索更高效的路由策略。
- 将DiT-MoE应用到更多下游任务,如图像编辑、风格迁移等。
- 探索与其他先进技术(如LoRA、QLoRA等)的结合,进一步提升模型性能和效率。
DiT-MoE的开源为整个AI社区提供了宝贵的资源。研究人员和开发者可以基于这一框架进行进一步的创新和应用,推动大规模图像生成技术的不断进步。
参考资料
通过深入理解和应用DiT-MoE,我们有望在图像生成、计算机视觉等领域取得更多突破性进展,为人工智能的发展注入新的动力。 🚀🎨🖼️









