
 Github
Github Huggingface
Huggingface 论文
论文使用专家混合扩展扩散变换器
官方 PyTorch 实现

本仓库包含我们论文中将扩散变换器扩展到160亿参数(DiT-MoE)的PyTorch模型定义、预训练权重和训练/采样代码。 DiT-MoE作为扩散变换器的稀疏版本,具有可扩展性,能够与密集网络竞争,同时展现高度优化的推理能力。
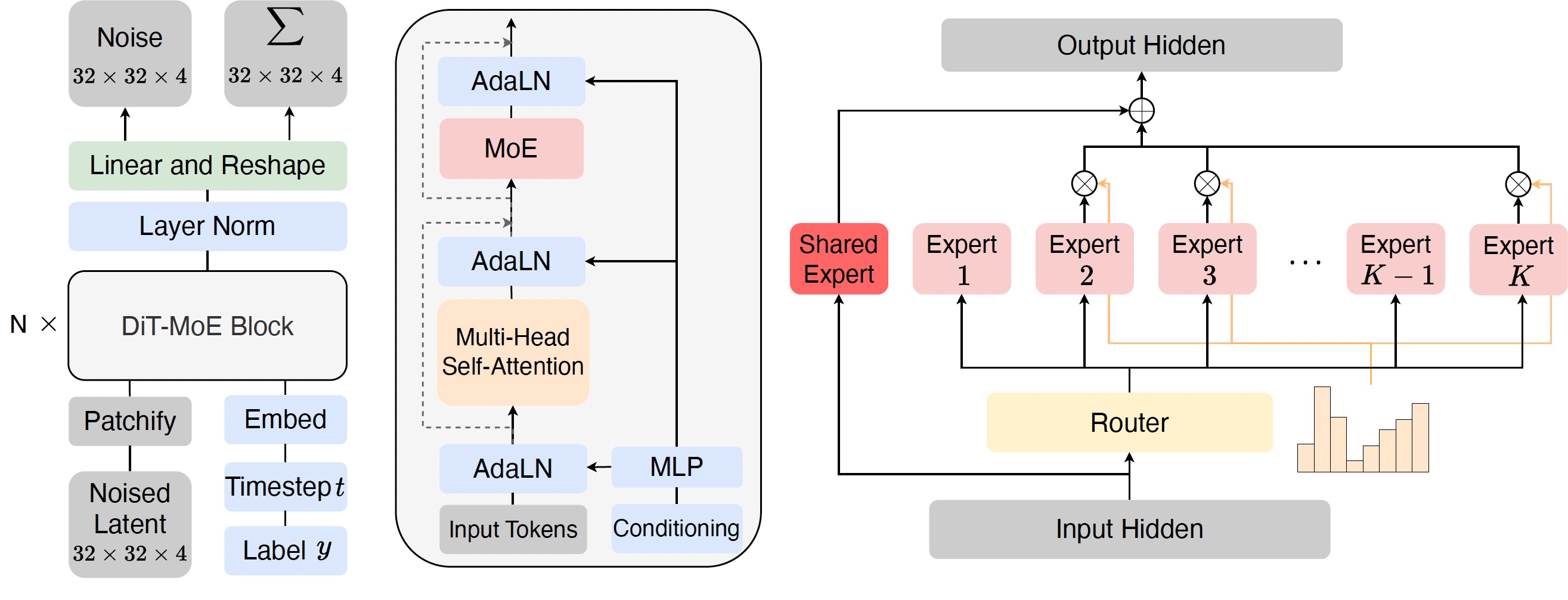
- 🪐 DiT-MoE的PyTorch实现
- ⚡️ 论文中的预训练检查点
- 💥 用于运行预训练DiT-MoE的采样脚本
- 🛸 使用PyTorch DDP和deepspeed的DiT-MoE训练脚本
- 🌋 校正流采样策略
待办事项
- 训练/推理脚本
- 专家路由分析
- huggingface检查点
1. 训练
您可以参考链接来构建运行环境。
要在一个节点上使用N个GPU通过pytorch DDP启动DiT-MoE-S/2(256x256)潜在空间训练:
torchrun --nnodes=1 --nproc_per_node=N train.py \
--model DiT-S/2 \
--num_experts 8 \
--num_experts_per_tok 2 \
--data-path /path/to/imagenet/train \
--image-size 256 \
--global-batch-size 256 \
--vae-path /path/to/vae
对于多节点训练,我们解决了原始DiT仓库中的bug,您可以使用8个节点运行:
torchrun --nnodes=8 \
--node_rank=0 \
--nproc_per_node=8 \
--master_addr="10.0.0.0" \
--master_port=1234 \
train.py \
--model DiT-B/2 \
--num_experts 8 \
--num_experts_per_tok 2 \
--global-batch-size 1024 \
--data-path /path/to/imagenet/train \
--vae-path /path/to/vae
对于更大模型规模的训练,我们推荐使用带有flash attention的deepspeed脚本,不同的阶段设置包括zero2和zero3可以在配置文件中查看。 您可以这样运行:
python -m torch.distributed.launch --nnodes=1 --nproc_per_node=8 train_deepspeed.py \
--deepspeed_config config/zero2.json \
--model DiT-XL/2 \
--num_experts 8 \
--num_experts_per_tok 2 \
--data-path /path/to/imagenet/train \
--vae-path /path/to/vae \
--train_batch_size 32
python -m torch.distributed.launch --nnodes=1 --nproc_per_node=8 train_deepspeed.py \
--deepspeed_config config/zero2.json \
--model DiT-XL/2 \
--rf True \
--num_experts 8 \
--num_experts_per_tok 2 \
--data-path /path/to/imagenet/train \
--vae-path /path/to/vae \
--train_batch_size 32
我们的实验表明,校正流训练可以带来更好的性能以及更快的收敛速度。
我们还在scripts文件夹中提供了不同模型规模训练的所有shell脚本。
2. 推理
我们包含了一个sample.py脚本,用于从DiT-MoE模型采样图像。请注意,我们对大型模型推理使用torch.float16。
python sample.py \
--model DiT-XL/2 \
--ckpt /path/to/model \
--vae-path /path/to/vae \
--image-size 256 \
--cfg-scale 1.5
3. 下载模型和数据
我们正在尽快处理,模型权重、数据和用于结果复现的脚本将在两周内持续发布 :)
我们使用了这个链接中的sd vae。
| DiT-MoE模型 | 图像分辨率 | 链接 | 脚本 | 损失曲线 |
|---|---|---|---|---|
| DiT-MoE-S/2-8E2A | 256x256 | 链接 | DDIM | - |
| DiT-MoE-S/2-16E2A | 256x256 | 链接 | DDIM | - |
| DiT-MoE-B/2-8E2A | 256x256 | 链接 | DDIM | - |
| DiT-MoE-XL/2-8E2A | 256x256 | 链接 | RF | - |
| DiT-MoE-G/2-16E2A | 512x512 | 链接 | RF | - |
4. 专家特化分析工具
我们提供了论文中使用的所有分析脚本。
您可以使用expert_data.py来跨不同类条件采样数据点对应的专家ID。
然后,一系列headmap_xx.py文件用于可视化不同场景下专家选择的频率。
通过调整采样数据的数量和保存路径,可以进行快速验证。
5. BibTeX
@article{FeiDiTMoE2024,
title={Scaling Diffusion Transformers to 16 Billion Parameters},
author={Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Jusnshi Huang},
year={2024},
journal={arXiv preprint},
}
6. 致谢
本代码库基于优秀的DiT和DeepSeek-MoE仓库。











