
EET简介
EET (Easy and Efficient Transformer) 是由网易伏羲人工智能实验室开发的一款开源推理加速工具。作为一个专注于Transformer类模型的PyTorch插件,EET的目标是让大规模模型的推理变得更加简单和高效。

EET的主要特点包括:
- 支持在单GPU上运行超大规模模型
- 专注于多模态和自然语言处理任务的推理加速(如CLIP、GPT-3、BERT、Seq2seq等)
- 通过CUDA内核优化和量化/稀疏算法实现高性能
- 与Transformers和Fairseq库无缝集成,使用简单方便
- 支持Baichuan、LLaMA等大语言模型
- 支持INT8量化
支持的模型
EET目前支持多种主流的Transformer类模型,包括但不限于:
- GPT-3
- BERT
- ALBert
- Roberta
- T5
- ViT
- CLIP (GPT+ViT)
- Distillbert
- Baichuan
- LLaMA
对于这些模型,EET提供了不同程度的加速和优化。例如,对于GPT-3模型,EET可以实现2-8倍的加速;对于BERT模型,可以实现1-5倍的加速。这些优化使得大规模模型的推理变得更加高效和实用。
快速开始
环境要求
为了使用EET,你需要满足以下环境要求:
- CUDA: 11.4或更高版本
- Python: 3.7或更高版本
- GCC: 7.4.0或更高版本
- PyTorch: 1.12.0或更高版本
- NumPy: 1.19.1或更高版本
- Fairseq: 0.10.0
- Transformers: 4.31.0或更高版本
安装
EET提供了两种安装方式:从源代码安装和使用Docker安装。推荐使用Docker镜像进行安装,这可以避免环境配置的麻烦。
从源代码安装
如果你选择从源代码安装,首先需要确保满足上述环境要求,然后按照以下步骤进行:
git clone https://github.com/NetEase-FuXi/EET.git
pip install .
使用Docker安装
使用Docker安装EET可以避免环境配置的问题。你可以按照以下步骤使用Docker安装EET:
git clone https://github.com/NetEase-FuXi/EET.git
docker build -t eet_docker:0.1 .
nvidia-docker run -it --net=host -v /your/project/directory/:/root/workspace eet_docker:0.1 bash
使用方法
EET提供了三种类型的API,分别是算子API、模型API和应用API。这三种API满足了不同层次的使用需求,从底层的自定义模型构建到高层的直接应用。
算子API
算子API是C++/CUDA和Python的中间表示。EET提供了几乎所有Transformer模型所需的算子。你可以组合不同的算子来构建其他模型结构。主要的算子包括:
- EETSelfAttention: 自注意力机制
- EETSelfMaskedAttention: 因果注意力机制
- EETCrossAttention: 交叉注意力机制
- EETFeedforward: 前馈网络
- EETBertEmbedding: 对应Fairseq和Transformers的嵌入层
- EETLayerNorm: 与nn.LayerNorm相同
模型API
作为插件,EET提供了友好的模型API,可以轻松集成到Fairseq和Transformers中。你只需要找到相应的类(通常以'EET'为前缀),并使用from_torch和from_pretrained函数初始化对象即可。
以下是EET与Transformers类的对比表:
| EET | Transformers | 备注 |
|---|---|---|
| EETBertModel | BertModel | |
| EETBertEmbedding | BertEmbeddings | |
| EETGPT2Model | GPT2Model | |
| EETGPT2Decoder | GPT2Model | Transformers没有GPT2Decoder |
| EETGPT2DecoderLayer | Block | |
| EETGPT2Attention | Attention | |
| EETGPT2Feedforward | MLP | |
| EETGPT2Embedding | nn.Embedding | |
| EETLayerNorm | nn.LayerNorm |
使用模型API的示例代码如下:
from eet import EETBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = EETBertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
应用API
EET提供了现成的pipeline方法,可以简化不同任务的应用构建过程。以下是一个使用pipeline进行掩码填充任务的例子:
import torch
from eet import pipeline
max_batch_size = 1
model_path = 'roberta-base'
data_type = torch.float16
input = ["My <mask> is Sarah and I live in London"]
nlp = pipeline("fill-mask", model=model_path, data_type=data_type, max_batch_size=max_batch_size)
out = nlp(input)
EET目前支持以下任务的pipeline:
- 文本分类
- 标记分类
- 问答
- 掩码填充
- 文本生成
- 图像分类
- 零样本图像分类
性能表现
EET在各种模型上都展现出了优秀的性能表现。以下是一些性能数据的展示:
GPT-3在A100上的性能
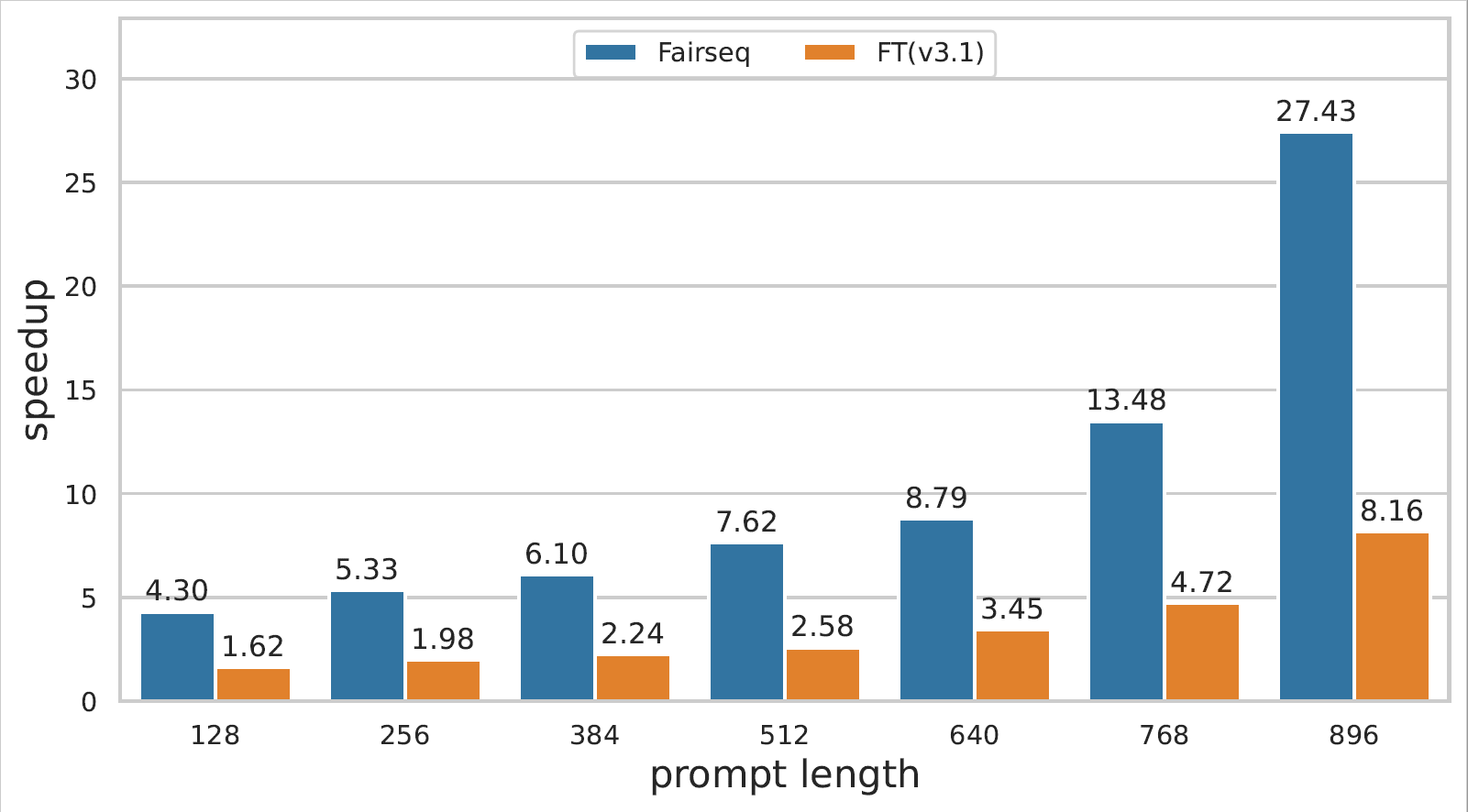
从图中可以看出,EET在不同的序列长度和批次大小下,都能显著提升GPT-3的推理速度。
BERT在2080Ti上的性能
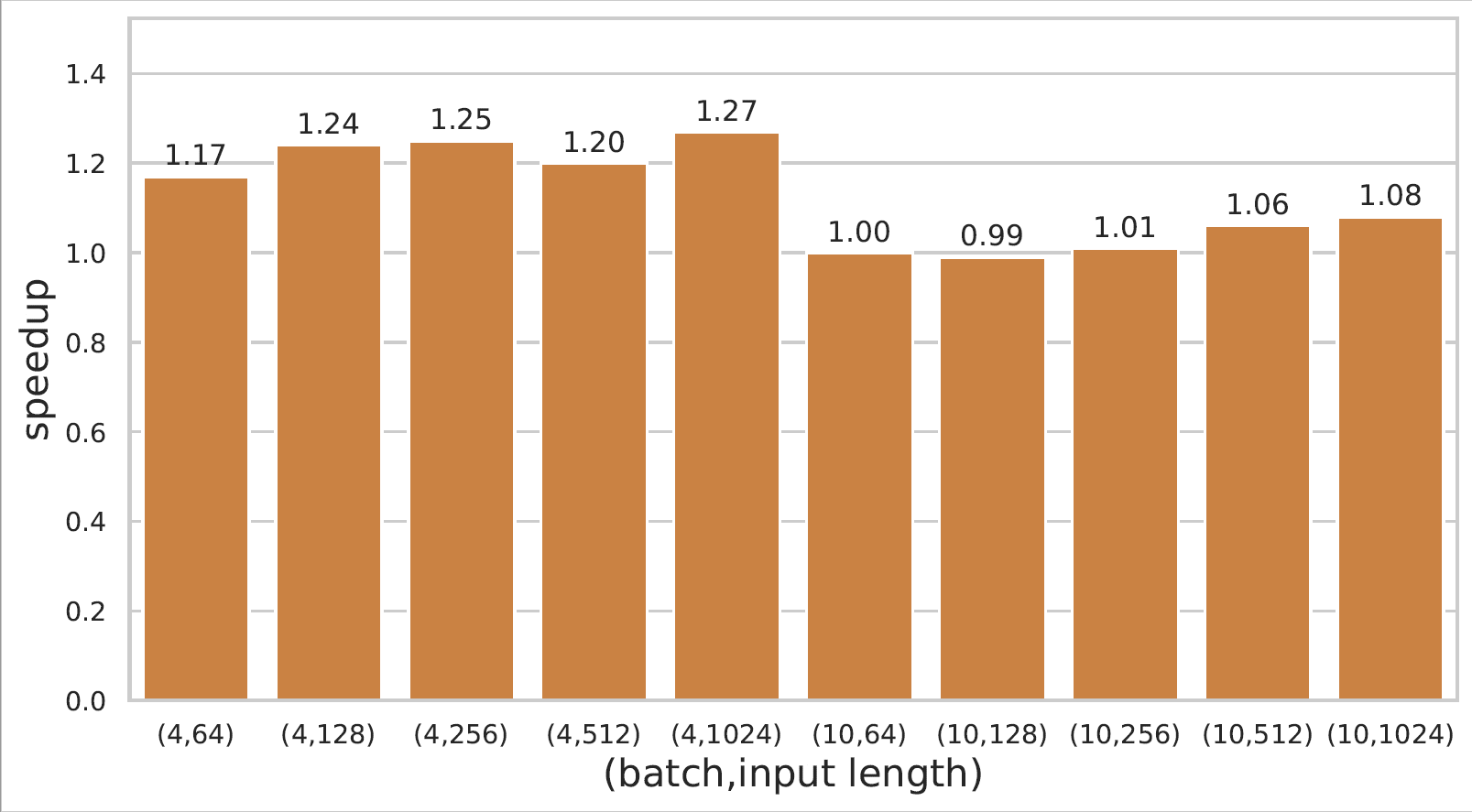
对于BERT模型,EET在不同的序列长度下都实现了显著的加速,尤其是在较长序列长度时,加速效果更加明显。
LLaMA 13B在3090上的性能
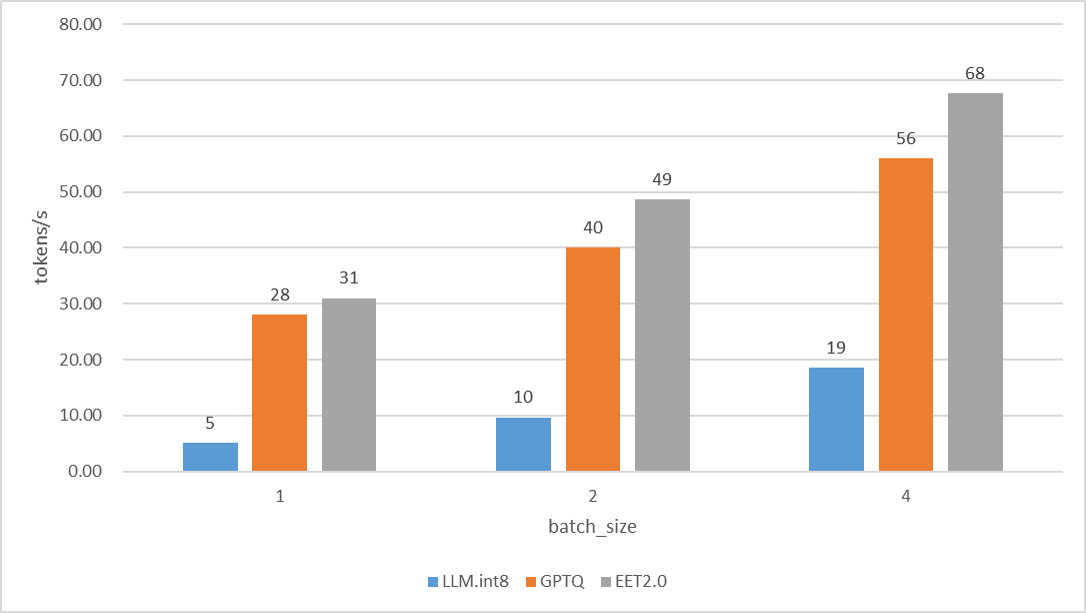
对于LLaMA 13B这样的大规模语言模型,EET同样展现出了优秀的性能提升。
总结
EET作为一款专注于Transformer类模型推理加速的工具,为大规模模型的应用提供了强有力的支持。它不仅支持多种主流模型,还提供了从底层到高层的多种API,满足不同场景下的使用需求。通过CUDA内核优化和量化/稀疏算法,EET实现了显著的性能提升,使得在有限的硬件资源下运行大规模模型成为可能。
对于研究人员和开发者来说,EET无疑是一个值得尝试的工具。它可以帮助你更高效地进行模型推理,节省时间和计算资源。同时,EET的开源性质也使得它具有良好的可扩展性和社区支持。
如果你在使用过程中遇到任何问题,可以通过GitHub issues或邮件与EET的开发团队联系。他们非常欢迎用户的反馈和建议,以不断改进EET的功能和性能。
总的来说,EET为Transformer类模型的推理加速提供了一个强大而灵活的解决方案。无论你是从事自然语言处理、计算机视觉还是多模态任务,EET都可能成为你工具箱中的一个有力武器。
🔗 更多信息和详细文档,请访问EET的GitHub仓库。









